
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

ものづくりの現場で、精密な計測器はないけど今すぐに音声を録音して周波数分析したい!さらにwavファイルに保存して後でゆっくり分析したい!というPython使いのための記事です。ここでは当ブログのコードを寄せ集めてこのようなニーズにマッチするプログラムを紹介します。
こんにちは。wat(@watlablog)です。ここではPCしかない状況を想定し、Pythonによる録音/周波数分析/wavファイル保存を行うためのコードを紹介します!
ちょっと録音して周波数分析したい状況
急に付近から異音が発生して原因を分析したい時
NVH(Noise-Vibration-Harshness)エンジニアは通常音振動の分析に専門の計測器とソフトウェアを使います。
小野測器さんやB&Kさんといった専門の機器とソフトを使う事で、信頼性の高い計測結果を得る事が可能ですが、一般にそれらを一式そろえるとかなり高額になってしまいます。
そのため専門の計測器は予約表を使ってシェアしている企業が多いのではないでしょうか。
そんな背景で仕事中に付近から異音が発生、すぐに原因を調査したい状況があった場合、いちいち計測器を予約して置き場まで取りに行ってからいざ計測しようと思ったら音が消えていた…という事にもなりかねません。
異音が周期的に鳴っている場合は周波数分析をする事で、熟練したエンジニアなら原因をすぐに特定する事が可能です。
デジタル化の進んできた現代であれば、社員1人1人にPCが渡されている企業も多いと思いますが、普通のPC1台で録音、周波数分析、証拠である音声ファイルの保存ができればこの状況に対応する事が可能です。
スマホが使えない時もある
スマホで録音してフーリエ変換すれば良いじゃん!
…と思いますが、機密情報を扱う企業であれば通常カメラ付き携帯やスマホの使用は業務利用禁止になっている場合が多いです。仕事中に持ち込みすらできない職場もあります。
このような状況でも信号処理プログラミングの知識があれば、すぐに録音や分析、ファイル保存ができます。
この記事ではプログラミングのハードルが比較的低いPythonを使って気軽に自分のPCで音声録音、周波数分析、音声ファイル(wavファイル)保存ができるようになる事を目標とします。
Python環境の準備
今回は以下の記事で紹介している内容を組み合わせたコードを書いています。それぞれの記事におけるコードが実行できる環境である事が前提です。
録音(PyAudio)
当ブログでは、以下の記事でPyAudioを使った録音コードを紹介しました。
PyAudioは録音関係でかなりデファクトスタンダードなライブラリですが、インストール時にエラーが発生しやすく、先の記事で紹介している方法を使って対応する必要があります。
フーリエ変換(Scipy)
また、「PythonでFFT実装!SciPyのフーリエ変換まとめ」や「ただPythonでcsvから離散フーリエ変換をするだけのコード」でフーリエ変換による周波数分析方法を紹介しました。
wavファイル保存(PySoundFile)
さらに、「Pythonでモノラルとステレオのwavファイルを保存する方法」という記事でwavファイルの保存に関する知見を得ました。
今回はこれらの記事をコラボして、冒頭で紹介しました状況に対応するコードを組み上げます。
PC1台で録音とフーリエ変換とwav保存を行うコード
全コード(コピペ用)
以下は全コードです。上で紹介した記事のコードが動く環境であれば、コピペ動作するはずです。
使い方は後述します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
import pyaudio import soundfile as sf import numpy as np from scipy import fftpack from matplotlib import pyplot as plt # 録音する関数 def record(index, samplerate, fs, time): pa = pyaudio.PyAudio() # デバイスリストを出力(マイクチャンネル確認用) for i in range(pa.get_device_count()): print(pa.get_device_info_by_index(i)) # ストリームの開始 data = [] dt = 1 / samplerate stream = pa.open(format=pyaudio.paInt16, channels=1, rate=samplerate, input=True, input_device_index=index, frames_per_buffer=fs) # フレームサイズ毎に音声を録音していくループ for i in range(int(((time / dt) / fs))): frame = stream.read(fs) data.append(frame) # ストリームの終了 stream.stop_stream() stream.close() pa.terminate() # データをまとめる処理 data = b"".join(data) # データをNumpy配列に変換/時間軸を作成 data = np.frombuffer(data, dtype="int16") / float((np.power(2, 16) / 2) - 1) t = np.arange(0, fs * (i + 1) * (1 / samplerate), 1 / samplerate) return data, t # フーリエ変換する関数(dB変換とA補正付き) def calc_fft(data, samplerate, dbref, A): spectrum = fftpack.fft(data) # 信号のフーリエ変換 amp = np.sqrt((spectrum.real ** 2) + (spectrum.imag ** 2)) # 振幅成分 amp = amp / (len(data) / 2) # 振幅成分の正規化(辻褄合わせ) phase = np.arctan2(spectrum.imag, spectrum.real) # 位相を計算 phase = np.degrees(phase) # 位相をラジアンから度に変換 freq = np.linspace(0, samplerate, len(data)) # 周波数軸を作成 # dbrefが0以上の時にdB変換する if dbref > 0: amp = 20 * np.log10(amp / dbref) # dB変換されていてAがTrueの時に聴感補正する if A == True: amp += aweightings(freq) return spectrum, amp, phase, freq #聴感補正(A特性カーブ) def aweightings(f): if f[0] == 0: f[0] = 1e-6 else: pass ra = (np.power(12194, 2) * np.power(f, 4)) / \ ((np.power(f, 2) + np.power(20.6, 2)) * \ np.sqrt((np.power(f, 2) + np.power(107.7, 2)) * \ (np.power(f, 2) + np.power(737.9, 2))) * \ (np.power(f, 2) + np.power(12194, 2))) a = 20 * np.log10(ra) + 2.00 return a # 計測条件を設定 time = 5 samplerate = 44100 fs = 1024 index = 2 # 録音する関数を実行 data, t = record(index, samplerate, fs, time) # wavファイルに保存する filename = 'recorded.wav' sf.write(filename, data, samplerate) # フーリエ変換する関数を実行 dbref = 2e-5 spectrum, amp, phase, freq = calc_fft(data, samplerate, dbref, True) # ここからグラフ描画 - ------------------------------------ # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure() ax1 = fig.add_subplot(211) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(212) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Time [s]') ax1.set_ylabel('Amplitude') ax2.set_xlabel('Frequency [Hz]') ax2.set_ylabel('Amplitude [dBA]') # スケールの設定をする。 ax2.set_xticks(np.arange(0, 25600, 1000)) ax2.set_xlim(0, 5000) ax2.set_ylim(np.max(amp) - 100, np.max(amp) + 10) # データプロット。 ax1.plot(t, data, label='Time waveform', lw=1, color='red') ax2.plot(freq, amp, label='Amplitude', lw=1, color='blue') # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- |
使い方
計測時間を変更する
録音する時の計測時間はtimeの値を変更します。単位は秒です。
|
1 |
time = 5 |
マイクチャンネルを設定する
マイクのチャンネルはindexで指定しますが、これはPCによって異なります。コードを実行すると、オーディオデバイスの一覧を表示させるようになっています。
もし録音デバイスのエラーが出る場合は、出力ウィンドウに表示されるメッセージを見てデバイス番号が正しいかを確認してみてください。
|
1 2 3 4 |
{'index': 0, 'structVersion': 2, 'name': '外部マイク', 'hostApi': 0, 'maxInputChannels': 1, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.004625, 'defaultLowOutputLatency': 0.01, 'defaultHighInputLatency': 0.013958333333333333, 'defaultHighOutputLatency': 0.1, 'defaultSampleRate': 48000.0} {'index': 1, 'structVersion': 2, 'name': '外部ヘッドフォン', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.01, 'defaultLowOutputLatency': 0.0045625, 'defaultHighInputLatency': 0.1, 'defaultHighOutputLatency': 0.013895833333333333, 'defaultSampleRate': 48000.0} {'index': 2, 'structVersion': 2, 'name': 'MacBook Proのマイク', 'hostApi': 0, 'maxInputChannels': 1, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.034520833333333334, 'defaultLowOutputLatency': 0.01, 'defaultHighInputLatency': 0.043854166666666666, 'defaultHighOutputLatency': 0.1, 'defaultSampleRate': 48000.0} {'index': 3, 'structVersion': 2, 'name': 'MacBook Proのスピーカー', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.01, 'defaultLowOutputLatency': 0.0070416666666666666, 'defaultHighInputLatency': 0.1, 'defaultHighOutputLatency': 0.016375, 'defaultSampleRate': 48000.0} |
wavファイル名を設定する
filenameを変更すると録音した後に保存されるwavファイルの名前を変える事ができます。
|
1 2 |
# wavファイルに保存する filename = 'recorded.wav' |
dB変換と聴感補正有無を変更する
周波数分析は以下の関数で行います。dbrefが0の時はdB変換と聴感補正を行いません。
今回はPCマイクを使って「音」を測定しているため、dB変換と聴感補正をデフォルトで行っていますが、もしdB変換は行いたいけど、聴感補正は行いたくないという場合は引数AをFalseにしてください。
|
1 2 |
# フーリエ変換する関数(dB変換とA補正付き) def calc_fft(data, samplerate, dbref, A): |
dB変換や聴感補正は以下の記事を参考にしてください。
「Pythonで音圧のデシベル(dB)変換式と逆変換式!」
「Pythonで聴感補正(A特性)の曲線を作る!」
実行結果
以下が実行結果です。時間波形と周波数波形がプロットされます。
いつも通り、口笛を吹いてみました。1000[Hz]を狙ったのですが、オシイ。
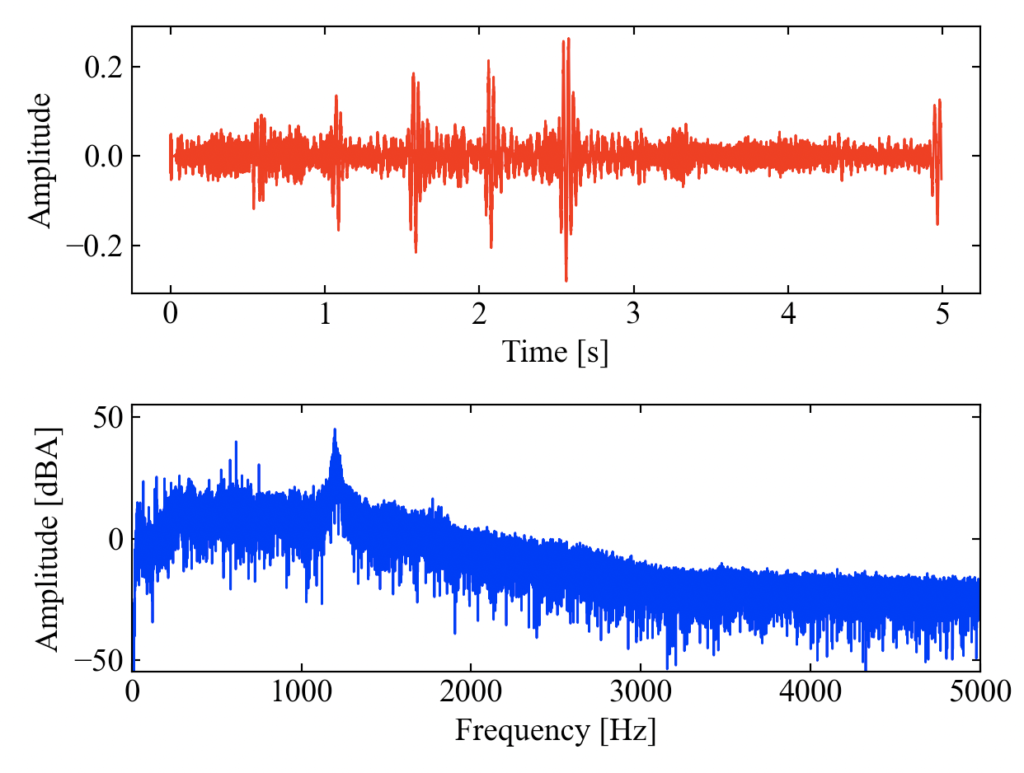
wavファイルも出来ているはずです。
ただ、インパルス信号が入ってしまうとwavファイルのレンジが大きくなってしまい、後で再生する時にほとんど音が聞こえなくなるかも知れません。
この辺はレンジを固定にする等の改善をした方が良いかも知れません。
追記:自動でマイクチャンネルを取得して録音するコード
「Python/PyAudioでマイクのチャンネルを確認する方法!」に自動でマイクチャンネルを取得するコードを追記しました。これにより手動でマイクを選択する必要がなくなります。
新たにget_mic_index()関数を作成し、index = get_mic_index()[0]で最初のマイクチャンネルを選択しています。もしマイクチャンネルが複数ある場合はユーザーに選択させる処理を別途追加すると良いかもしれません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 |
import pyaudio import soundfile as sf import numpy as np from scipy import fftpack from matplotlib import pyplot as plt def record(index, samplerate, fs, time): ''' 録音する関数 ''' pa = pyaudio.PyAudio() # ストリームの開始 data = [] dt = 1 / samplerate stream = pa.open(format=pyaudio.paInt16, channels=1, rate=samplerate, input=True, input_device_index=index, frames_per_buffer=fs) # フレームサイズ毎に音声を録音していくループ for i in range(int(((time / dt) / fs))): frame = stream.read(fs) data.append(frame) # ストリームの終了 stream.stop_stream() stream.close() pa.terminate() # データをまとめる処理 data = b"".join(data) # データをNumpy配列に変換/時間軸を作成 data = np.frombuffer(data, dtype="int16") / float((np.power(2, 16) / 2) - 1) t = np.arange(0, fs * (i + 1) * (1 / samplerate), 1 / samplerate) return data, t def get_mic_index(): ''' マイクチャンネルのindexをリストで取得する ''' # 最大入力チャンネル数が0でない項目をマイクチャンネルとしてリストに追加 pa = pyaudio.PyAudio() mic_list = [] for i in range(pa.get_device_count()): num_of_input_ch = pa.get_device_info_by_index(i)['maxInputChannels'] if num_of_input_ch != 0: mic_list.append(pa.get_device_info_by_index(i)['index']) return mic_list def calc_fft(data, samplerate, dbref, A): ''' フーリエ変換する関数(dB変換とA補正付き) ''' spectrum = fftpack.fft(data) # 信号のフーリエ変換 amp = np.sqrt((spectrum.real ** 2) + (spectrum.imag ** 2)) # 振幅成分 amp = amp / (len(data) / 2) # 振幅成分の正規化(辻褄合わせ) phase = np.arctan2(spectrum.imag, spectrum.real) # 位相を計算 phase = np.degrees(phase) # 位相をラジアンから度に変換 freq = np.linspace(0, samplerate, len(data)) # 周波数軸を作成 # dbrefが0以上の時にdB変換する if dbref > 0: amp = 20 * np.log10(amp / dbref) # dB変換されていてAがTrueの時に聴感補正する if A == True: amp += aweightings(freq) return spectrum, amp, phase, freq def aweightings(f): ''' 聴感補正(A特性カーブ) ''' if f[0] == 0: f[0] = 1e-6 else: pass ra = (np.power(12194, 2) * np.power(f, 4)) / \ ((np.power(f, 2) + np.power(20.6, 2)) * \ np.sqrt((np.power(f, 2) + np.power(107.7, 2)) * \ (np.power(f, 2) + np.power(737.9, 2))) * \ (np.power(f, 2) + np.power(12194, 2))) a = 20 * np.log10(ra) + 2.00 return a if __name__ == '__main__': # 計測条件を設定 time = 5 samplerate = 44100 fs = 1024 # マイクチャンネルを自動取得 index = get_mic_index()[0] # 録音する関数を実行 data, t = record(index, samplerate, fs, time) # wavファイルに保存する filename = 'recorded.wav' sf.write(filename, data, samplerate) # フーリエ変換する関数を実行 dbref = 2e-5 spectrum, amp, phase, freq = calc_fft(data, samplerate, dbref, True) # ここからグラフ描画 - ------------------------------------ # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure() ax1 = fig.add_subplot(211) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(212) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Time [s]') ax1.set_ylabel('Amplitude') ax2.set_xlabel('Frequency [Hz]') ax2.set_ylabel('Amplitude [dBA]') # スケールの設定をする。 ax2.set_xticks(np.arange(0, 25600, 1000)) ax2.set_xlim(0, 5000) ax2.set_ylim(np.max(amp) - 100, np.max(amp) + 10) # データプロット。 ax1.plot(t, data, label='Time waveform', lw=1, color='red') ax2.plot(freq, amp, label='Amplitude', lw=1, color='blue') # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- |
まとめ
この記事では、PyAudioによる録音、Scipyによるフーリエ変換、PySoundFileによるwav保存をまとめてみました。
これでちょっと思い立った時に、高価な測定器を予約しなくてもとりあえずの音声分析ができるようになりました。
もちろんここで紹介しているコードによる音声分析結果は、
- 音響校正されていない。
- アンチエリアジングフィルタが付いていない。
- PCマイクの素性がよくわからない。
…といった事から信頼性がとても低い事に注意してください。
正式なデータはしっかり定期点検されている専門機器で測定しましょう。
間に合わせ程度ですが、PCマイクによる録音を活用してみました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!