
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

scikit-learnではpickleを使って学習済のモデルを保存したり読み込んだりできていましたが、PyTorchのモデルが読み込めない問題に直面したので解決方法をメモします。ここでは最も簡単だと感じたcloudpickleを使った方法を紹介します。
こんにちは。wat(@watlablog)です。PyTorchで学習したモデルを再利用する時にハマったので、解決方法をメモします!
PyTorchのモデルをpickleで再利用しようとした時のエラー
エラー発生時の状況とエラーメッセージ
pickleを使った保存(シリアライズ)と読み込み(デシリアライズ)のコードは以下の通りです。
|
1 2 3 4 5 6 7 |
# ネットワークモデルをシリアライズしてファイルに保存 with open('network01.pt', mode='wb') as f: pickle.dump(net, f) # ファイルからネットワークモデルをデシリアライズして読み込み with open('network01.pt', mode='rb') as f: net = pickle.load(f) |
このコードを使ってPyTorchで学習したモデルを保存・読み込みすると、読み込み時に以下のエラーが出ます。今回は回帰モデルを使っていたので「Regression」属性が取得できないと言われているようです。
net = pickle.load(f)
エラー内容
AttributeError: Can't get attribute 'Regression' on <module 'main' from '…
どうやら公式ドキュメントによると、PyTorchのテンソルオブジェクトはtorch.saveやtorch.loadを使うそうです。さらに、state_dict()を使う方法が推奨されているようです。おそらくこの辺を理解して使うのが王道でしょう。
Instead of saving a module directly, for compatibility reasons it is recommended to instead save only its state dict. Python modules even have a function,
SERIALIZATION SEMANTICSload_state_dict(), to restore their states from a state dict:
しかし、自分の理解がまだ曖昧で、うまく行かない場合がありました。そんな中、簡単に成功したのがcloudpickleでした。
pickleとcloudpickleについて
pickle
そもそもpickleとは、Python標準のライブラリの一つで、オブジェクトの保存と読み込みを行う事ができるものです。
pickleについては「Python機械学習済モデルをpickleで保存して復元する方法」という記事で使い方を説明していますので是非ご覧ください。
この記事ではscikit-learnという古典的な機械学習アルゴリズム(決定木やサポートベクターマシン等)がまとめられたライブラリを使ってモデルの保存をしていました。
cloudpickle
cloudpickleはPython標準ライブラリのpickleでサポートしていない構造体をシリアライズする目的で開発されたそうです。
公式としては以下のGithubページが見つかりました。全く同じバージョンのPython間でモデルをやりとりをする事のみに使えるという事と、信頼できるソースからのモデル以外を使うとセキュリティ上危険という事が注意点でしょうか。
cloudpickle makes it possible to serialize Python constructs not supported by the default pickle module from the Python standard library.
Github:cloudpickle
cloudpickle is especially useful for cluster computing where Python code is shipped over the network to execute on remote hosts, possibly close to the data.
Among other things, cloudpickle supports pickling for lambda functions along with functions and classes defined interactively in the main module (for instance in a script, a shell or a Jupyter notebook).
Cloudpickle can only be used to send objects between the exact same version of Python.
Using cloudpickle for long-term object storage is not supported and strongly discouraged.
Security notice: one should only load pickle data from trusted sources as otherwise pickle.load can lead to arbitrary code execution resulting in a critical security vulnerability.
僕のように自分のコンピュータのみでモデルを再利用したいという目的にはちょうど良いかも知れませんが、複数人、複数環境で開発をしている人にはちょっと向かないかもですね。
cloudpickleでPyTorchのネットワークモデルを保存・再利用するコード
トレーニングモデルを保存するコード例
以下にモデルを保存するコード例を示します。コピペで動作するはずです。主要部分は「cloudpickle.save」の部分ですが、コード全体の意味を知りたい方は「PyTorchで色々な非線形関数を回帰してみたらすごかった」をご覧ください。
他にも「PyTorchのネットワークモデルを使って線形回帰をする方法」、「PyTorchのネットワークモデルをクラスで書く時のメモ」を見る事でPyTorchによる回帰について参考になると思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
import torch from torch import nn, optim import numpy as np from matplotlib import pyplot as plt import cloudpickle # 線形回帰ネットワークのclassをnn.Moduleの継承で定義 class Regression(nn.Module): # コンストラクタ(インスタンス生成時の初期化) def __init__(self): super().__init__() self.linear1 = nn.Linear(3, 32) self.linear2 = nn.Linear(32, 32) self.linear3 = nn.Linear(32, 16) self.linear4 = nn.Linear(16, 1) # メソッド(ネットワークをシーケンシャルに定義) def forward(self, x): x = nn.functional.relu(self.linear1(x)) x = nn.functional.relu(self.linear2(x)) x = nn.functional.relu(self.linear3(x)) x = self.linear4(x) return x # トレーニング関数 def train(model, optimizer, E, iteration, x, y): # 学習ループ losses = [] for i in range(iteration): optimizer.zero_grad() # 勾配情報を0に初期化 y_pred = model(x) # 予測 loss = E(y_pred.reshape(y.shape), y) # 損失を計算(shapeを揃える) loss.backward() # 勾配の計算 optimizer.step() # 勾配の更新 losses.append(loss.item()) # 損失値の蓄積 print('epoch=', i+1, 'loss=', loss) #グラフ描画用にXY軸とグリッドを作成 X1 = np.arange(-10, 11, 0.5) X2 = np.arange(-10, 11, 0.5) X, Y = np.meshgrid(X1, X2) # データをテンソルに変換(切片用の定数1も結合) X2 = torch.from_numpy(X.ravel().astype(np.float32)).float() Y2 = torch.from_numpy(Y.ravel().astype(np.float32)).float() Input = torch.stack([torch.ones(len(X.ravel())), X2, Y2], 1) # 最終結果をプロットして確認 if (i + 1) == iteration: Z = test(model, Input).reshape(X.shape) plot_3d(x.T[1], x.T[2], y, X, Y, Z, losses) return model, losses # テスト def test(model, x): y_pred = model(x).data.numpy() return y_pred # グラフ描画関数 def plot_3d(x1, x2, z, X, Y, Z, losses): # ここからグラフ描画------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(9, 4)) ax1 = fig.add_subplot(121, projection='3d') ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(122) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('x1') ax1.set_ylabel('x2') ax1.set_zlabel('y') ax2.set_xlabel('Iteration') ax2.set_ylabel('E') # スケール設定 ax1.set_xlim(-10, 10) ax1.set_ylim(-10, 10) ax1.set_zlim(0, 100) ax2.set_xlim(0, 10000) ax2.set_ylim(1, 2000) ax2.set_yscale('log') # データプロット ax1.scatter3D(x1, x2, z, label='dataset') ax1.plot_surface(X, Y, Z, cmap='jet') ax2.plot(np.arange(0, len(losses), 1), losses) ax2.scatter(len(losses), losses[len(losses) - 1], color='red') ax2.text(600, 3, 'Loss=' + str(round(losses[len(losses)-1], 2)), fontsize=16) ax2.text(600, 5, 'Iteration=' + str(round(len(losses), 1)), fontsize=16) # グラフを表示する。 ax1.legend(bbox_to_anchor=(0, 1), loc='upper left') fig.tight_layout() plt.show() plt.close() # ------------------------------------------------------------------- # トレーニングデータ x1 = np.random.uniform(-10, 10, 100) # ノイズを含んだx軸を作成 x2 = np.random.uniform(-10, 10, 100) # ノイズを含んだy軸を作成 grid_x, grid_y = np.meshgrid(x1, x2) # Gridデータを作成 # ノイズを含んだ平面点列データを作成 z1 = (1/2) * (grid_x.ravel() ** 2 + grid_y.ravel() ** 2) z2 = -10 * np.cos(grid_x.ravel()) * np.cos(grid_y.ravel()) z = z1 + z2 grid_x = torch.from_numpy(grid_x.ravel().astype(np.float32)).float() # grid_xをテンソルに変換 grid_y = torch.from_numpy(grid_y.ravel().astype(np.float32)).float() # grid_yをテンソルに変換 z = torch.from_numpy(z.astype(np.float32)).float() # yをテンソルに変換 X = torch.stack([torch.ones(len(grid_x)), grid_x, grid_y], 1) # xに切片用の定数1配列を結合 # ネットワークのインスタンスを生成 net = Regression() # 最適化アルゴリズム(RMSProp)と損失関数(MSE)を設定 optimizer = optim.RMSprop(net.parameters(), lr=0.01) E = nn.MSELoss() # トレーニング net, losses = train(model=net, optimizer=optimizer, E=E, iteration=10000, x=X, y=z) # ネットワークモデルをシリアライズしてファイルに保存 with open('model.pt', mode='wb') as f: cloudpickle.dump(net, f) |
上記コードを実行する事で、10000回の学習の後にmodel.ptが作成されます。
※.ptの拡張子は任意です。PyTorchのデータは慣例から.ptがよく使われると聞いた事があるために付けています。
コードを実行すると、model.ptが作成される他に以下のプロットも表示されます。ご参考。
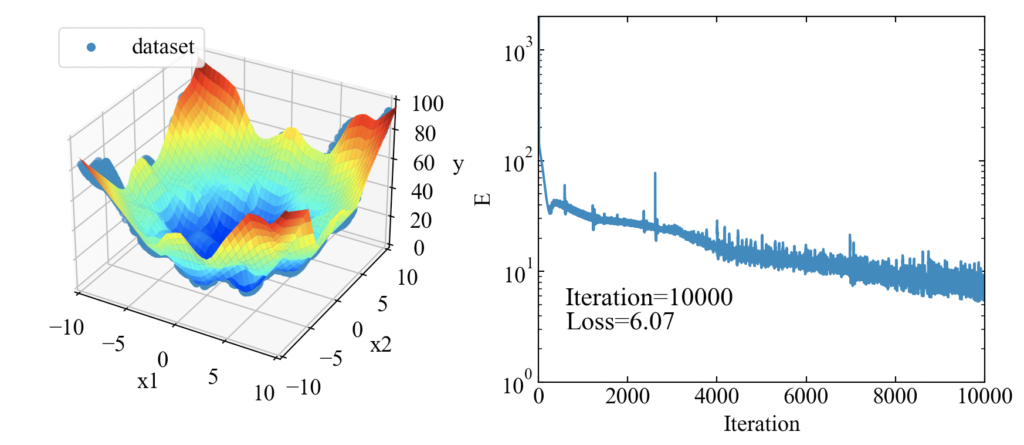
保存されたトレーニングモデルを読み込んで再利用するコード例
そして以下のコードで、作成されたmodel.ptを読み込んで使う事が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import cloudpickle import numpy as np import torch from matplotlib import pyplot as plt # ファイルからネットワークモデルをデシリアライズして読み込み with open('model.pt', mode='rb') as f: net = cloudpickle.load(f) # グラフ描画用にXY軸とグリッドを作成 X1 = np.arange(-10, 11, 0.5) X2 = np.arange(-10, 11, 0.5) X, Y = np.meshgrid(X1, X2) # データをテンソルに変換(切片用の定数1も結合) X2 = torch.from_numpy(X.ravel().astype(np.float32)).float() Y2 = torch.from_numpy(Y.ravel().astype(np.float32)).float() Input = torch.stack([torch.ones(len(X.ravel())), X2, Y2], 1) # ネットワークモデルから応答を計算 z_pred = net(Input).data.numpy().reshape(X.shape) # ここからグラフ描画------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(9, 4)) ax1 = fig.add_subplot(111, projection='3d') ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('x1') ax1.set_ylabel('x2') ax1.set_zlabel('y') # スケール設定 ax1.set_xlim(-10, 10) ax1.set_ylim(-10, 10) ax1.set_zlim(0, 100) # データプロット ax1.plot_surface(X, Y, z_pred, cmap='jet') # グラフを表示する。 fig.tight_layout() plt.show() plt.close() |
cloudpickle.loadで読み込んでいるだけですが、データを入力するだけでしっかりとモデルの応答曲面が計算されました。
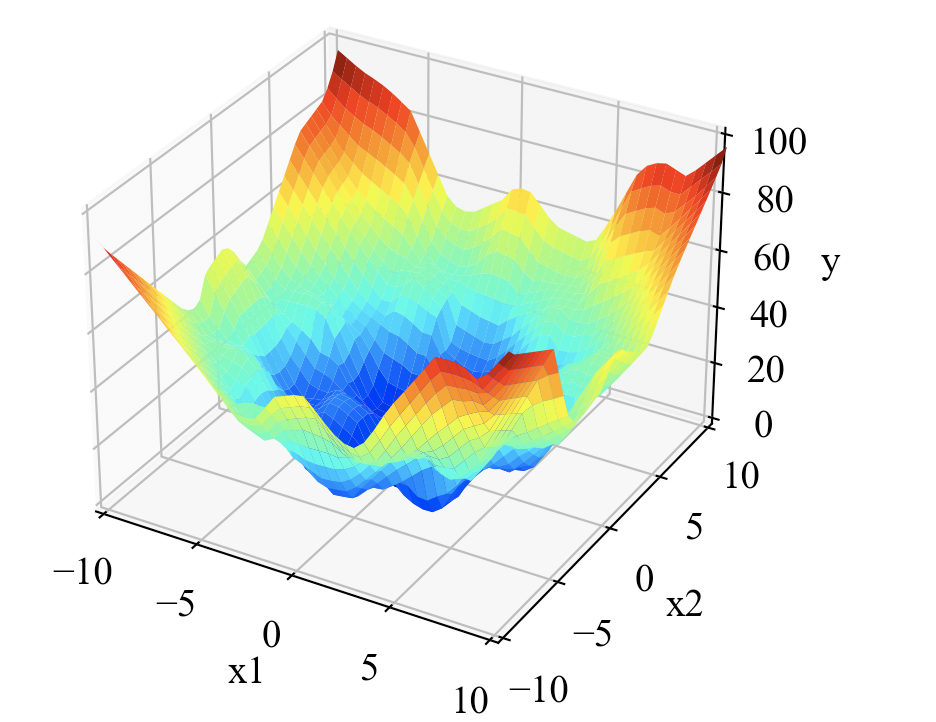
まとめ
今回はショートTips的な記事で、pickleで発生したエラーを解決するためにcloudpickleを紹介しました。
Pythonのバージョンを揃えるといった注意点はありますが、自分のPCで学習したモデルを使う場合には問題ないと思います。
Google ColaboratoryやGPU環境で学習したモデルを自分のPCで再利用…とかはもう少し調査をするか、素直にtorch.saveに慣れるのが良いかも知れません。
注意点に気をつければcloudpickleはすごく使いやすいです!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!