
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Pythonを使ってPCのマイク入力から音声を入力するプログラムはPyAudioを使って簡単に書くことができます。ここでは実際の音をデジタルデータへ変換する際の注意点を踏まえてサンプルコードを示します。
こんにちは。wat(@watlablog)です。
信号処理プログラマを目指すとしたら簡単に録音くらい朝飯前になりたいですね。ここではPyAudioを使って音声信号を取得します!
Pythonプログラミングの基本文法や問題解決には体系的な学習プログラムが効果的です。手っ取り早く基礎を覚えるために僕は「PyQ(パイキュー)」に登録してみました。気になる方は「PyQでPython学習!実際に登録してみた感想と気になる料金」という記事を参照下さい!

PyAudioインストールの注意点
Windows版のインストールについて
筆者の環境はPython3.7を使っていますが、2019年6月現在はインストール時にエラーが発生するようです。詳細は「Python3.7でPyAudioがインストールできない時の解決法」の記事を確認して頂ければと思います。
Python3.9や3.11では特に問題ないようです。
Mac版のインストールについて
このページはWindowsPCで主に書きましたが、Macでも動きます。筆者のMacによる環境は「macOSにPython3をインストールする方法をまとめてみた」で構築した通りですが、MacでPyAudioを使う場合、ターミナルで、
「brew install portaudio」
…を実行した後に、
「pip3 install pyaudio」
…で問題無くインストール可能でした。
録音に使用する機材
これからPythonプログラムを使って録音のプログラムを書きますが、不幸な事に僕のPCに初期から付いていた内蔵マイクが壊れてしまっていたので、このページではUSBマイクを使って例を紹介します。
USBマイクであっても、プログラム自体は何も変化することはありません!それでは、早速コードを書いていきましょう!
Python/PyAudioで録音するコード
今回は「習うより慣れろ!」ということで、コードを書きながら内容を説明していきたいと思います。
インポートするパッケージ
今回使うライブラリパッケージは、音声録音をするためのpyaudio, 配列処理のnumpy, グラフ表示のmatplotlibです。
|
1 2 3 |
import pyaudio import numpy as np from matplotlib import pyplot as plt |
設定する値
計測のための設定は以下のコードです。
計測時間は全体で何秒録音するか、サンプリングレートは1秒間に収集するデータの個数です。
データは1つずつ収集するのではなく、フレーム単位で収集します。そのためそのフレームのサイズを指定します(この値は2のべき乗(512, 1024, 2048...等))。
マイクのチャンネル指標とは、PCの何番目のチャンネルが録音用のデバイスかを指定するものです。この番号はオーディオインデックスの番号と呼び、「Python/PyAudioでマイクのチャンネルを確認する方法!」で記載した方法で調べることができます。
|
1 2 3 4 |
time = 1 # 計測時間[s] samplerate = 44100 # サンプリングレート fs = 1024 # フレームサイズ index = 1 # マイクのチャンネル指標 |
録音の関数
それではここでメインの録音関数を説明します。
以下のコードが録音関数です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def record(index, samplerate, fs, time): pa = pyaudio.PyAudio() data = [] dt = 1 / samplerate # ストリームの開始 stream = pa.open(format=pyaudio.paInt16, channels=1, rate=samplerate, input=True, input_device_index=index, frames_per_buffer=fs) # フレームサイズ毎に音声を録音していくループ for i in range(int(((time / dt) / fs))): frame = stream.read(fs) data.append(frame) # ストリームの終了 stream.stop_stream() stream.close() pa.terminate() # データをまとめる処理 data = b"".join(data) # データをNumpy配列に変換 data = np.frombuffer(data, dtype="int16") / float((np.power(2, 16) / 2) - 1) return data, i |
ストリームとは、ストリーミング動画等に代表されるように「流れ」を意味する単語ですが、PCのサウンドデバイスが準備開始する、というイメージで構わないと思います。
「format=pyaudio.paInt16」は16bitの量子化ビット数でデータを収集するという意味で、後程後述します。
このサンプルコードでは1チャンネルのモノラル録音をしています。
「int(((time / dt) / fs))」の部分は、計測時間timeを指定しましたが、結局はフレーム単位で録音をするため、フレームの整数倍でデータを収集するためのループ回数計算が必要なため、そのループ回数を計算しています。
dataはリスト型で、さらに「b'\xfd\xff\xfa…'」といったデータで作られていますが、リストの中身の、さらにb''の中身の文字列を連結させるために「b''''.join(data)」と.join関数を使います。
「np.frombuffer」部分では、データをNumpy配列に変換し、数値として扱えるように変換するものですが、これがちょっとわかりにくいかも知れませんので、図解を作りました。
但し、今回僕がこのコードを作るために勉強して理解した内容であるため、もしかしたら間違いがあるかも知れません。ご利用には細心の注意をお願いします。
以下の図はPyaudioで録音したデータ構造のイメージを示しています。
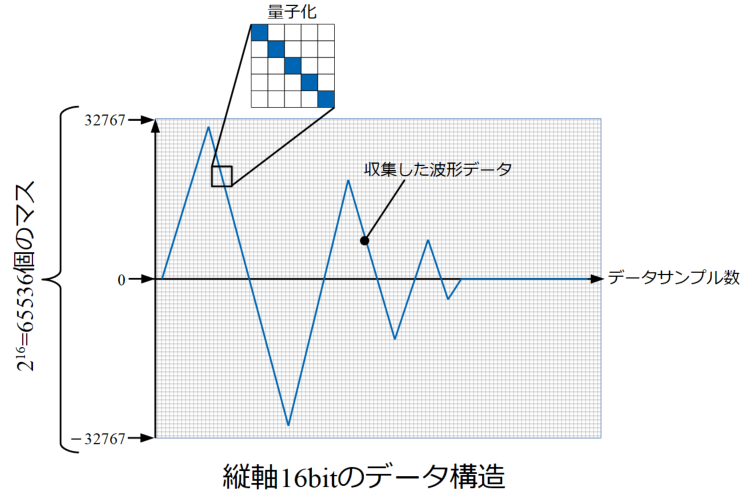
コンピュータはアナログな連続した値を扱えないので、図中に描いたようなマス目に録音したデータを格納していくことをやっています。
横軸はデータサンプル数で、フレームサイズ単位でループ数に応じて増えていくマスです。
一方縦軸はデータの物理値の量を示す軸ですが、コンピュータは音を測定するからといって音圧[Pa]を直接計測することができません。
本ページでは16bitの量子化ビット数で録音していると先に書きましたが、このビット数によって縦軸のマスの個数が決まると認識しています。
量子化についてもっと詳しく
コンピュータは連続した値を扱えず、ビット数に応じたマスにデータを格納して行きます。
今回は縦軸が16bitなので、表現できる値の数は\(2^{16}\)です。
\(2^{16}\)は65536個のマスを用意できることを意味しますが、音圧のデータは正の値もあれば負の値もあり、さらには0も表現する必要があります。
正負両方の値を表現するためには割る2をしなければいけません。\(2^{16}\)の半分は65536/2=32768となりますが、0をとる必要があるので、32768-1=32767が最大値と最小値になります。
そのため上図は0を中心として±32767の範囲にデータが入ることになります。
ここまでが、「/ float((np.power(2, 16) / 2) - 1) 」としている理由になります。
関数の実行とグラフプロット
ここまでできたら、あとは関数を実行し、グラフにプロットするだけです。
以下のコードのwfmが波形(Waveform)を格納する変数で、先ほど作った関数を実行する部分です。
グラフの横軸tを計算するために、関数内のforループ回数iも取得しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
wfm, i = record(index, samplerate, fs, time) t = np.arange(0, fs * (i+1) * (1 / samplerate), 1 / samplerate) # ここからグラフ描画 # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure() ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Time [s]') ax1.set_ylabel('Sound pressure [Pa]') # データプロットの準備とともに、ラベルと線の太さ、凡例の設置を行う。 ax1.plot(t, wfm, label='signal', lw=1) fig.tight_layout() # グラフを表示する。 plt.show() plt.close() |
実行結果
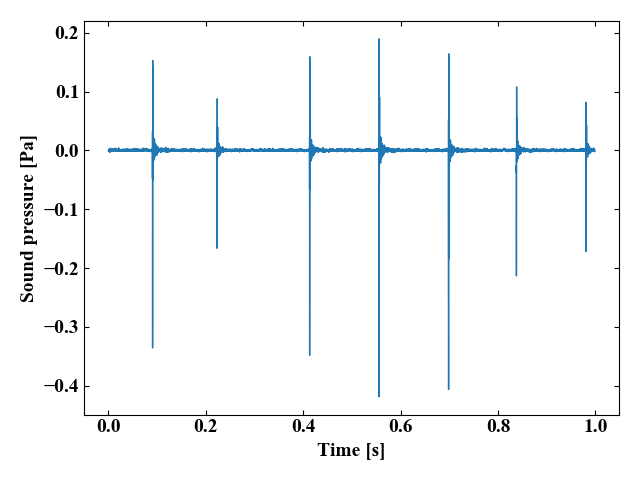
以下の図が実行結果になります。
これはマイクをテーブルに7回叩きつけた時の音です。綺麗な音圧の減衰自由振動が観測できていますね。
おまけ:マイクチャンネルを自動で取得して録音するPythonコード【コピペでそのまま動作可】
こちらはおまけです。コピペでそのまま動作するようにしてみました。また、所々関数化してコンパクトにしたり、マイクチャンネルを自動取得するコードも追記しています。
詳細は「Python/PyAudioでマイクのチャンネルを確認する方法!」に自動でマイクチャンネルを取得するコードを追記しましたので確認ください。これにより手動でマイクを選択する必要がなくなります。
新たにget_mic_index()関数を作成し、index = get_mic_index()[0]で最初のマイクチャンネルを選択しています。もしマイクチャンネルが複数ある場合はユーザーに選択させる処理を別途追加すると良いかもしれません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
import pyaudio import numpy as np from matplotlib import pyplot as plt def record(index, samplerate, fs, time): ''' 録音する関数 ''' pa = pyaudio.PyAudio() # ストリームの開始 data = [] dt = 1 / samplerate stream = pa.open(format=pyaudio.paInt16, channels=1, rate=samplerate, input=True, input_device_index=index, frames_per_buffer=fs) # フレームサイズ毎に音声を録音していくループ for i in range(int(((time / dt) / fs))): frame = stream.read(fs) data.append(frame) # ストリームの終了 stream.stop_stream() stream.close() pa.terminate() # データをまとめる処理 data = b"".join(data) # データをNumpy配列に変換/時間軸を作成 data = np.frombuffer(data, dtype="int16") / float((np.power(2, 16) / 2) - 1) t = np.arange(0, fs * (i + 1) * (1 / samplerate), 1 / samplerate) return data, t def get_mic_index(): ''' マイクチャンネルのindexをリストで取得する ''' # 最大入力チャンネル数が0でない項目をマイクチャンネルとしてリストに追加 pa = pyaudio.PyAudio() mic_list = [] for i in range(pa.get_device_count()): num_of_input_ch = pa.get_device_info_by_index(i)['maxInputChannels'] if num_of_input_ch != 0: mic_list.append(pa.get_device_info_by_index(i)['index']) return mic_list def plot(t, x, label, xlabel, ylabel, figsize, xlim, ylim, xlog, ylog): ''' 汎用プロット関数(1プロット重ね書き) ''' # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # Subplot設定とグラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=figsize) ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel(xlabel) ax1.set_ylabel(ylabel) # スケールを設定する。 if xlim != [0, 0]: ax1.set_xlim(xlim[0], xlim[1]) if ylim != [0, 0]: ax1.set_ylim(ylim[0], ylim[1]) # 対数スケール if xlog == 1: ax1.set_xscale('log') if ylog == 1: ax1.set_yscale('log') # プロットを行う。 for i in range(len(x)): ax1.plot(t[i], x[i], label=label[i], lw=1) ax1.legend() # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() return if __name__ == '__main__': # 計測条件を設定 time = 5 samplerate = 44100 fs = 1024 # マイクチャンネルを自動取得 index = get_mic_index()[0] # 録音する関数を実行 data, t = record(index, samplerate, fs, time) # 波形確認 plot([t], [data], ['recorded'], 'Time [s]', 'Amplitude', (8, 4), [0, 0], [0, 0], 0, 0) |
さらに、音声をスケーリングする方法も検討してみました。以下のコードを上記全コードに組み込み、dataを変換すれば波形の絶対値の最大値を使ってスケーリングすることが可能です。これはwavファイルにするとき等に音が小さくならないようにすることができます。
|
1 2 3 4 5 6 7 8 9 10 11 |
def scaling(wave): """ 音声データを絶対値の最大値をフルレンジにするようスケーリングする """ # 絶対値波形から最大値を取得 wave_abs = np.abs(wave) wave_max = np.max(wave_abs) # スケーリング wave_norm = wave * (1 / wave_max) return wave_norm |
また、フーリエ変換やwav保存まで一度にできるコードは以下の記事に記載しました。是非ご参考ください。
現場でPC1つ!簡単に録音・FFT・wav保存するPythonコード
まとめ
本ページではPyAudioを使って音声を取得するコードを紹介しました。
ただサンプルコードを紹介するだけでは(僕自身が)理解に苦しんだので、量子化ビット数やデータ構造等の勉強結果も図にしてみました。
以外と録音には専門用語が沢山あって慣れない操作が多かったけど、なんとかデータを自分のPCで収集することができたぞ!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント