
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
PythonのディープラーニングフレームワークであるPyTorchはネットワークモデルをモジュール化して使うとわかりやすいコードになります。ここでは初心者向けにクラスの使い方と、簡単な線形ネットワークを例にモジュール化の方法を紹介します。
こんにちは。wat(@watlablog)です。ここではプログラミング初心者向けにクラスを使ったPyTorchネットワークモデルのモジュール化を説明します!
本記事の対象者
他の人の書いたPyTorchコードを読みたい人…
ニューラルネットワーク、機械学習関係の参考コードはGitHub等でよく公開されていますが、プロの方は多くがネットワークをモジュール化(クラス化)した書き方でコードを書いていらっしゃいます。
有名モデル(VGG, ResNetとか)を始めとした他の人のネットワークモデルを参考にする時に、そもそもクラスベースで書いてあると、読み方を知らないともう退場するしかありません。
そのため、本記事は他の人の書いたPyTorchコードを読みたい人向けです。
Pythonのクラス記述を遠ざけて来た人…
ここではそもそもPythonのクラスの書き方が微妙、できれば使いたくない…という方を対象にしています。
かく言う僕もできればブログではクラス表記を避けたいとずっと思っていました。
当WATLABブログの記事はTips的な内容なので、そもそもクラス設計をする程のメリットは無く、クラス表記するとかえって初心者が記事を去ってしまうという懸念がありました。
大抵の内容はdef文があれば綺麗に書けますし、ちょっとしたコードであればそれで可読性も十分でしょう。
クラスのメリットは大規模なプログラムになった時に変数の数を減らす事ができたり、関数をまとめておく事でわかりやすくなったりする所にあります。
Pythonのクラスやオブジェクト指向の考え方、書き方については「Pythonのクラスの使い方とオブジェクト指向の考え方を理解する」をご覧下さい。
動作環境
このページのプログラムは以下のPC&Python環境で動作検証を行なっています(環境変更が面倒でずっとアップデートしていませんね…)。
| Windows | OS | Windows10 64bit |
|---|---|---|
| CPU | 2.4[GHz] | |
| メモリ | 4[GB] |
| Mac | OS | macOS Catalina 10.15.7 |
|---|---|---|
| CPU | 1.4[GHz] | |
| メモリ | 8[GB] |
| Python | Python 3.7.7 |
|---|---|
| PyCharm (IDE) | PyCharm CE 2020.1 |
| PyTorch | torch==1.5.1 |
PyTorchの線形回帰ネットワークをモジュール化するコード
それではPyTorchネットワークのモジュール化(クラスで書く)について、順を追って説明していきます。
classを使わないで書いたコードとして「PyTorchのネットワークモデルを使って線形回帰をする方法」の物を題材とします。
import文
今回の例では以下のimportを行います。torch以外に個別にnnとoptimを書いているのは単純に毎回torch.nn等と書かなくて良くなるというだけです。
|
1 2 3 4 |
import torch from torch import nn, optim import numpy as np from matplotlib import pyplot as plt |
nn.Moduleを継承したclassを作成
今回、まずはLinearRegression()というclassを作ります。クラスは単語の区切りを大文字で分け、関数の場合は小文字とアンダーバーで分けるのが一般的な命名規則のようです。以下にクラス部分のコードを示します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 線形回帰ネットワークのclassをnn.Moduleの継承で定義 class LinearRegression(nn.Module): # コンストラクタ(インスタンス生成時の初期化) def __init__(self, in_features, out_features, bias=False): super().__init__() self.linear = nn.Linear(in_features, out_features, bias=bias) # メソッド(ネットワークをシーケンシャルに定義) def forward(self, x): y = self.linear(x) return y |
classの引数にnn.Moduleをとる事で、継承を行います。これでPyTorchのネットワークモデル全てを利用可能になります。
次にコンストラクタを設定します。クラスは定義したままではただの設計図であり、インスタンス(実体)を生成して使います。コンストラクタにはインスタンス生成時に最初に実行されるコードを書きます。
継承は色々なやり方がありますが、Python3ではsuper().__init__()を使って継承する事が推奨されています。僕を含めクラス初心者にこの書き方はかなり特殊と感じてしまうと思いますが、今はおまじないのように書いておきます。
最後にメソッドを設定していきます。メソッドにはforward()を設定し、ここにネットワークモデルをシーケンシャル(順番に実行されるように)に登録していきます。
○○.forward()とこのメソッドを実行する事でニューラルネットワークが順伝播するイメージです。
この例では線形回帰ネットワーク1つで説明するのでこれだけですが、このforwardメソッドに活性化関数や中間層を追加していきディープニューラルネットワークを作るのがディープラーニングのモデルとなります。
トレーニング用の関数を作成
次にトレーニング用の関数を定義します。内容は「PyTorchのネットワークモデルを使って線形回帰をする方法」で書いた物と同一です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# トレーニング関数 def train(model, optimizer, E, iteration, x, y): # 学習ループ losses = [] for i in range(iteration): optimizer.zero_grad() # 勾配情報を0に初期化 y_pred = model(x) # 予測 loss = E(y_pred.reshape(y.shape), y) # 損失を計算(shapeを揃える) loss.backward() # 勾配の計算 optimizer.step() # 勾配の更新 losses.append(loss.item()) # 損失値の蓄積 print('epoch=', i+1, 'loss=', loss) return model, losses |
グラフ確認まで含めた全コード(コピペ用)
コピペで動作できるようにグラフ確認まで含めた全コードを以下に示します。
ネットワークをクラスでモジュール化していますが、トレーニング(学習)は別途関数で作成、最適化アルゴリズムや損失関数は関数の外で設定して引数として設定値を渡すようにしました。
これらをクラスに含めた方が良いのか、それとも外で設定した方が良いのかはまだわかっていません(書籍等でもこのように作っているようなので真似しました)。
また、前回の記事では回帰係数(model.parameter)から回帰直線を描いていましたが、学習したネットワークモデルは別途テストデータを使って出力を得るという使い方が機械学習の基本と思うため、今回は回帰係数を使わずにネットワークモデルにデータを渡して直線を描画するという内容にしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
import torch from torch import nn, optim import numpy as np from matplotlib import pyplot as plt # 線形回帰ネットワークのclassをnn.Moduleの継承で定義 class LinearRegression(nn.Module): # コンストラクタ(インスタンス生成時の初期化) def __init__(self, in_features, out_features, bias=False): super().__init__() self.linear = nn.Linear(in_features, out_features, bias=bias) # メソッド(ネットワークをシーケンシャルに定義) def forward(self, x): y = self.linear(x) return y # トレーニング関数 def train(model, optimizer, E, iteration, x, y): # 学習ループ losses = [] for i in range(iteration): optimizer.zero_grad() # 勾配情報を0に初期化 y_pred = model(x) # 予測 loss = E(y_pred.reshape(y.shape), y) # 損失を計算(shapeを揃える) loss.backward() # 勾配の計算 optimizer.step() # 勾配の更新 losses.append(loss.item()) # 損失値の蓄積 print('epoch=', i+1, 'loss=', loss) return model, losses # テスト関数 def test(model, x): y_pred = model(x).data.numpy().T[0] # 予測 return y_pred # グラフ描画関数 def plot(x, y, x_new, y_pred, losses): # ここからグラフ描画------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(9, 4)) ax1 = fig.add_subplot(121) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(122) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('x') ax1.set_ylabel('y') ax2.set_xlabel('Iteration') ax2.set_ylabel('E') # スケール設定 ax1.set_xlim(-10, 20) ax1.set_ylim(0, 30) ax2.set_xlim(0, 1000) ax2.set_ylim(0.1, 100) ax2.set_yscale('log') # データプロット ax1.scatter(x, y, label='dataset') ax1.plot(x_new, y_pred, color='red', label='PyTorch result', marker="o") ax2.plot(np.arange(0, len(losses), 1), losses) ax2.text(600, 30, 'Loss=' + str(round(losses[len(losses)-1], 2)), fontsize=16) ax2.text(600, 50, 'Iteration=' + str(round(len(losses), 1)), fontsize=16) # グラフを表示する。 ax1.legend() fig.tight_layout() plt.show() plt.close() # ------------------------------------------------------------------- # トレーニングデータ x = np.random.uniform(0, 10, 100) # x軸をランダムで作成 y = np.random.uniform(0.2, 1.9, 100) + x + 10 # yを分散した線形データとして作成 x = torch.from_numpy(x.astype(np.float32)).float() # xをテンソルに変換 y = torch.from_numpy(y.astype(np.float32)).float() # yをテンソルに変換 X = torch.stack([torch.ones(100), x], 1) # xに切片用の定数1配列を結合 # テストデータ x_test = np.linspace(-5, 15, 15) # x軸を作成 x_test = torch.from_numpy(x_test.astype(np.float32)).float() # xをテンソルに変換 X_test = torch.stack([torch.ones(15), x_test], 1) # xに切片用の定数1配列を結合 # ネットワークのインスタンスを生成 net = LinearRegression(in_features=2, out_features=1) # 最適化アルゴリズムと損失関数を設定 optimizer = optim.SGD(net.parameters(), lr=0.01) # 最適化にSGDを設定 E = nn.MSELoss() # 損失関数にMSEを設定 # トレーニング net, losses = train(model=net, optimizer=optimizer, E=E, iteration=1000, x=X, y=y) # テスト y_pred = test(net, X_test) # グラフ描画 plot(x, y, X_test.data.numpy().T[1], y_pred, losses) |
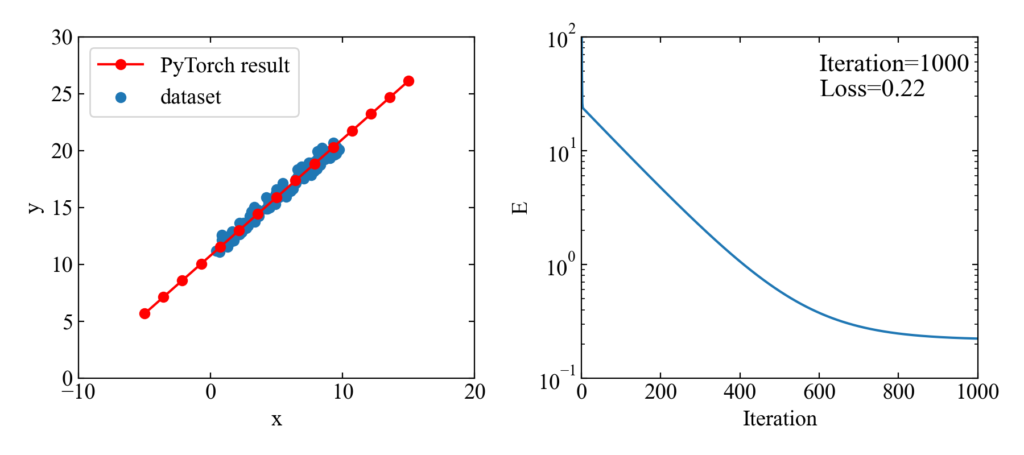
以下がコード実行結果です。モジュール化したネットワークモデルでも損失がしっかりと低下し、ネットワークに通したデータは見事回帰直線を描きました。
まとめ
「PyTorchのネットワークモデルを使って線形回帰をする方法」で初歩的なPyTorchによる回帰の方法を学び、本記事でネットワークのモジュール化を行いました。
モジュール化はclassでnn.Moduleの継承を行いましたが、この方法であればネットワークの層構造がforwardメソッドにまとまるので可読性が上がると考えられます。
まだ線形回帰しかやっていませんが、仕組みを学ぶのにはちょうど良いレベルと思っています。
線形ネットワークを例題にPyTorchネットワークモデルのモジュール化を行いました!久々にクラスを使った感覚です!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント