
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

PythonでWebスクレイピングのコーディングをしていると、xpathによる情報抽出が便利であるとわかりました。しかしHTMLの構造を毎回解析するのはやっかいです。Chrome拡張機能である「XPath Helper」を使えば簡単に任意要素のxpathを取得することが可能です。
こんにちは。wat(@watlablog)です。
ここではxpathを簡単に取得するGoogle Chromeの拡張機能について、インストール方法と簡単な使い方までを習得します!
xpathを使うと何ができる?これまでのおさらい
「Python/Seleniumで便利なxpath検索をする方法!」では、Pythonというプログラミング言語で、Seleniumというパッケージを使ったWebスクレイピングの基礎を学びました。
xpathというロケーションパスを使うことで、簡単にWebサイトから目的の情報を取得することができます。
面倒なスクレイピングコードを自作しなくても良いというのは本当に便利ですよね。
しかし、xpathはHTMLコード全文の構造、構成を理解して正しく記述する必要があります。Webサイトは不定期にフォーマットが更新されてしまうこともあるため、いちいちそんな調査をしていたら時間がかかってしまいます。
ここではGoogle ChromeというWebブラウザの拡張機能を使うことによって、「自動的にxpathを取得する方法」の習得を目指します!
ちなみに、僕はPython特化型学習サービス「PyQ(パイキュー)」で基礎を覚えました。体系的にPythonプログラミングやWebスクレイピングを覚えたい方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」の記事をご覧下さい。
XPath Helperのインストール方法
Chromeを立ち上げてウェブストアに行く
まずはお持ちのGoogle Chromeを立ち上げて、ブラウザ左上にある「アプリ」をクリックします。
さらに、ページが変わった先で「ウェブストア」というアイコンをクリックします。

もしくはChrome上で以下のURLを直接入力してウェブストアのページに行って下さい。
Chromeウェブストアhttps://chrome.google.com/webstore/category/extensions?utm_source=chrome-ntp-icon
以下のウェブストアのページが表示されます。
XPath HelperをChromeに追加する
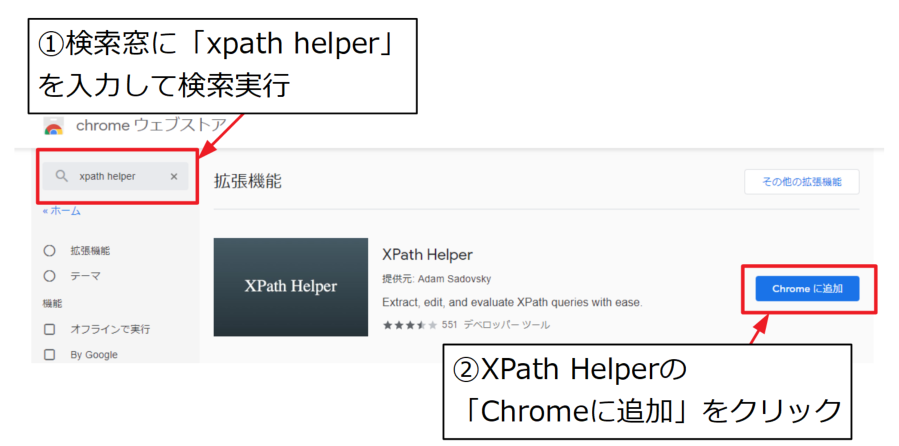
次は検索窓に「xpath helper」と打ち込み検索を実行します。するとXPath Helper(提供元がAdam Sadovsky)が検索にヒットするので、「Chromeに追加」をクリックします。
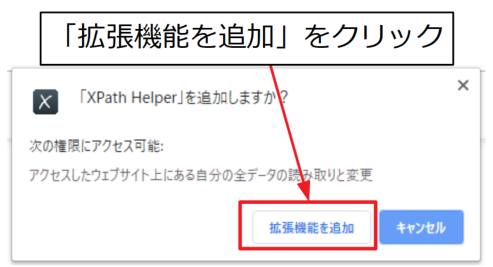
ポップアップウィンドウで追加するかどうかを聞かれた場合は、「拡張機能を追加」をクリックします。
Chromeを再起動する
追加が終了したら、ブラウザの右上にXのアイコンが追加されています。
XPath Helperの機能を使うために、一度ブラウザを再起動して下さい。
以上でインストールまでの説明は終了です。続いてXPath Helperの使い方を説明していきます。
XPath Helperの使い方
Google Chromeで任意のWebページを開く
ではサンプルとして当ブログの人気記事である「Pythonで音のSTFT計算を自作!スペクトログラム表示する方法」のURLを使って、実際にxpathを取得してみましょう。
このページの中の少しスクロールした所にある見出し、「STFT(短時間フーリエ変換)とは?」の下の文章のxpathを調べましょう。

XPath Helperを起動してShiftキーで取得
xpathの取得方法はとても簡単です。
まず、①「XPath Helper」を起動させます。
あとは②xpathを取得したい要素上で「Shiftを押す」だけです。
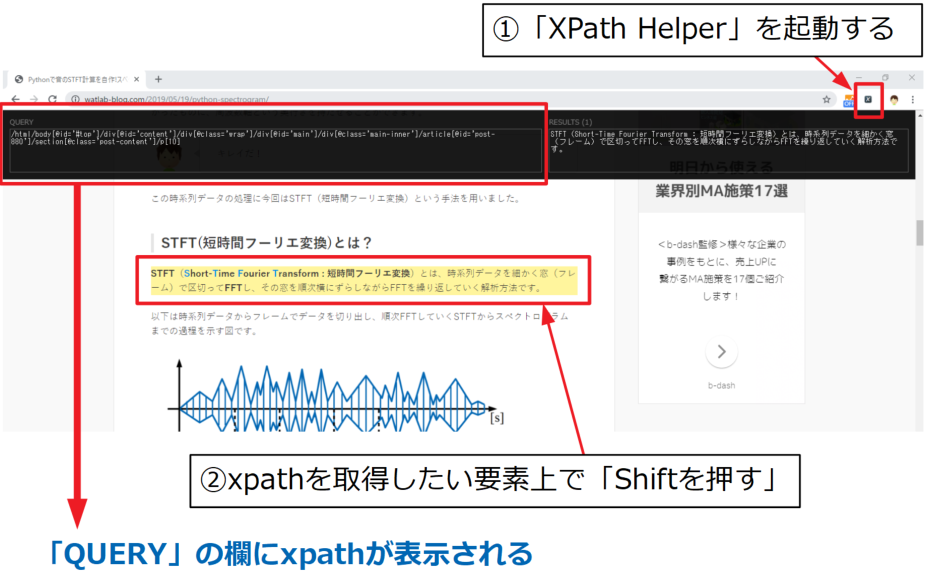
するとChromeブラウザの上の方にある「QUERY」の欄にxpathがフルパスで表示されています。
結果はこの通り。
|
1 |
/html/body[@id='#top']/div[@id='content']/div[@class='wrap']/div[@id='main']/div[@class='main-inner']/article[@id='post-880']/section[@class='post-content']/p[10] |
では、これが本当に使えるxpathかどうかPythonで確認してみましょう!
XPath Helperを使わないでxpathを取得する方法
実はChrome標準でもxpathを取得することができる
実はこの記事を公開するまではこの先に書いてある内容がXPath Helperの機能であると勘違いしていました!
Twitterに寄せられた親切な方からの返信で気付くことができました。
XPath Helperでxpathを調べる簡単な方法は、上で紹介したような内容なのですが、以下の方法でも調べることができます!
調査不足でしたね!
この方法はこの方法で結構簡単なので、本記事では別解として残しておこうと思います。ご興味ある方は以下の説明をお読みください。
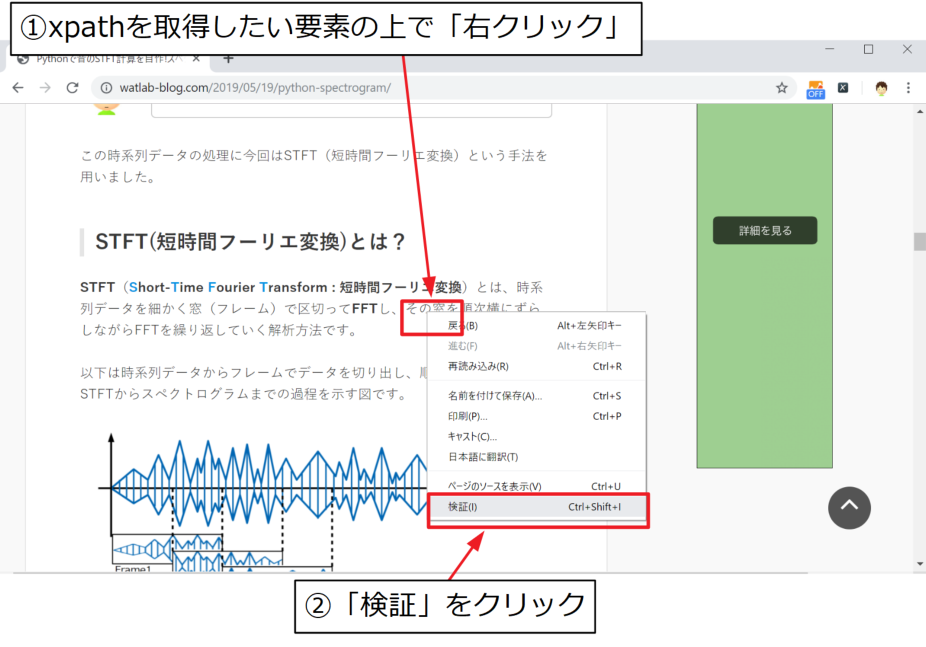
任意の要素の上で右クリック「検証」
まずはxpathを取得したい要素の上で「右クリック」をして、さらに「検証」をクリックします。
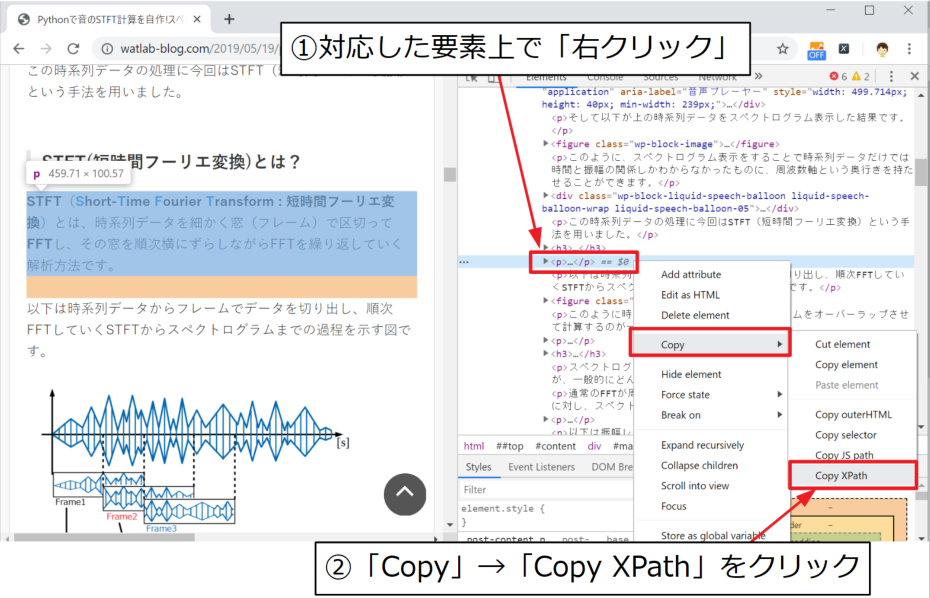
xpathをクリップボードにコピー
するとHTMLコードが表示されますので、対応する要素(今回の文章は「段落」なのでp要素)の上で「右クリック」、「Copy」→「Copy XPath」とクリックすることでクリップボードにxpathがコピーされます。
サンプルページで取得したxpathを、適当なテキストエディタに貼り付けてみると、以下の結果を得ます。
|
1 |
//*[@id="post-880"]/section/p[10] |
先ほどはフルパスが取得できていましたが、「//*」で始まる短縮パスになっている違いがありますね。
取得したxpathを使ってPythonでスクレイピングするコード
先ほど取得したxpathを使ってPythonでWebスクレイピングをしてみましょう。コードの内容は「Python/Seleniumで便利なxpath検索をする方法!」と全く同じで、URLとxpathを今回の物にしただけです。
ただ、注意点としては、前回は「xpath=" "」としていましたが、今回は取得したxpathに「"」が含まれているため、「xpath=' '」と変更しています。
この変更をしないと構文エラーになるのでご注意下さい。
xpathはXPath Helperで取得したフルパスでも、Chrome標準状態で取得する短縮パスでも構いません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://watlab-blog.com/2019/05/19/python-spectrogram/') time.sleep(3) # 3秒間待機 # xpathを定義してfind関数で要素をリストで取得 xpath = '//*[@id="post-880"]/section/p[10]' # ChromeのXPath Helperで取得 elems = driver.find_elements_by_xpath(xpath) # 取得した要素を1つずつ表示 for elem in elems: print(elem.text) driver.quit() # ブラウザを閉じる |
このコードを実行すると、Google Chromeが自動で立ち上がり、最後にコンソールに以下の文章が表示されます。
「STFT(Short-Time Fourier Transform : 短時間フーリエ変換)とは、時系列データを細かく窓(フレーム)で区切ってFFTし、その窓を順次横にずらしながらFFTを繰り返していく解析方法です。」
元の文章には色変更や強調のHTMLタグがふんだんに使われていましたが、見事に文章だけが抽出され、その他は削ぎ落されていますね。これぞスクレイピング!
まとめ
本記事ではGoogle Chromeの拡張機能であるXPath Helperのインストールと使い方、Pythonによる検証までを紹介しました。
Webスクレイピングに便利なxpathは自分で記述すると非常にやっかいな存在でしたが、XPath Helperを使うことで簡単に、しかも自動的にxpathを生成することができました。
現代は引き算の開発が主流と言われています!車輪の再発明を避けるために、世の中にある便利なツールは是非どんどん使いましょう!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント