
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

近年Google検索は完全に情報収集の基本になっています。Webスクレイピングで自動情報収集をする場合、Google検索結果を扱えるようになると世界中の情報をシステマティックに処理できるようになります。ここでは、Google検索で得られるタイトルとURLを一覧で取得する方法を紹介します。
こんにちは。wat(@watlablog)です。
WebスクレイピングでGoogle検索結果を自在に操れるようになってきましたので、ここでは検索タイトルとURLを一覧で取得する方法を紹介します!
Google検索を自動化するメリット3選
ビッグデータを容易に取得できる
Google検索は現代の情報収集の基本となっており、当ブログを始め様々なWebサイトがネットワークを介して検索できるようになっています。
Googleを始めとした検索エンジンからは、あらゆるブログ、公的機関、民間企業のページに繋がっているので、ジャンルを問わず情報がひしめき合っている状況です。
Webスクレイピングをする上で、「PythonでWebスクレイピング!Requestsで情報取得!」で解説したように法的問題や著作権の問題に抵触する可能性があるため、自動でWebサイトをクローリングする時は細心の注意やマナー、ルール遵守が必要です。
しかしタイトルだけでも自動で情報収集できるようにしておくと、これだけでも一種のビッグデータを作ることができます。
例えば、「どんなワードが流行っているか」「関連ワードには何があるか」「どんなグループが書いているか」といった二次的な情報も容易に取得できます。
一人で、しかも手動でこれをまとめるのは何日もかかってしまいますが、プログラムで自動化させてしまえば夜中や仕事中に終わらすことが可能です。
自分のWebサイトのランキング分析ができる
最近はブログを書く人が本当に増えて来ました。中には収益化を狙ってSEO対策(検索エンジン最適化対策)をばりばりこなしている人も多いでしょう。
ビッグワードでGoogle検索上位に入ることができれば、ブログへのアクセス数も増加し、比例して収益も増加していくことが予想されます。
ブログを始めとした自分のWebサイトのGoogleにおけるランキングを正確に把握しておくことができれば、SEO対策における試行錯誤の判断材料になります。
しかし、ブログ運営をしている人の検索キーワードは複数あるので、手動でまとめるのはやっかいです。効率化のためには自動化が必須であり、Webスクレイピングはこの部分で威力を発揮します。
他人のWebサイトの分析もできる
上では自分のWebサイト分析の話をしましたが、Google検索の自動化ができれば同様の手法で他人(特にライバルサイト)の分析もできるようになります。
「〇〇のサイトは自分と同じような検索ワードを使っている。他にはどんなワードを使ってどんな記事を書いているんだろう?ドメインを使って検索してみよう。」
…ということも可能になります。※著作権上の問題には十分注意が必要!
「彼を知り、我を知れば百選危うからず」という言葉もあるので、情報収集→分析→戦略立案→実行→評価…のサイクルは自分と他人で行うのが効果的です。
PythonでGoogle検索からタイトルとURL一覧を取得するコード
事前準備
Python環境
コードを説明する前に、Pythonの環境を整える必要があります。
もし、まだPythonのインストールをしていない方は、是非「Pythonインストール方法とAnacondaを使わない3つの理由」を参照下さい。この記事の最初から次へ、次へ、と読み進めて行くと筆者である僕と同じPythonプログラミング環境が出来上がります。Anacondaを使っていないので、ある程度万人に対応すると思います。
コーディング能力
当ブログに載せてあるコードは特にフリーで使って頂いて構わなく、基本「#」を使ってコメントを残していますが、理解するにはある程度のコーディング能力は必要と思います。
僕はWebの情報を調べつつPython関係で70記事ほど書いてきたので、自己流で学習をしてきましたが、手っ取り早く基本スキルを身に着けるには「PyQ」というサービスが適しています。
気になる方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」を読んでみて下さい。
実は僕もまだまだ初心者で、実際に登録して基本コースを受講しています。意外と知らないことが多いです…。
Seleniumのインストール
車輪の再発明を避けるために、当ブログのコードは外部パッケージを多用しています。
今回はSeleniumというWebブラウザを自動で操作するライブラリを使いますが、まだインストールしていない人は「Python/SeleniumでChrome自動Google検索」を参照下さい。pipによるインストールと簡単な例題を載せています。
「PythonでWebスクレイピング!Requestsで情報取得!」ではRequestsというパッケージを使ってWebから情報を収集していましたが、この方法だとブラウザの情報によって動作を変えるWebサイト(Google等)に対応していません(正確には、対応させるために工夫が必要)。また、Seleniumであれば、ブラウザ起動後に遅れて出てくるポップアップにも対応ができるメリットもあります。
そして、「PythonのBeautifulSoupでWebスクレイピング!」ではBeautifulSoupというパッケージを使ってHTMLタグのスクレイピングを行っていましたが、今回は使っていません。
Seleniumであればブラウザを自動操作するため、ブラウザの情報で発生する問題は気にしなくても良いです。また、Selenium自体が.find_element等のスクレイピングメソッドを持っており、BeautifulSoupをimportしなくても良いのでコードがすっきりするメリットもあります。
ChromeDriverのインストール
SeleniumはWebブラウザを自動操作します。当ブログではGoogle Chromeというブラウザを使ってコードを書いていますので、Chromeをプログラム的に動かすためのドライバ(chromedriver-binary)が必要です。
chromedriver-binaryはpipでインストール可能ですが、使い方が他のパッケージと少々違う(パスを通す必要等)ので、まだ使ったことが無い方は「Python/ChromeDriverインストールとパスの通し方」を読んでみて下さい。
コード説明①:ChromeでGoogleを開き自動で検索する
まずはSeleniumを使ってChromeを操作し、Google検索画面を開きます。検索をするためには検索ボックスにワードを入力して送信する必要があります。
検索ボックスはHTML上、name="q"と名前が割り当てられているので、それを手掛かりにfind_element_by_nameで見つけています。
入力フォームが見つかったら、send_keysでワードを入力し、submitで登録(エンターの動作)し検索を開始します。
ここでtime.sleepで3秒待っていますが、あまり自動操作の間隔が短いとそれは実質Webサイトへの攻撃になってしまうので、Googleに怒られないようにするために入れています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://www.google.com/') # Googleを開く search = driver.find_element_by_name('q') # HTML内で検索ボックス(name='q')を指定する search.send_keys('WATLABブログ') # 検索ワードを送信する search.submit() # 検索を実行 time.sleep(3) # 3秒間待機 |
コード説明②:タイトルとリンクをスクレイピングする関数
関数コード概要
詳細を説明する前に、概要を説明します。
この関数は引数を先ほど定義したdriver(Google Chrome)とし、Google検索ページをクローリングしてタイトルとURLリンクをリストで返す関数です。
基本は情報(タイトルとURLリンク)を抽出したら「次へ」で次のページに遷移し、再度情報を抽出…という事をwhileループでやっているだけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def ranking(driver): i = 1 # ループ番号、ページ番号を定義 i_max = 2 # 最大何ページまで分析するかを定義 title_list = [] # タイトルを格納する空リストを用意 link_list = [] # URLを格納する空リストを用意 # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: # リンク('a href')とタイトル('h3')の入ったHTMLを抽出(クラス名で)→アプデで変わる可能性あり class_group = driver.find_elements_by_class_name('yuRUbf') # リンクとタイトルを抽出しリストに追加するforループ for elem in class_group: # リンク link = elem.find_element_by_tag_name('a').get_attribute('href') # タイトル title = elem.find_element_by_tag_name('h3').text # 動画、画像、説明, 「他の人は〜」といった記事とは関係ないコンテンツを排除 if title != '動画' and title != '画像' and title != '説明': if title != '': title_list.append(title) link_list.append(link) # 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。 if driver.find_elements_by_id('pnnext') == []: i = i_max + 1 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id('pnnext').get_attribute('href') # 次ページへ遷移する driver.get(next_page) i = i + 1 time.sleep(1) return title_list, link_list |
続いて関数の詳細を説明していきます。
初期変数の定義
まず変数についてですが、初期的には以下の4つを用意します。
iはページを遷移していくたびに増分し、最大分析ページ数i_maxになったらループを止めるための終了条件として使用します。
title_listとlink_listは最終的に戻り値として必要なアウトプットを入れるために用意します。これを用意しておかないと、appendで追加していくことができません。
|
1 2 3 4 |
i = 1 # ループ番号、ページ番号を定義 i_max = 2 # 最大何ページまで分析するかを定義 title_list = [] # タイトルを格納する空リストを用意 link_list = [] # URLを格納する空リストを用意 |
タイトルとURLリンクを抽出してリストに追加する
続いてメイン動作であるタイトルとURLリンクをリストに追加する方法です。
Google検索結果ページのHTMLから、タイトルとセットになったURLを抽出するために、「Python/Seleniumでclass名で情報取得する方法」で学んだXPath Helperを使います。
これらの情報は全てclass="yuRUbf"の中に入っているので、まずはclass_groupとしてそれらを抽出します。ここで、find_elementsと複数形にすることでそのページ内のclass部分を全てリストで抽出することができます。
※class名はGoogleのアップデートで変更される可能性がありますので、自分で調べられるようにしておいた方が良いでしょう。
あとはこのclass_groupリストに対してタイトルだけ、URLだけ、の形にしてそれぞれ最初に作っておいたリストにappendで格納します。
ちなみに、タイトルはHTMLの「h3」タグ(見出しタグ)、URLはHTMLのaタグを拾って、hrefという属性名で持って来ることができます。この部分の検索はelementと単数形にしてforループで一つずつ抽出しているので注意。
|
1 2 3 4 5 |
# リンク link = elem.find_element_by_tag_name('a').get_attribute('href') # タイトル title = elem.find_element_by_tag_name('h3').text |
記事とは関係のないコンテンツを排除する
2022年3月時点のGoogleは、「動画、画像、説明」や「他の人は〜」といった記事とは関係ないコンテンツも提案してきました。そのため、それらを排除するif文を追記しています。
「他の人は〜」はh3タグが空になるという特徴を使っています。特徴量さえつかめれば自分でカスタマイズすることも可能です。
|
1 2 3 4 5 |
# 動画、画像、説明, 「他の人は〜」といった記事とは関係ないコンテンツを排除 if title != '動画' and title != '画像' and title != '説明': if title != '': title_list.append(title) link_list.append(link) |
Googleの「次へ」を使ったページ遷移と例外処理
先ほどまでの処理で1ページ内にあるタイトルとURLは抽出できますが、Google検索は複数のページに分割されています。
ページ2、ページ3、のリンクを探してという方法も考えましたが、「次へ」を使った方がより汎用的でコードがすっきりすると思いますので、今回の関数では「次へ」と対応するid="pnnext"を拾い、属性名であるhrefでリンクを取得、getでページ遷移をしています。
図で説明すると、以下のGoogle検索ページの下の方にある所の作業です。
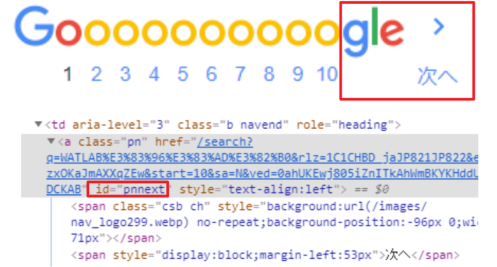
但し、検索ボリュームが少ない場合等、検索結果がi_maxで指定したページ数に満たない場合があります。
単純にfind_elementでpnnextを検索しても、「次へ」が無い場合はエラーでプログラムが終了してしまうので、例外処理を入れています。
find_elementで発生するエラー処理のやり方がわからなかったので、まずはelementsと複数形で検索を行う方法を使いました。
複数形の検索方法であれば、検索対象が無い場合に空のリスト「[ ]」が返されエラー終了しないので、これをif文の条件式に使いました。
「次へ」が無い場合はiの値を強制的にwhileループ終了条件であるi_maxを超える値にして処理を終了します。「次へ」がある場合はそのURLを使ってページ遷移をするというロジックです。
|
1 2 3 4 5 6 7 8 9 |
# 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。 if driver.find_elements_by_id('pnnext') == []: i = i_max + 1 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id('pnnext').get_attribute('href') driver.get(next_page) # 次ページへ遷移する i = i + 1 # iを更新 time.sleep(3) # 3秒間待機 |
保存までの全コード(コピペ用)
※これは2019年時点のコードです。下に暫定で2022年3月の修正コードを示していますので、しばらく動作確認したらこちらを削除して新しいコードに切り替える予定です。
主要な機能は上記内容で全てです。以下にコピペ用の全コードを示します。是非ご自分の環境でお試し下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://www.google.com/') # Googleを開く search = driver.find_element_by_name('q') # HTML内で検索ボックス(name='q')を指定する search.send_keys('WATLABブログ') # 検索ワードを送信する search.submit() # 検索を実行 time.sleep(3) # 3秒間待機 def ranking(driver): i = 1 # ループ番号、ページ番号を定義 i_max = 2 # 最大何ページまで分析するかを定義 title_list = [] # タイトルを格納する空リストを用意 link_list = [] # URLを格納する空リストを用意 # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: # タイトルとリンクはclass="r"に入っている class_group = driver.find_elements_by_class_name('r') # タイトルとリンクを抽出しリストに追加するforループ for elem in class_group: title_list.append(elem.find_element_by_class_name('yuRUbf').text) #タイトル(class="LC20lb") link_list.append(elem.find_element_by_tag_name('a').get_attribute('href')) #リンク(aタグのhref属性) # 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。 if driver.find_elements_by_id('pnnext') == []: i = i_max + 1 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id('pnnext').get_attribute('href') driver.get(next_page) # 次ページへ遷移する i = i + 1 # iを更新 time.sleep(3) # 3秒間待機 return title_list, link_list # タイトルとリンクのリストを戻り値に指定 # ranking関数を実行してタイトルとURLリストを取得する title, link = ranking(driver) # タイトルリストをテキストに保存 with open('title.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(title)) # URLリストをテキストに保存 with open('link.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(link)) driver.quit() # ブラウザを閉じる |
実行結果(動画とファイル)
上記コードを実行すると、以下の動画で示す動作をします。(2ページしか分析しないコードですが、ページ遷移は3ページ目までしてしまう所にムダがあるかな?)
そしてテキストファイルが2つ(title.txt, link.txt)出来ていると思いますが、それぞれのテキストは以下のようになります。ここではこの先の利用を考えず、単純にリストをそのままファイルにしましたが、フォーマットを考えて1つのファイルにする方が賢いかも知れません。
2022年3月27日追記:タイトルをh3で抽出するように修正
記事を書いた当時は、全体をclass名で抽出していましたが、今はそれだとうまくいかないケースがあるようです(検索ワードによってうまくいかないケースがあるとご報告を頂きました。ありがとうございます)。
そのため、タイトルとリンクの入ったclassを「driver.find_elements_by_class_name」で抽出し、その後タイトルをh3タグで抽出するという方法に変更しました。
また、最近のGoogle検索は「動画」、「画像」、「説明」、「他の人はこちらも質問」、「他のキーワード」といったコンテンツが間に入ってくるので、それをif文で排除してみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://www.google.com/') # Googleを開く search = driver.find_element_by_name('q') # HTML内で検索ボックス(name='q')を指定する search.send_keys('WATLABブログ') # 検索ワードを送信する search.submit() # 検索を実行 time.sleep(3) # 3秒間待機 def ranking(driver): i = 1 # ループ番号、ページ番号を定義 i_max = 2 # 最大何ページまで分析するかを定義 title_list = [] # タイトルを格納する空リストを用意 link_list = [] # URLを格納する空リストを用意 # 現在のページが指定した最大分析ページを超えるまでループする while i <= i_max: # リンク('a href')とタイトル('h3')の入ったHTMLを抽出(クラス名で)→アプデで変わる可能性あり class_group = driver.find_elements_by_class_name('yuRUbf') # リンクとタイトルを抽出しリストに追加するforループ for elem in class_group: # リンク link = elem.find_element_by_tag_name('a').get_attribute('href') # タイトル title = elem.find_element_by_tag_name('h3').text # 動画、画像、説明, 「他の人は〜」といった記事とは関係ないコンテンツを排除 if title != '動画' and title != '画像' and title != '説明': if title != '': title_list.append(title) link_list.append(link) # 「次へ」は1つしかないが、あえてelementsで複数検索。空のリストであれば最終ページの意味になる。 if driver.find_elements_by_id('pnnext') == []: i = i_max + 1 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id('pnnext').get_attribute('href') # 次ページへ遷移する driver.get(next_page) i = i + 1 time.sleep(3) return title_list, link_list # ranking関数を実行してタイトルとURLリストを取得する title, link = ranking(driver) print(ranking(driver)) # タイトルリストをテキストに保存 with open('title.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(title)) # URLリストをテキストに保存 with open('link.txt', mode='w', encoding='utf-8') as f: f.write("\n".join(link)) # ブラウザを閉じる driver.quit() |
まとめ
ここではPythonを使ったWebスクレイピングの例として、Google検索結果のタイトルとURLを一覧で取得する方法について説明しました。
ネットを検索すれば同様の目的が様々な方法で達成できることがわかりますが、僕個人としてはSeleniumとChromeDriverを使った本方法が一番わかりやすかったので記事にしてみました。
スクレイピングは特徴を抽出していかに情報を取得するかが重要です。今回の方法は例外処理の方法も含め僕が考えてコーディングした結果であるため、最も効率が良い方法とは言えないと思います。それでもWebスクレイピングのきっかけとして読んで頂ければ幸いです。
Chromeのシークレットモードや、ブラウザ立ち上げをしない方法もあるので、今後記事を追加予定です。
※Webスクレイピングは法的問題や著作権の問題に抵触しないよう十分ご注意を!
不明点があれば是非Twitterからお問い合わせください!僕でわかることであればお答え致します!
だんだん自力で色んなページのスクレイピングができるようになってきました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント失礼します
2021年2月現在、このコードを実行したところelementが見つからないとエラーが出るのですが、どう対処すればいいでしょうか?
LC20lbというクラス名が見つからないというエラーです
ご訪問ありがとうございます。
どうやらGoogleは定期的にclass名を変えているようです(スクレイピングを嫌っているという説も聴いた事あります)。
僕の方でもおそらく同様の現象でした。
今確認したらclass_nameを以下のようにしたら動くようになりました。
class_group = driver.find_elements_by_class_name(‘yuRUbf’)
Google Chromeの「検証」機能を使う事で調べる事ができます。
ご確認お願い致します。
DevTools listening on ws://127.0.0.1:55339/devtools/browser/8a07893e-17fd-4aeb-a052-ba4f8d025fba
wam3.py:11: DeprecationWarning: find_element_by_name is deprecated. Please use find_element(by=By.NAME, value=name) instead
[18204:13860:0325/202919.502:ERROR:device_event_log_impl.cc(214)] [20:29:19.508] USB: usb_device_handle_win.cc:1049 Failed to read descriptor from node connection: システムに接続されたデバイスが機能していません。 (0x1F)
[18204:13860:0325/202919.502:ERROR:device_event_log_impl.cc(214)] [20:29:19.508] USB: usb_device_handle_win.cc:1049 Failed to read descriptor from node connection: システムに接続されたデバイスが機能していません。 (0x1F)
[18204:13860:0325/202919.502:ERROR:device_event_log_impl.cc(214)] [20:29:19.510] USB: usb_device_handle_win.cc:1049 Failed to read descriptor from node connection: システムに接続されたデバイスが機能していません。 (0x1F)
wam3.py:25: DeprecationWarning: find_elements_by_class_name is deprecated. Please use find_elements(by=By.CLASS_NAME, value=name) instead
wam3.py:32: DeprecationWarning: find_elements_by_id is deprecated. Please use find_elements(by=By.ID, value=id_) instead
wam3.py:36: DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
上記の様なメッセージが出ます。title.txtとlink.txtが空になってしまいます。試みに、title, link = ranking(driver)の下段に、print((ranking(driver))と打って、driverの中身を見ようとしたところ、([], [])と空のリストが出来てしまっていたようです。
以上状況を打破したく思います。ご教示頂ければ幸甚です。
Python利用環境は、Miniconda3です。
ご訪問ありがとうございます。
こちらでは現象が再現しませんでしたが、以下のteratailという質問サイトで似たようなエラーの方がいらっしゃいました。
https://teratail.com/questions/252110
どうやらChromeブラウザとchromedriverのバージョンが関係していそうです。
バージョンは合っていますでしょうか?
ちなみにこちらは
chromedriver-binary==99.0.4844.51.0
で正常に機能していました。
以上、よろしくお願い致します。
早速のご返信どうもありがとうございます。
Chromeブラウザのバージョンは99.0.4844.84で、Chromedriver_binaryのバージョンは99.0.4844.51.0です。全く同じバージョンはありませんでした。
問題はまだ、続いています。xpath helperもクロームに追加しました。
以上よろしくお願い申し上げます。
chromedriver-binaryとブラウザのバージョンは揃えておかないと動作しないようです。
(PyPIを確認した所、100.0.4896.20.0までが出ているようです)
問題がバージョン不一致であるとまだ確定はできていませんが、
まずは問題の切り分けのために、
ブラウザをダウングレードするか、ブラウザを最新版にしてdriverも最新版にする…のが良いと思います。
どうも有難うございます。
Chromedriver-binaryとブラウザのバージョンが同じものがありません。chromedriver-binaryをpip installしようとすると、下記の様なエラーメッセージが出ます。
ERROR: Could not find a version that satisfies the requirement chromedriver_binary==99.0.4844.84 (from versions: 2.29.1, 2.31.1, 2.33.1, 2.34.0, 2.35.0, 2.35.1, 2.36.0, 2.37.0, 2.38.0, 2.39.0, 2.40.1, 2.41.0, 2.42.0, 2.43.0, 2.44.0, 2.45.0, 2.46.0, 70.0.3538.16.0, 70.0.3538.67.0, 70.0.3538.97.0, 71.0.3578.30.0, 71.0.3578.33.0, 71.0.3578.80.0, 71.0.3578.137.0, 72.0.3626.7.0, 72.0.3626.69.0, 73.0.3683.20.0, 73.0.3683.68.0, 74.0.3729.6.0, 75.0.3770.8.0, 75.0.3770.90.0, 75.0.3770.140.0, 76.0.3809.12.0, 76.0.3809.25.0, 76.0.3809.68.0, 76.0.3809.126.0, 77.0.3865.10.0, 77.0.3865.40.0, 78.0.3904.11.0, 78.0.3904.70.0, 78.0.3904.105.0, 79.0.3945.16.0, 79.0.3945.36.0, 80.0.3987.16.0, 80.0.3987.106.0, 81.0.4044.20.0, 81.0.4044.69.0, 81.0.4044.138.0, 83.0.4103.14.0, 83.0.4103.39.0, 84.0.4147.30.0, 85.0.4183.38.0, 85.0.4183.83.0, 85.0.4183.87.0, 86.0.4240.22.0, 87.0.4280.20.0, 87.0.4280.87.0, 87.0.4280.88.0, 88.0.4324.27.0, 88.0.4324.27.1, 88.0.4324.96.0, 89.0.4389.23.0, 90.0.4430.24.0, 91.0.4472.19.0, 91.0.4472.101.0, 92.0.4515.43.0, 92.0.4515.107.0, 93.0.4577.15.0, 93.0.4577.63.0, 94.0.4606.41.0, 94.0.4606.61.0, 94.0.4606.113.0, 95.0.4638.10.0, 95.0.4638.17.0, 95.0.4638.54.0, 95.0.4638.69.0, 96.0.4664.18.0, 96.0.4664.35.0, 96.0.4664.45.0, 97.0.4692.20.0, 97.0.4692.36.0, 97.0.4692.71.0, 98.0.4758.48.0, 98.0.4758.80.0, 98.0.4758.102.0, 99.0.4844.17.0, 99.0.4844.35.0, 99.0.4844.51.0, 100.0.4896.20.0)
ERROR: No matching distribution found for chromedriver-binary==99.0.4844.84
ところで、WAT様の他のサイトでダウンロードしたプログラム(WATLABブログを検索値として、1ページ目の記事のタイトルを抽出して、コマンドプロンプトに出力する)は問題なく動作します。あまり関係がない事象かと存じますが、念のためご報告いたします。
WAT様
class_group = driver.find_elements_by_class_name(‘r’)
を class_group = driver.find_elements_by_class_name(‘g’)に書き直したら、listとtitleに値が書き込まれました。
しかし、”WATLABブログ”以外の検索値では、listとtitleに値が書き込まれませんでした。
クラスネームは、WEBによって異なるのでしょうか?
以上宜しくお願い致します。
状況の詳細共有ありがとうございます。
キーワードを変更するとリストが空になる等、こちらも同じ現象が再現したようです。
記事作成当時のHTMLとはまた変わってしまっているようでした。
この記事の「2022年3月27日追記:タイトルをh3で抽出するように修正」
に追記をしましたが、このコードで動作はしますでしょうか?
WAT様、
ご返信どうも有難うございます。
「2022年3月27日追記:タイトルをh3で抽出するように修正」のケースが作動しました。
お手数をお掛けし、どうもすみませんでした。
クラスネームは時々変わることを理解しました。
今後とも宜しくお願い致します。
ご報告ありがとうございます。
こちらも初心者には変わりないので、こういった打ち上げは大変勉強になります!
本記事はこの内容でリライトする予定です。
是非今後も何か気付くことがございましたら教えて頂けると助かります。
ありがとうございました。