
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

日本語のテキストと音声を音素レベルで対応をとる強制アライメントツールpydominoを使ってみました。pydominoのインストールから使い方、音素対応表の紹介を行っています。また、実際に母音や子音を含む音声データを波形やスペクトログラムで可視化しながら結果の検証を行いました。
はじめに
音素と強制アライメントについて
音素(Phoname)とは、言語の音声を構成する基本単位であり、単語の意味を区別する最小単位です。例えば「さかな(魚)」と「たかな(高菜)」は最初の文字の違いが意味の違いを生んでいます。この「さ」と「た」はそれぞれ異なる音素です。英語でも「Right」と「Light」は似ていますが、最初の音素「R」と「L」の違いで意味が異なります。つまり音素とは、単なる音の違いというよりも意味を区別できる音の違い、と捉えた方が良いでしょう。
強制アライメント(Forced Alignment)とは、音声データの中で、音素とその書き起こしテキストを時間軸上で正確に対応付ける処理のことです。
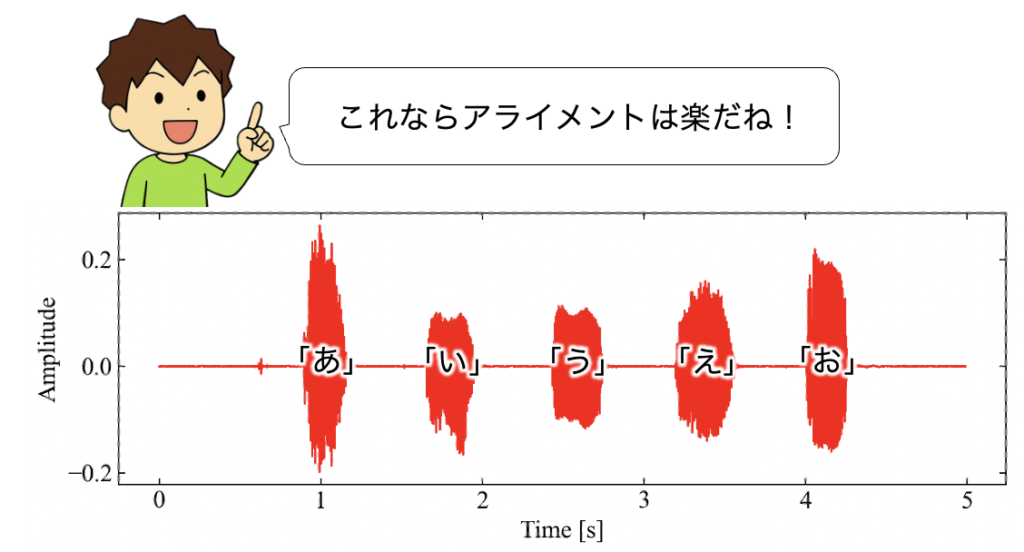
アライメントの例を簡単に説明しましょう。例えば次の図のように、「あいうえお」という言葉を音素毎に区切って発話した場合、無音区間と音素の有音区間が明確になっています。このような場合は信号処理のアルゴリズムだけを使って(無音区間を削除して有音区間だけを抽出)アライメントが可能です。
しかし、実際の発話で音素毎に区切って発話されるなんてことはなく、リアルワールドデータは次のような形になります。これだとどこで音素が区切られているかを信号処理のアルゴリズムだけで特定するのは困難(というか無理?)です。
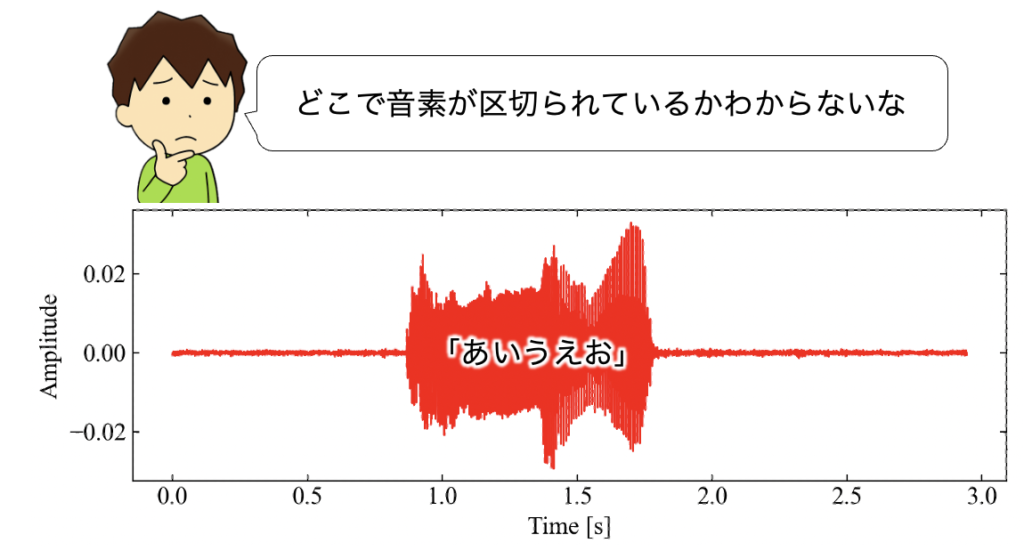
このような複雑なデータの場合、従来は人間が音を聞きながら手動でラベリングしていました。◯秒〜◯秒は◯の音素というように、明確に音素とデータの対応をとることをハードアライメント(Hard Alignment)と呼びます。精度の良いデータのためとはいえ、ハードアライメントを手動で行うのはなかなかに骨の折れる作業です…。
pydominoとは
pydominoはDwango Media Villageで開発された日本語音素アライメントツールです。Pythonやコマンドラインツールから使うことができ、MITライセンスのためいくつかの条件(著作権表示とライセンス条文の記載等)を遵守すれば商用利用等幅広く使うことができます。詳細は以下のリンクをご確認ください。
・GitHub:https://github.com/DwangoMediaVillage/pydomino
・DWANGO MEDIA VILLAGE公式:https://dmv.nico/ja/articles/domino_phoneme_transition/
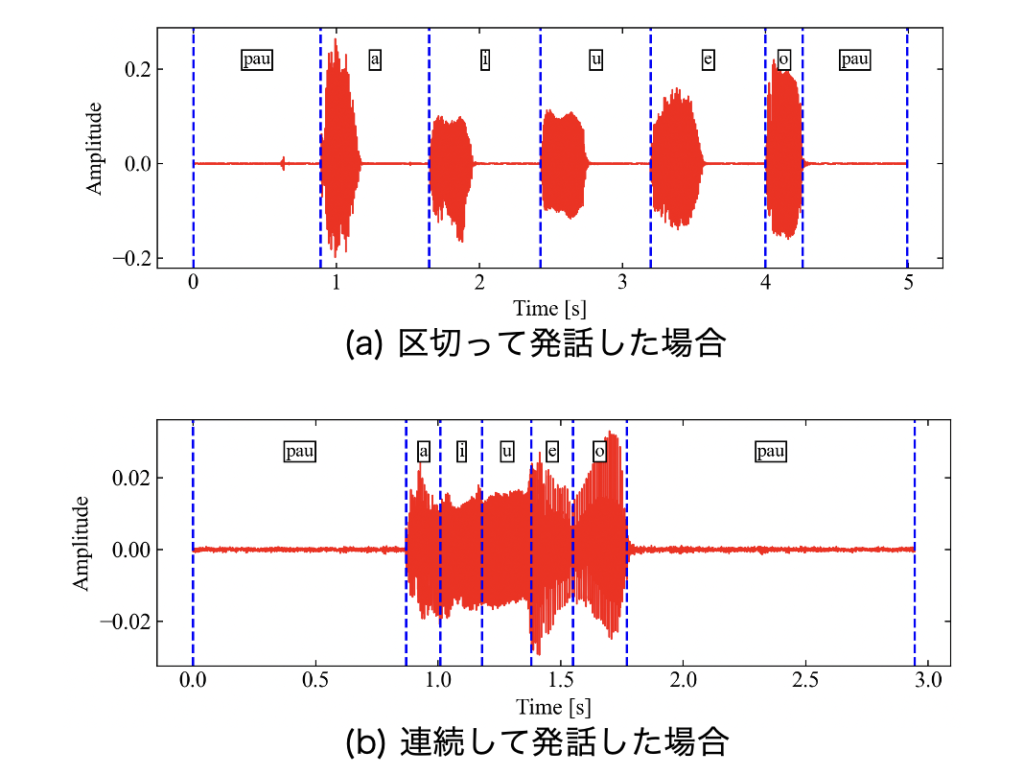
pydominoを使えば先ほどの区切り発話と連続発話のデータ両方で音素をハードアライメントすることができます(スゴイ!)。この記事ではGitHubのコードや公式の記事を参考にしながら、pydominoの使い方を学びます。
これから紹介するpydominoは2025年3月4日に公開された公式記事の内容です。それ以前の音素の弁別的素性に基づいたアライメントツールの記事にも参考になる情報が沢山あるのでご確認ください。
強制アライメントができると何ができる?
音声認識モデルの訓練データ作成
音声認識システムを構築するには機械学習を用いるのが既に一般的です。機械学習には学習データが必要ですが、どのタイミングで何の音が話されているかというアライメント情報はモデルの精度向上に大いに役立ちます。学習データを自動で収集できるシステムを作ることができればスケール則でどんどん賢くなる機械学習モデルの大きな武器になるでしょう。
リップシンク
アニメーションや映像制作の分野ではキャラクターの口の動きとセリフを同期させるリップシンクと呼ばれる技術があります。従来は主に手動でこの作業を行うしかありませんでしたが、正確な強制アライメント技術の登場はリップシンクの自動化に貢献すると考えられます。
音声合成(TTS)
音声合成(TTS:Text-to-Speech)はテキスト情報をコンピューターが読み取り、それを人間が話すような自然な音声に変換する技術のことです。この技術は色々な手法がありますが、音声波形を生成する段階で波形接続型(Concatenative)と呼ばれる人間の声を細かく分割したデータを活用する手法があります。音素毎に細かく分割されたデータの作成に強制アライメントされたデータが有効に活用されるでしょう。
様々な活用方法がある強制アライメントを早速Pythonで使ってみよう!
動作環境
この記事では以下の環境でコードの動作を確認しました。pydominoはGitHubリポジトリから pip installするので、余計なライブラリ依存関係のエラーを避けるために新規仮想環境を立ち上げた方が良いと思います。venvによる仮想環境の構築は「M3 Macでvenv/VSCodeによるPython環境を構築するときの備忘録」をご覧ください。
| Mac | OS | macOS Sonoma 14.5 |
|---|---|---|
| チップ | Apple M3 | |
| CPU | 1.4[GHz] | |
| メモリ | 16[GB] |
| Python | Python 3.12.3 |
|---|---|
| pydomino | 1.1.0 |
| numpy | 2.1.3 |
| librosa | 0.11.0 |
| matplotlib | 3.10.1 |
| scipy | 1.15.2 |
pydominoのインストール
pydominoはGitHubのリポジトリから cloneしてインストールします。
|
1 2 3 |
git clone --recursive https://github.com/DwangoMediaVillage/pydomino cd pydomino pip install ./ |
【母音検証】pydominoで強制アライメントを行うコード
まずは一番簡単な母音だけの音声データでpydominoの使い方を確かめてみましょう。
サンプルのwavファイル
コードの検証には音声品質の良い音読さんによる音声ファイルを使用しました。こちらの「あいうえお」の音声ファイルを使います。
サンプルコード1:強制アライメントの結果をタブ区切りで出力する
次のPythonコードはwavファイルに対して強制アライメントを実施し、結果の情報を .tsv形式(タブ区切り)テキストファイルに出力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pydomino import librosa import numpy as np # モデルの読み込み model_path = "pydomino/onnx_model/phoneme_transition_model.onnx" aligner = pydomino.Aligner(model_path) # 音声ファイルの読み込み(16kHz, モノラル, float32型で読み込む) wav_path = "aiueo.wav" y, sr = librosa.load(wav_path, sr=16000, mono=True, dtype=np.float32) # 音素列の定義 phoneme_sequence = "pau a i u e o pau" # アライメントの実行(第三引数は反復回数) alignment = aligner.align(y, phoneme_sequence, 3) # 結果の表示 print("アライメント結果:") for start_time, end_time, phoneme in alignment: print(f"{start_time:.2f}秒 - {end_time:.2f}秒: {phoneme}") # タブ区切りのテキストファイルに結果を出力 output_file = "alignment_result.tsv" with open(output_file, "w", encoding="utf-8") as f: for start_time, end_time, phoneme in alignment: f.write(f"{start_time:.2f}\t{end_time:.2f}\t{phoneme}\n") |
実行すると alignment-result.tsvというファイルが作成されます。ここで、各行の第一要素と第二要素は秒数を表し、音素の範囲を示しています。第三要素はその範囲の音素です。
|
1 2 3 4 5 6 7 |
0.00 0.15 pau 0.15 0.29 a 0.29 0.46 i 0.46 0.61 u 0.61 0.79 e 0.79 0.94 o 0.94 1.93 pau |
サンプルコード2:強制アライメント結果をグラフで示す
先ほどのコードは強制アライメントの結果をテキスト情報のみに出力していたので、今度は実際の波形を使って見えるようにしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
import numpy as np import librosa import matplotlib.pyplot as plt import pydomino def plot_waveform_with_alignment(audio_path, aligner, phoneme_sequence): """波形にアライメント結果を表示する関数""" # wavファイルの読み込み data, sample_rate = librosa.load(audio_path, sr=None) # 時間軸データ作成 time_axis = np.arange(len(data)) / sample_rate # matplotlibの設定 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' fig, ax = plt.subplots(figsize=(8, 3)) ax.yaxis.set_ticks_position('both') ax.xaxis.set_ticks_position('both') ax.set_xlabel('Time [s]') ax.set_ylabel('Amplitude') # 波形データをプロット ax.plot(time_axis, data, lw=1, color='red', label='Waveform') # pydominoによる強制アライメント alignment = aligner.align(data, phoneme_sequence, 3) # アライメント結果をカーソルとラベルで表示 for seg in alignment: start_time, end_time, phoneme = seg ax.axvline(x=start_time, color='blue', linestyle='--', linewidth=1.5) mid_time = (start_time + end_time) / 2 ymax = np.max(np.abs(data)) ax.text(mid_time, ymax * 0.9, phoneme, color='black', fontsize=12, ha='center', va='top', bbox=dict(facecolor='white', edgecolor='black', pad=1)) # 最後の終了時刻にもカーソル線を引く if alignment: final_end = alignment[-1][1] ax.axvline(x=final_end, color='blue', linestyle='--', linewidth=1.5) fig.tight_layout() plt.show() if __name__ == "__main__": """メイン""" # モデル model_path = "pydomino/onnx_model/phoneme_transition_model.onnx" aligner = pydomino.Aligner(model_path) # 音素の指定 phoneme_sequence = "pau a i u e o pau" # wavファイルの指定 audio_path = "aiueo.wav" # 関数を実行して波形に強制アライメント結果を表示する plot_waveform_with_alignment(audio_path, aligner, phoneme_sequence) |
ここがポイント!

子音の指定方法は記事の後半に示しますが、pydominoでは指定された音素と音素の間の遷移を検出します。そのため音素の遷移が見つからない時は RuntimeError: Transition from a to i is not defined.というエラーが出るので注意が必要です。
下図はコードの実行結果です。「あいうえお」という発話にpydominoで得られたアライメント情報(時間範囲)を青点線で示したものです。
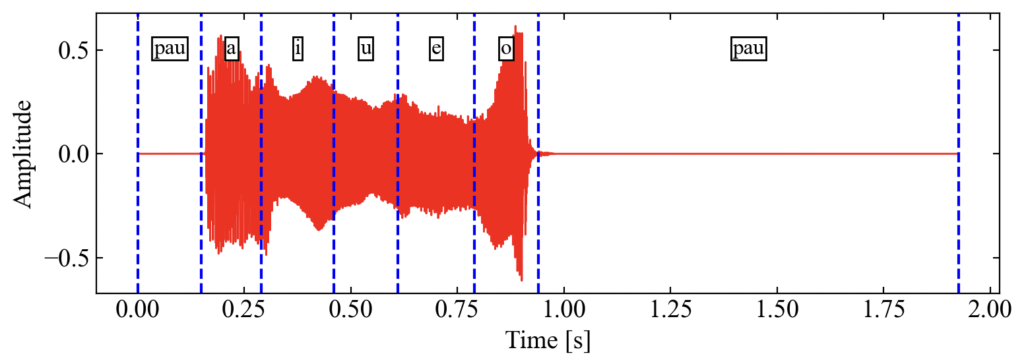
カーソルがあると間違っていないかどうかの確認がしやすいですね!
サンプルコード3:音素毎のwavファイルを保存する
波形にカーソルを表示させただけではなく、実際に音素を耳で聴いてみましょう。次のコードは先ほどまでの強制アライメント結果を使って音声データ全体を個別のwavファイルに保存するものです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import pydomino import librosa import numpy as np import soundfile as sf def get_alignment_info(wav_path, phoneme_sequence, model_path, iterations=3): """アライメント情報を取得する関数""" # モデルの読み込み aligner = pydomino.Aligner(model_path) # 16kHz, モノラル, float32型で音声ファイルを読み込む y, sr = librosa.load(wav_path, sr=16000, mono=True, dtype=np.float32) # アライメントの実行 alignment = aligner.align(y, phoneme_sequence, iterations) return alignment, y, sr def save_non_pau_segments(alignment, y, sr, output_prefix="segment"): """音素毎に分割したwavファイルを保存する関数""" for idx, (start_time, end_time, phoneme) in enumerate(alignment): # "pau"以外の場合にwavファイルとして保存 if phoneme != "pau": # 開始・終了サンプル番号に変換 start_sample = int(start_time * sr) end_sample = int(end_time * sr) segment = y[start_sample:end_sample] # ファイル名例: segment_1_a.wav output_filename = f"{output_prefix}_{idx+1}_{phoneme}.wav" sf.write(output_filename, segment, sr) print(f"Saved segment: {output_filename}") if __name__ == "__main__": """メイン""" # 各種パラメータの定義 model_path = "pydomino/onnx_model/phoneme_transition_model.onnx" wav_path = "aiueo.wav" phoneme_sequence = "pau a i u e o pau" # アライメント情報の取得 alignment, y, sr = get_alignment_info(wav_path, phoneme_sequence, model_path, iterations=3) # アライメント結果の表示 print("アライメント結果:") for start_time, end_time, phoneme in alignment: print(f"{start_time:.2f}秒 - {end_time:.2f}秒: {phoneme}") # タブ区切りのテキストファイルに結果を出力 output_file = "alignment_result.tsv" with open(output_file, "w", encoding="utf-8") as f: for start_time, end_time, phoneme in alignment: f.write(f"{start_time:.2f}\t{end_time:.2f}\t{phoneme}\n") print(f"アライメント結果を {output_file} に保存しました。") # 「pau」以外の各音声区間を個別のwavファイルに保存 save_non_pau_segments(alignment, y, sr) |
このコードを実行すると、プログラム実行フォルダの中に各音素セグメント毎のwavファイルが作成されます。pauの範囲は意味を持たないので、pau以外の音素を保存しています。

これで自分の耳で音素の音声を聴くことができます!
サンプルコード4:スペクトログラムに音素ラベルを表示する
音声データは生波形よりもスペクトログラムで見た方が情報が整理されます。「Pythonで音のSTFT計算を自作!スペクトログラム表示する方法」で作成した自家製スペクトログラムコードを使ってpydominoの音素ラベルをプロットできるようにしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
import numpy as np import librosa import matplotlib.pyplot as plt import pydomino from scipy import signal, fftpack def ov(data, samplerate, Fs, overlap): """オーバーラップ抽出する関数""" Ts = len(data) / samplerate Fc = Fs / samplerate # フレームずらし幅(整数に変換) x_ol = int(Fs * (1 - (overlap / 100))) N_ave = int((Ts - (Fc * (overlap / 100))) / (Fc * (1 - (overlap / 100)))) frames = [] final_time = 0 for i in range(N_ave): ps = int(x_ol * i) frames.append(data[ps:ps + Fs]) final_time = (ps + Fs) / samplerate return frames, N_ave, final_time def hanning(data_array, Fs, N_ave): """各フレームにハニング窓をかけ、振幅補正係数を返す""" han = signal.windows.hann(Fs) acf = 1 / (np.sum(han) / Fs) for i in range(N_ave): data_array[i] = data_array[i] * han return data_array, acf def db(x, dBref): """dB変換する関数(dBref=2e-5)""" # 0除算を防ぐため、極小値を与える return 20 * np.log10(np.maximum(x, 1e-12) / dBref) def fft_ave(data_array, samplerate, Fs, N_ave, acf): """ 各フレームのFFTを計算し、窓関数補正後にdB変換(dBref=2e-5)。 実数信号なので、ナイキスト周波数(前半部分)だけを使用する。 """ fft_array = [] half_Fs = Fs // 2 # ナイキスト周波数まで fft_axis = np.linspace(0, samplerate/2, half_Fs) for i in range(N_ave): fft_result = fftpack.fft(data_array[i]) # FFTの前半部分(絶対値)に窓補正、正規化 fft_half = np.abs(fft_result[:half_Fs]) * acf / (Fs/2) fft_db = db(fft_half, 2e-5) fft_array.append(fft_db) fft_array = np.array(fft_array) fft_mean = np.mean(fft_array, axis=0) return fft_array, fft_mean, fft_axis def plot_spectrogram_with_alignment(audio_path, aligner, phoneme_sequence, Fs=512, overlap=75): """ wavファイルを読み込み、dB変換されたスペクトログラム(ナイキスト周波数まで表示)を描画し、 その上にpydominoによる強制アライメント結果(カーソルとラベル)を重ね描画する関数 """ # WAVファイルの読み込み data, sample_rate = librosa.load(audio_path, sr=None) time_axis = np.arange(len(data)) / sample_rate # pydominoによる強制アライメント alignment = aligner.align(data, phoneme_sequence, 3) # スペクトログラム計算 frames, N_ave, final_time = ov(data, sample_rate, Fs, overlap) frames, acf = hanning(frames, Fs, N_ave) fft_array, fft_mean, fft_axis = fft_ave(frames, sample_rate, Fs, N_ave, acf) # 転置して、縦軸を周波数、横軸を時間に fft_array = fft_array.T # グラフ作成 fig, ax = plt.subplots(figsize=(10, 5)) im = ax.imshow(fft_array, origin='lower', extent=[0, final_time, 0, sample_rate/2], aspect='auto', cmap='jet') fig.colorbar(im, ax=ax, label='Magnitude [dB]') ax.set_xlabel('Time [s]') ax.set_ylabel('Frequency [Hz]') # 強制アライメント結果の各セグメントに対してカーソルとラベルを表示 for seg in alignment: start_time, end_time, phoneme = seg ax.axvline(x=start_time, color='blue', linestyle='--', linewidth=1.5) mid_time = (start_time + end_time) / 2 # スペクトログラム上部付近にラベルを配置(周波数軸は0~Nyquist) ax.text(mid_time, sample_rate/2 * 0.9, phoneme, color='black', fontsize=12, ha='center', va='top', bbox=dict(facecolor='white', edgecolor='black', pad=1)) # 最後の終了時刻にもカーソル線を引く if alignment: final_end = alignment[-1][1] ax.axvline(x=final_end, color='blue', linestyle='--', linewidth=1.5) fig.tight_layout() plt.show() if __name__ == "__main__": """メイン""" # モデルの読み込み model_path = "pydomino/onnx_model/phoneme_transition_model.onnx" aligner = pydomino.Aligner(model_path) # アライメント用音素列の指定 phoneme_sequence = "pau a i u e o pau" # wavファイルのパスの指定 audio_path = "aiueo.wav" # 関数を実行してスペクトログラムに強制アライメント結果を表示する plot_spectrogram_with_alignment(audio_path, aligner, phoneme_sequence) |
以下の図が実行結果です。スペクトログラム上に音素のラベルが表示されました。こちらの方が声帯振動やフォルマントの様子を確認しやすいですね。
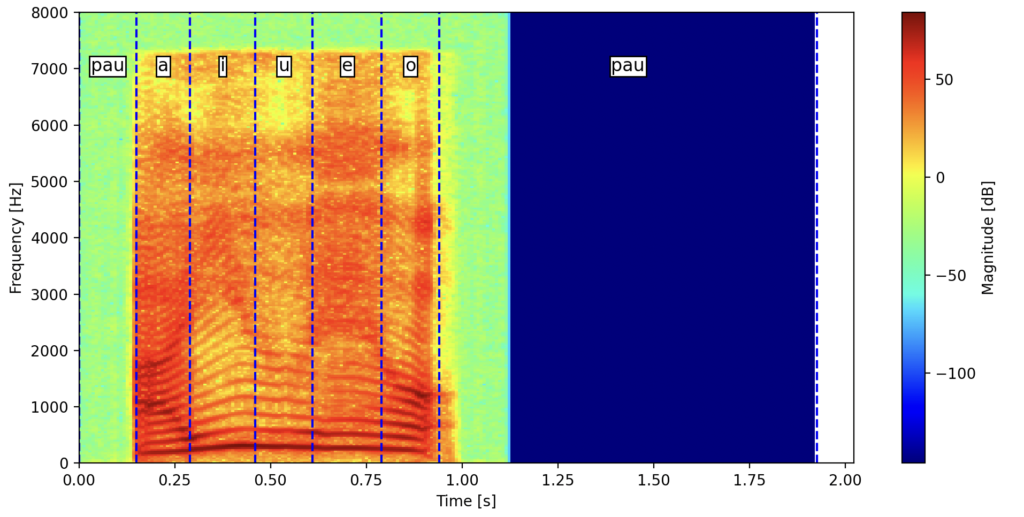
【子音検証】pydominoで強制アライメントを行う時の音素列
母音は簡単でしたが、正直素人には音素列に何を指定して良いかわかりません。pydominoの音素ラベルは上記表に示す39種類ですが、概ねヘボン式ローマ字のように音と対応づけられているようです\(^{[1]}\)。この節では実際に音声に対して音素列を定義して、効果を確かめてみることをやってみましょう。
「こんにちは」の音素列
以下の音読さん音声をサンプルに使います。
「こんにちは」は次の音素列で表現されます。
|
1 |
phoneme_sequence = "pau k o N n i ch i w a pau" |
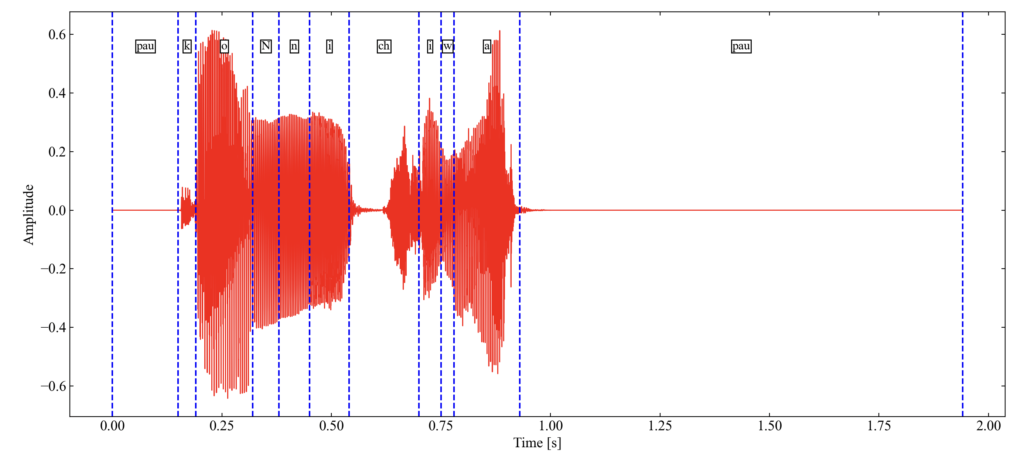
matplotlibで確認したりwav音声を聴いて確認したりすると、以下の結果は妥当のようです。kやchといった子音は母音の前で微かに音が鳴っているレベルのように見えますね。「ん」は撥音(はつおん)と呼ばれる種類の音素で\(^{[2]}\)、pydominoでは大文字のNで表現するとのことです\(^{[1]}\)。
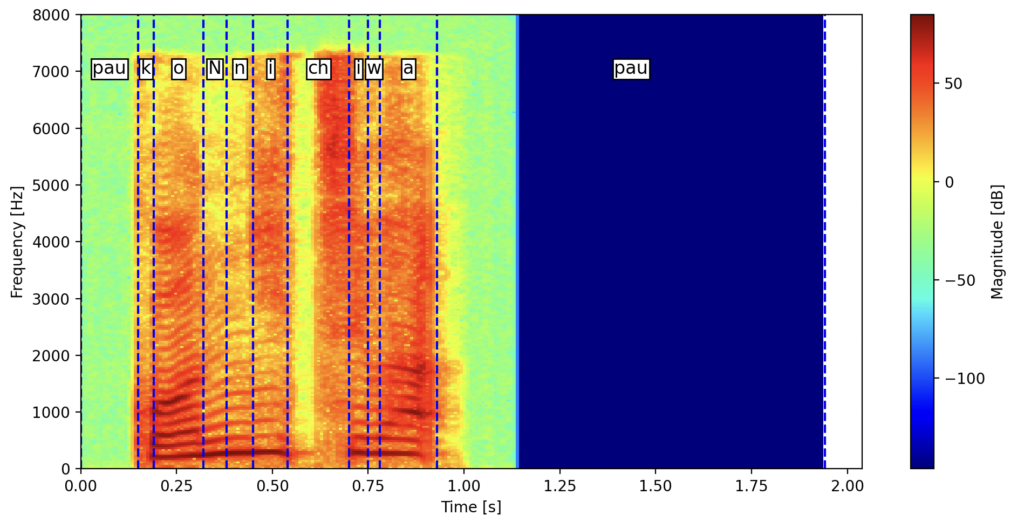
スペクトログラムで見ると次の通り。音屋からするとこちらの方が見やすいですね。kやchは声帯振動が目立っていませんが、その他の音素は基本周波数とその高調波からなる声帯振動がよくわかります。
「かきくけこ」の音素列
先ほどと同様に、音読さんで作成した「かきくけこ」もローマ字の要領で以下の音素列を指定します。
|
1 |
phoneme_sequence = "pau k a k i k u k e k o pau" |
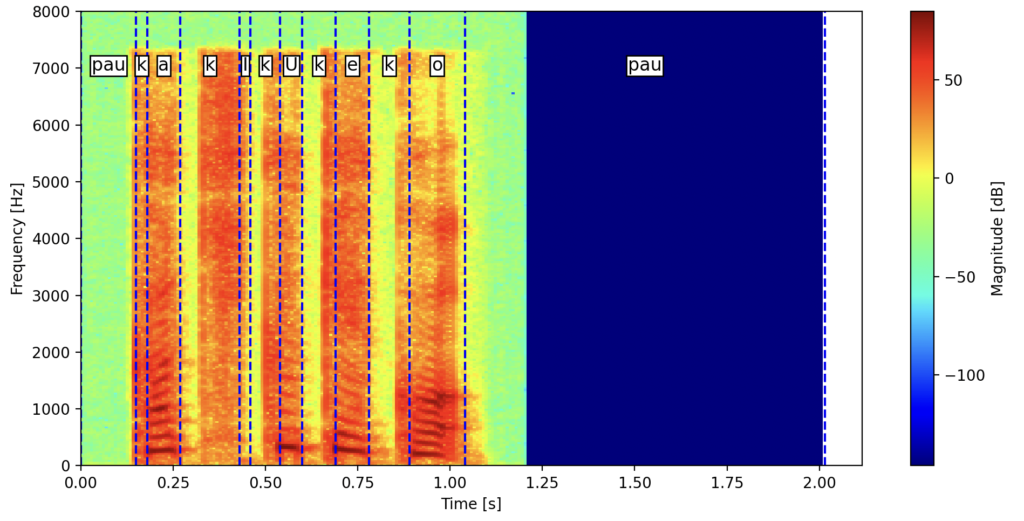
スペクトログラムを見るとk iのkやk oのkはややフライング気味なような気がしますが、分割されたwavファイルを聴くと確かに正確に判定できているようです。発話のタイミングによっては間にpauを入れるべき部分があるのかも知れませんが、pauを入れなくても遷移を計算できるレベルであったからこうなるのでしょうか?この辺は使いながら確認していく必要がありそうですね。
50音の音素表
50音と音素の対応表を作成してみました。間違いがあるかも知れませんが、まずはこの表を目安に音素ラベルを作ればよさそうです。
| 行 | あ段 | い段 | う段 | え段 | お段 |
|---|---|---|---|---|---|
| あ行 | a | i | u | e | o |
| か行 | k a | k i | k u | k e | k o |
| さ行 | s a | sh i | s u | s e | s o |
| た行 | t a | ch i | ts u | t e | t o |
| な行 | n a | n i | n u | n e | n o |
| は行 | h a | h i | f u | h e | h o |
| ま行 | m a | m i | m u | m e | m o |
| や行 | y a | (-) | y u | (-) | y o |
| ら行 | r a | r i | r u | r e | r o |
| わ行 | w a | (-) | (-) | (-) | w o |
| が行 | g a | g i | g u | g e | g o |
| ざ行 | z a | j i | z u | z e | z o |
| だ行 | d a | j i | d u | d e | d o |
| ば行 | b a | b i | b u | b e | b o |
| ぱ行 | p a | p i | p u | p e | p o |
| 拗音 | ky a, gy a, sh a, j a, ch a, ny a, hy a, by a, py a, my a, ry a |
(-) | ky u, gy u, sh u, j u, ch u, ny u, hy u, by u, py u, my u, ry u |
(-) | ky o, gy o, sh o, j o, ch o, ny o, hy o, by o, py o, my o, ry o |
| 特殊音 | ん:N っ:cl 無音:pau 無声い:I 無声う:U ヴ:v | ||||
明確に区切って発話する場合、長音の場合…は今回試していませんが、試したらここに追記しようと思います。
まとめ
ここでは基礎知識として強制アライメントやハードアライメント、音素といった用語を説明し、強制アライメントの活用先とpydominoを使うメリットをいくつか紹介しました。
また、pydominoのインストール方法とサンプルコードを紹介し、母音と子音を含む実際の音声に対して処理を適用してみました。結果、意図した通りの音素分割ができることを確認しました。これらの音素分割を活用したソリューションは色々思いつくので今後試して有用なものができたら差し支えない範囲で公開してみたいと思います。
参考文献
[1]:Shun Ueda, 音素の弁別的素性に基づいたアラインメントツール pydomino
[2]:竹内京子, 稲田朋野晃, 言語聴覚療法学テキスト 音響・音声学, (2023), 第1版第1刷, pp28-29
自動的に強制アライメントを行うpydominoを使ってみました!
Xでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!