
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Pythonを使ったWebスクレイピングを、段階を踏んで説明していきます。まずはRequetsメソッドを使ったWeb情報の収集方法を解説します。
こんにちは。wat(@watlablog)です。
Webスクレイピングという技術は現在技術者が足りないほど人気です。ここではPythonによるHTML情報を取得するというWebスクレイピングの基礎を紹介します!
ここで紹介している内容はWebスクレイピングの一例に過ぎません。僕はPython特化型学習サービス「PyQ(パイキュー)」で基礎を覚えました。体系的にPythonプログラミングやWebスクレイピングを覚えたい方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」の記事をご覧下さい。
Webスクレイピングは現代情報収集のキーテクノロジー
情報収集の主流はWeb!自動で情報を収集しよう!
情報収集と言えば回覧板、掲示板、クチコミ、新聞紙、チラシ、テレビ…と昔は受動的な方法が主流でしたが、近年ではインターネットの発展とPCやスマホ、タブレット端末に代表される通信機器の普及から、Webを使った能動的な情報収集が主流になるというパラダイムシフトが起こりました。
今や誰しもがSNSやブログといった情報発信能力を持ち、日々リアルタイムに情報が生み出されて行っています。
時々刻々と情報が発生している現代で、効率よく情報収集を行うことは、個人の日常生活だけでなく、企業の戦略立案にも強く影響することになります。
本ページでは、効率的に情報収集をするためのプログラミング技術であるWebスクレイピングの基本のキを紹介します。
Webスクレイピングとは?
Webスクレイピングとは、簡単に言うとWebから情報を抽出する技術のことを言います。
スクレイピングは、元々「こすり落とす」とか「削ぎ落とす」という意味を持ちますが、Webスクレイピングはインターネットにある様々な情報を持って来て、必要な情報にするために、不要な情報を削ぎ落としたりすることからそう呼ばれているようです。
このページでは「削ぎ落す」前の情報を持って来る方法をPythonプログラミングによって説明していきます。
Webスクレイピングの注意!法的問題を避けるために規約を読もう!
Webスクレイピングは非常にシンプルかつ先進的な技術であるため、手法を覚えたその日から「世の中の情報を何でも持ってきてみよう!」と闇雲に乱用してしまう人もいるでしょう。
しかし、プログラミングで他者のWebサイトにアクセスするというのは、サーバーに少なからず負荷を与えているというのに違いはありません。
Webサイトによっては、利用規約でスクレイピングやクローラー(プログラム的にサイト内を巡回すること。bot等)の使用を禁じています。
そんなサイトを対象にWebスクレイピングを実行し続けていたら、訴訟問題等の法的処置が下るおそれがありますので、十分注意して下さい!
なので絶対に利用規約を読むことを忘れないで下さい。
Webスクレイピングにまつわる事件や気にするべき事
岡崎市中央図書館事件(Librahack事件)
Webスクレイピング関係の事件を調査すると、まずひっかかるのはこの「岡崎市中央図書館事件」でしょう。詳細は以下のWikipediaをご覧下さい。
それにしても、犯人は常識的なリクエスト送信をしていたそうですが、図書館側のソフト不備(しかもソフトウェアメーカーは不具合解消のバージョンを作っていたが市が旧バージョンを使い続けたとか)で問題が発生してしまい、最終的に偽計業務妨害の罪で逮捕されてしまうとは…おそろしや(後に不起訴処分になったとのことですが)。
この事件はあまりにも有名ですが、Webスクレイピングを行う時はスクレイピングしても良いサイトなのかどうかを調べましょう。
著作権の問題
Webは著作物の塊です。人が創作的に書いた文章、ファイル、プログラムといったモノには著作権があります。
著者の承諾無しにスクレイピングした内容を複製して配布したり、ブログにアップすることは著作権法違反となります。
しかしデータ解析用でスクレイピングを利用する場合は特に違法にはならないそうですので、スクレイピングをする時は著作権の観点でも十分注意するようにしましょう。
利用規約に書いてある場合
利用規約は良く見ておきましょう。
例えば、ユーザが情報をリアルタイムに発信するSNSの代表格にTwitterがありますが、Twitter社はWebスクレイピングを禁止しています。
(注:本サービスへのクローリングは、robots.txtファイルの定めによる場合は認められていますが、Twitterによる事前の同意がないまま本サービスのスクレイピングをすることは明示的に禁止されています)
Twitterサービス利用規約:https://twitter.com/ja/tos
Python/Requestsメソッドによる情報取得コード
色々と怖いことを書き連ねましたが、正しく使えばWebスクレイピングは強力な情報収集技術になります。
ここではPythonコードにより、Webから情報を取得するコードを紹介します。
以下がWebから情報を取得して文字列として表示させるためのコードです。情報を取得するページのURLは当WATLABブログで専用に作成した固定ページです(これなら練習しても誰にも迷惑かからないはず!)。
Webスクレイピングをばりばり練習したい方は、エックスサーバー等のレンタルサーバーを借りてWordpressでブログを開設すると捗りますよ。
![]()
さて、コードの説明ですが、このコードを実行するためにはrequestsパッケージのインストールが必要です。まだ入れていない人は「python -m pip install requests」でインストールしましょう。
requests.get関数でWebの情報(つまりHTTPの情報)を取得します。
このままでは日本語が文字化けしてしまうので、次の行でエンコードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# python -m pip install requestsが必要 import requests # 取得したいURLやweb上のファイル url = "https://watlab-blog.com/web-scraping-testpage/" # HTTPリクエストを送信して情報を取得 response = requests.get(url) response.encoding = response.apparent_encoding # 適切なエンコードを適用する # テキストとして表示 print(response.text) |
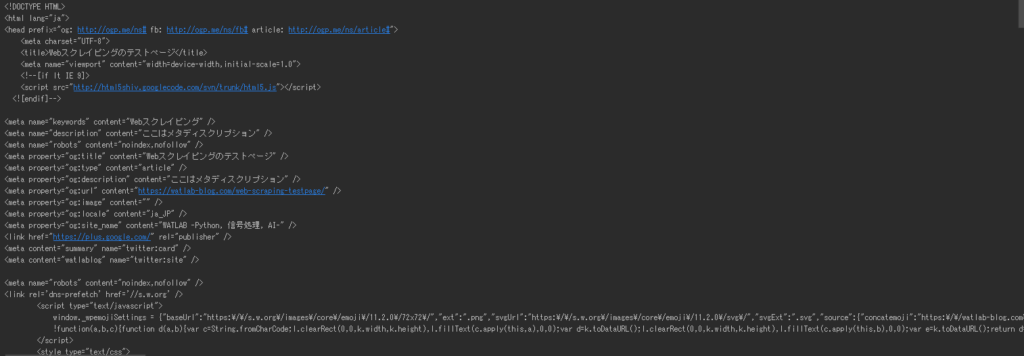
このコードの実行結果は以下になります。
簡単なページですが、色々なタグが付いていることがわかりました。このままだとまだ情報を分析するには至らないですが、ここがまずは第一歩!
まとめ
このページではWebスクレイピングの概要、その注意事項を説明し、実際にWebページにリクエストを送信して情報を取得する所までを扱いました。
この辺から始めればスクレイピングの基礎が学べると思いますので、このブログで少し深堀して行きたいと思います。
Webスクレイピングは気を付けて使えば非常に有用な技術です!次は取得したデータの加工をやっていきます!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント
Comments are closed.