
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

PythonのSeleniumでWebスクレイピングを行う時、HTMLをどう効率良く分析するかが分析の焦点になります。xpathをトリガにした検索方法を使うと非常に簡単に目的の情報を抽出することができます。ここではseleniumのxpathによる検索方法を紹介します。
こんにちは。wat(@watlablog)です。
Seleniumを使ったWebスクレイピングを深堀していきます。ここではSeleniumのxpath検索について説明します!
当ブログで紹介している内容はWebスクレイピングの一例に過ぎません。僕はPython特化型学習サービス「PyQ(パイキュー)」で基礎を覚えました。体系的にPythonプログラミングやWebスクレイピングを覚えたい方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」の記事をご覧下さい。
HTMLの特定の情報をxpathで指定する考え方
HTMLをツリー形式で捉える
xpathとは、ツリー構造を持ったXML(eXtensible Markup Language)文書の特定の情報までのルートのことを意味します。
HTML(HyperText Markup Language)もXML文書の一種であり、Markup(目印を付ける)の意味通り、文章がそれぞれ見出し、表、段落、画像…と各要素が何の意味を持っているのかが明示された文章です。
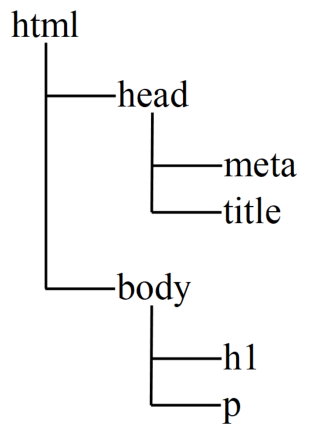
例として、以下のHTMLで書かれた文章を見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
<!DOCTYPE html> <html lang="ja"> <head> <meta http-equiv="content-type" charset="utf-8"> <title>タイトル</title> </head> <body> <h1>タイトル</h1> <p>テストページ</p> </body> </html> |
このHTMLで書かれたページは当WATLABブログのサーバー上にも用意してみました。⇒sample.html
この例文の構造をツリー形式で捉えると以下の図のように考えることができます。
xpathの書き方(基礎)
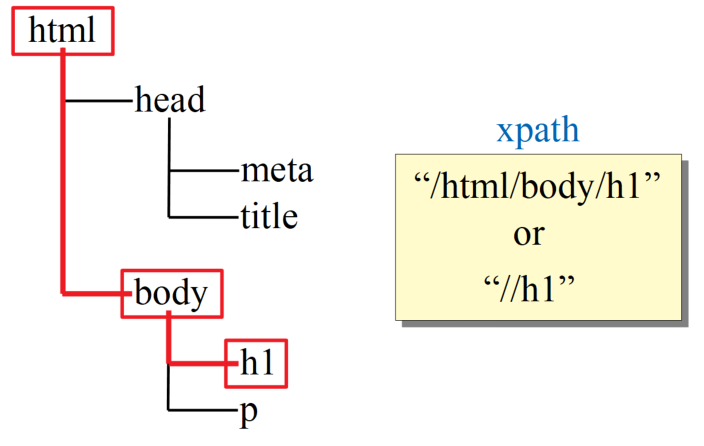
ここで、例えば「h1」の見出し要素にある情報を抽出しようと考えた場合、xpathは以下の図のルートを通ります。
h1までのルートをスラッシュ「/」で区切った「/html/body/h1」というのがxpathで、「//h1」と前を省略して書くこともできます。このようなパスはロケーションパスと呼ばれます。
今回はxpathを使った検索の基礎を理解するために、このレベルの基本例題をSeleniumでスクレイピングしてみます。
Python/Seleniumでxpathを使ったHTMLスクレイピングのコード
Seleniumのxpathを使ってHTML内のh1要素情報を取得するコードを以下に示します。
尚、コード内ではChromeDriverとSeleniumは既にインストールしたものとして話を進めていますが、まだインストールをしていない方は「Python/ChromeDriverインストールとパスの通し方」と「Python/SeleniumでChrome自動Google検索」の記事を一度ご確認下さい。
以下のコードはこの2つの記事で使っているコードとxpath部分以外はほぼ同じです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://watlab-blog.com/wp-content/uploads/2019/08/sample.html') time.sleep(3) # 3秒間待機 # xpathを定義してfind関数で要素をリストで取得 xpath = "/html/body/h1" elems = driver.find_elements_by_xpath(xpath) # 取得した要素を1つずつ表示 for elem in elems: print(elem.text) driver.quit() # ブラウザを閉じる |
実行するとGoogle Chromeが自動で立ち上がって、以下のように「タイトル」というh1要素の中身がコンソールに表示され、目的の情報が取得されていることがわかると思います。
|
1 |
タイトル |
今回は「.find_elements_by_xpath」を用いて検索をしましたが、「.find_element_by_xpath」とelementにsを付けないで1つだけ検索することもできます。
h1要素は通常HTML内に1つだけだと思いますが、他にもリンク要素や段落要素等、同じHTML内に複数の同一要素がある場合はelementsで検索しておけば全て抽出することができます。
まとめ
今回は一番基礎的な内容でxpathを「使ってみた」という記事です。
xpathを使うことで、面倒なHTMLスクレイピングコードを自作しなくても良いということがわかったと思います。
過去、当ブログでは「Pythonテキスト処理!文章中からHTMLタグを取り除いてみた」でスクレイピングコードを自作してみましたが、.find_element関数を使えばそんなものは必要無いくらい便利でした。
xpathの基礎は理解した…かな?xpathにはもっと指定の仕方が沢山あるそうなので、次回から深堀をしていきましょう!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント