
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

科学技術計算では波形からピークを読み取る必要性に迫られます。Pythonではscipyのsignal.argrelmaxを使って簡単にピーク検出が可能です。ここではFFT波形を例に自動でピーク検出する方法を紹介します。
こんにちは。wat(@watlablog)です。ここではFFT波形からピークを自動検出する方法を紹介します!
ピーク検出の勘所
FFT波形はピークの周波数・振幅情報が重要
フーリエ変換して得られる周波数波形は、周期的な振動成分の情報を明らかにします。
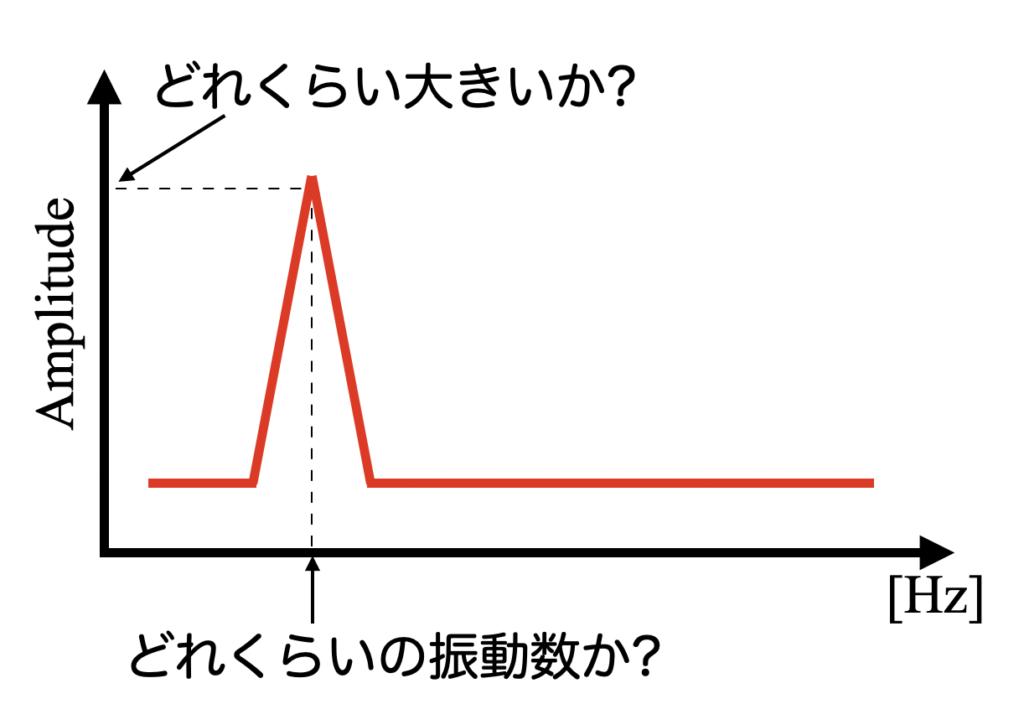
以下の図に周波数波形の例を示します。このようにある周波数で振動している現象を計測した場合、ピーク(Peak)が観測されます。
このピークには、どれくらいの振動数(周波数成分)、大きさ(振幅成分)で振動しているかといった情報を含んでおり、計測結果から現象を推定するのに役立てることができます。
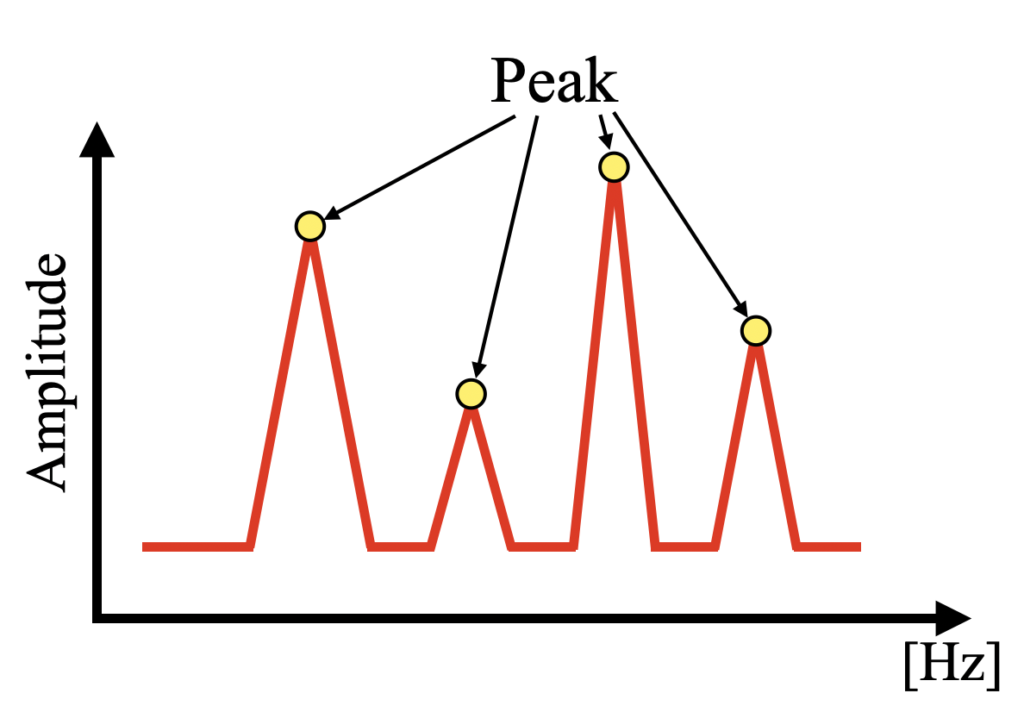
大抵の場合、ピークは1つだけではありません。ピーク検出アルゴリズムがあれば下図のように複数のピークを一度に検出することができ、振幅成分と周波数成分を自動記録していくことが出来ます。
一度だけの実験や解析であれば、手作業で記録しても良いですが、回数が増えてくると大変な手間です!大量作業はプログラムに任せましょう!
ピーク検出はノイズ対策が必要
ピークを検出するには課題もあります。多くの実験データは外乱によるノイズを含みます。
ノイズを含むデータをフーリエ変換した場合、下図のように本来検出したいピークとは別に誤検出してしまうピークもあります。
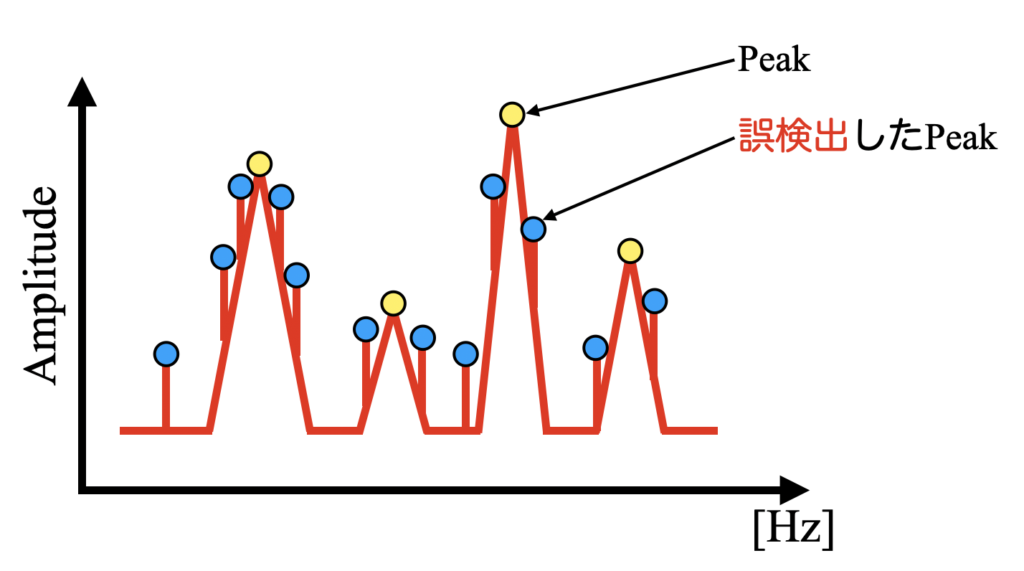
感度良くピークを検出してしまうとこのように誤検出ピークが多くなり、これでは情報の整理がままなりません。
結局手作業で選別するならピークを検出した意味がない!
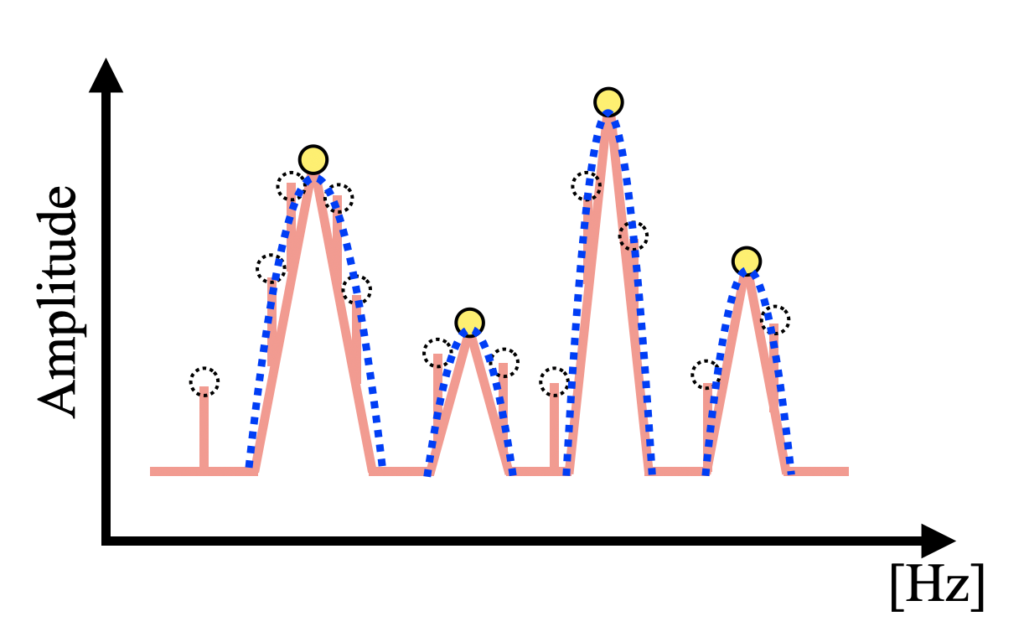
そのため、通常はある幅をもってピークを検出することで感度を鈍らせるノイズ対策処理を行います(下図はイメージ図)。
ピーク検出は元波形の微分波形が0になる(元波形の傾きが0)点を探すというアルゴリズムを基本にしており、上記ノイズ対策のために多項式近似を使ったり、上側や下側のピークのみ検出するために方向を特定する処理が入っていたりと、やや複雑です。
汎用的なピーク検出関数を自作するのは出来なくもないですが(…多分)、Pythonには自分で微分とかしなくても良いピーク検出のメソッドが既にあるため、このページではその方法を紹介するのみとします。
scipy.signal.argrelmaxを使う
scipyのsignalに入っているargrelmaxを使えば簡単にピーク検出が可能です。
新しい外部ライブラリを利用する時は、まず最初に1次情報として公式ドキュメントを確認する事をオススメします。そのため公式ドキュメントへのリンクを以下に示します。
公式ドキュメント:scipy.signal.argrelmax
それでは以下より実際にPythonのscipy.signal.argrelmaxを使ってピーク検出するコードの例を紹介していきます。
Pythonでピーク検出するコード
今回はサンプルの時間波形をフーリエ変換し、周波数波形から任意個数のピーク情報を抽出するプログラムを書いていきます。
import文
importは配列処理、演算でおなじみのnumpy、ピーク検出とフーリエ変換用のscipy、グラフで確認するためのmatplotlibを使います。
|
1 2 3 4 |
import numpy as np from scipy import signal from scipy import fftpack from matplotlib import pyplot as plt |
フーリエ変換する関数
サンプル波形を以下のコードで作成します。サンプル波形はsignal.sawtoothで基本周波数1[Hz]ののこぎり波(高調波が綺麗に出るため)を作成し、その波形にnp.random.normalで生成したホワイトノイズを重畳させています。
のこぎり波については「Pythonでのこぎり波を生成!次数の高調波成分を見てみた」をご覧下さい。
ここではフーリエ変換については詳しく語りませんが、気になる方は「信号処理」カテゴリのフーリエ変換の項目をご確認下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# フーリエ変換して複素スペクトル、振幅、周波数を出力する関数 def fft(y, dt): spec = fftpack.fft(y) # フーリエスペクトル(複素数) freq = fftpack.fftfreq(len(spec), d=dt) # 周波数軸を生成 amp = np.sqrt(spec.real ** 2 + spec.imag ** 2) / (len(spec)/2) # 振幅を計算 return spec, amp, freq # サンプル波形を生成 dt = 0.0001 t = np.arange(0, 10, dt) noise = 1 * np.random.normal(loc=0, scale=1, size=len(t)) y = signal.sawtooth(2 * np.pi * 1 * t) + noise # フーリエ変換する spec, amp, freq = fft(y, dt) |
ピーク検出する関数
以下が本題のピーク検出関数です。findpeaks(MATLABと同じにしてみました)という名前のdef関数で作成しており、入力波形の横軸x、縦軸の値y、抽出するピーク数n、ピーク感度に関する幅(orderとも呼ぶ)wを引数とし、returnとしてピークの位置index、ピークの縦軸値peaksを返します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 波形(x, y)からn個のピークを幅wで検出する関数(xは0から始まる仕様) def findpeaks(x, y, n, w): index_all = list(signal.argrelmax(y, order=w)) # scipyのピーク検出 index = [] # ピーク指標の空リスト peaks = [] # ピーク値の空リスト # n個分のピーク情報(指標、値)を格納 for i in range(n): index.append(index_all[0][i]) peaks.append(y[index_all[0][i]]) index = np.array(index) * x[1] # xの分解能x[1]をかけて指標を物理軸に変換 return index, peaks |
この関数は周波数波形だけでなく、xとyに時間軸と値を渡せば時間波形でも機能します。
関数は以下のコードで実行します。
|
1 2 |
# ピーク検出する index, peaks = findpeaks(freq, amp, n=100, w=2) |
グラフ表示までの全コード(コピペ用)
コピペ用に全コードを載せておきます。ここではグラフ表示まで載せているので、このコードを丸ごとコピペすれば動作すると思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import numpy as np from scipy import signal from scipy import fftpack from matplotlib import pyplot as plt # フーリエ変換して複素スペクトル、振幅、周波数を出力する関数 def fft(y, dt): spec = fftpack.fft(y) # フーリエスペクトル(複素数) freq = fftpack.fftfreq(len(spec), d=dt) # 周波数軸を生成 amp = np.sqrt(spec.real ** 2 + spec.imag ** 2) / (len(spec)/2) # 振幅を計算 return spec, amp, freq # 波形(x, y)からn個のピークを幅wで検出する関数(xは0から始まる仕様) def findpeaks(x, y, n, w): index_all = list(signal.argrelmax(y, order=w)) # scipyのピーク検出 index = [] # ピーク指標の空リスト peaks = [] # ピーク値の空リスト # n個分のピーク情報(指標、値)を格納 for i in range(n): index.append(index_all[0][i]) peaks.append(y[index_all[0][i]]) index = np.array(index) * x[1] # xの分解能x[1]をかけて指標を物理軸に変換 return index, peaks # サンプル波形を生成 dt = 0.0001 t = np.arange(0, 10, dt) noise = 1 * np.random.normal(loc=0, scale=1, size=len(t)) y = signal.sawtooth(2 * np.pi * 1 * t) + noise # フーリエ変換する spec, amp, freq = fft(y, dt) # ピーク検出する index, peaks = findpeaks(freq, amp, n=100, w=6) # ここからグラフ描画------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(8, 5)) ax1 = fig.add_subplot(211) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(212) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Time [s]') ax1.set_ylabel('Amp.') ax2.set_xlabel('Frequency [Hz]') ax2.set_ylabel('Amp.') # スケール設定。 ax2.set_xlim(0, 10) ax2.set_yscale('log') # データプロットの準備とともに、ラベルと線の太さ、凡例の設置を行う。 ax1.plot(t, y, label='sample', lw=1) ax1.legend() ax2.plot(freq[:int(len(freq)/2)], amp[:int(len(freq)/2)], label='sample', lw=1) ax2.scatter(index, peaks, label='peaks', color='red') ax2.legend() # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- |
実行結果
実行結果を説明していきます。ここではfindpeaks関数に渡すw値による違いを見ていきます。
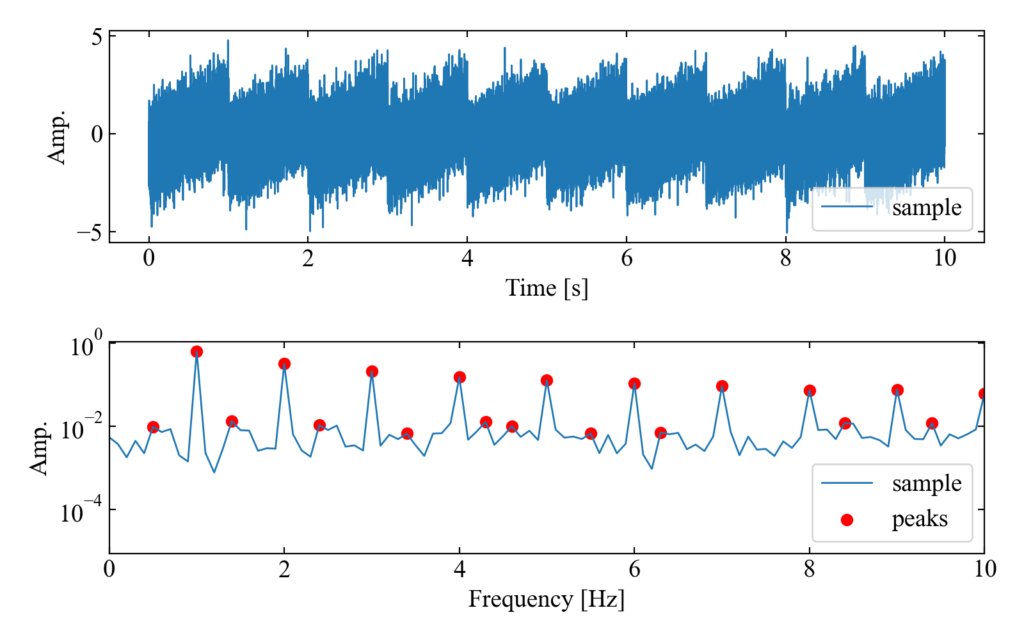
w=2
まず全コードに載せているようにw=2の結果ですが、以下の図のように、周波数波形(下図)では基本周波数とその倍数成分(高調波)以外にも多くのピークが誤検出されていることがわかりました。
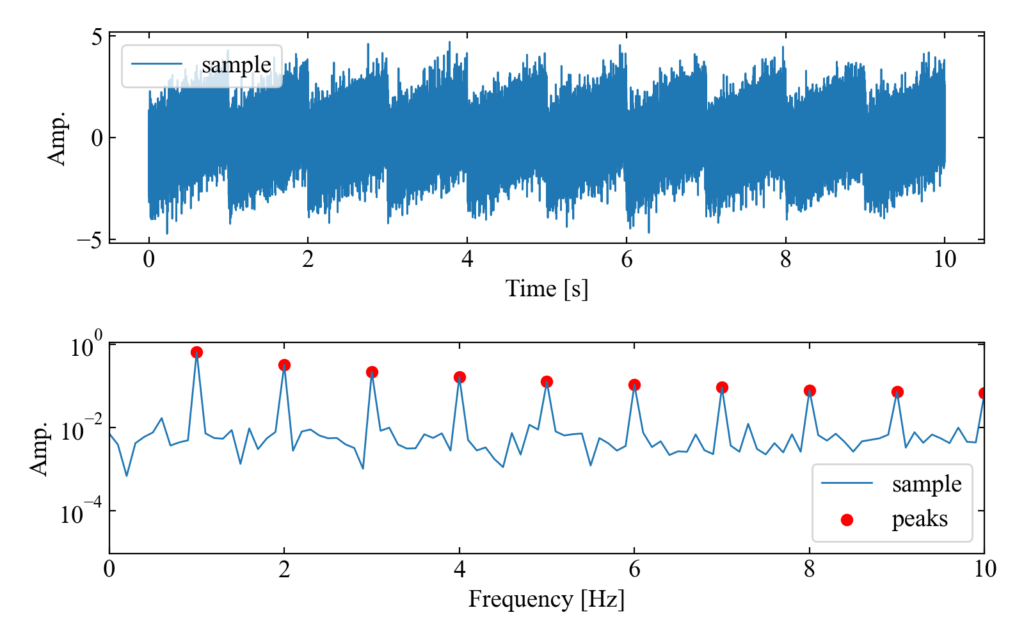
w=6
次にw=6の結果です。この結果は基本周波数とその高調波成分のみがピークとして検出されています。これで目的達成です。
エラー処理(ピーク検出個数の不一致)
このコードにはまだ穴があり、例えばn=10000といった大きなピーク検出数で実行すると「IndexError: index 7840 is out of bounds for axis 0 with size 7840」というエラーが出ます。
このエラーはindexとpeaksをappendする際、forループ内でindex_all[0][i]と値を抽出する部分で発生しており、以下のコード内コメントで「# 〜エラー処理」と記載している内容を追記する事で解消されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 波形(x, y)からn個のピークを幅wで検出する関数(xは0から始まる仕様) def findpeaks(x, y, n, w): index_all = list(signal.argrelmax(y, order=w)) # scipyのピーク検出 index = [] # ピーク指標の空リスト peaks = [] # ピーク値の空リスト # n個分のピーク情報(指標、値)を格納 for i in range(n): # n個のピークに満たない場合は途中でループを抜ける(エラー処理) if i >= len(index_all[0]): break index.append(index_all[0][i]) peaks.append(y[index_all[0][i]]) # 個数の足りない分を0で埋める(エラー処理) if len(index) != n: index = index + ([0] * (n - len(index))) peaks = peaks + ([0] * (n - len(peaks))) index = np.array(index) * x[1] # xの分解能x[1]をかけて指標を物理軸に変換 return index, peaks |
抽出できないインデックスが来たら強制的にforループを抜ける…という処理です。
ちなみに2つ目のエラー処理である「# 個数が足りない分を0で埋める」ですが、これはこのページに記載のコードでは無くても動作します。しかし、「Pythonでスペクトログラムからピーク値を任意数抽出する方法」で必要になりますので、ここでも追記しておきます。
おまけ:負のピークを検出する方法
実はargrelminを使うと負のピーク(下側に凸のピーク)を検出することが可能です。
以下のdef関数はdirectionという引数を使ってargrelmaxを使った正のピーク検出とargrelminを使った負のピーク検出を選択できるように元の関数を改良したものです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 波形(x, y)からn個のピークを幅wで検出する関数(xは0から始まる仕様) def findpeaks(x, y, n, w, direction): print(direction) if direction == '-': index_all = list(signal.argrelmin(y, order=w)) # scipyのピーク検出(正のピーク) elif direction == '+': index_all = list(signal.argrelmax(y, order=w)) # scipyのピーク検出(負のピーク) index = [] # ピーク指標の空リスト peaks = [] # ピーク値の空リスト # n個分のピーク情報(指標、値)を格納 for i in range(n): index.append(index_all[0][i]) peaks.append(y[index_all[0][i]]) index = np.array(index) * x[1] # xの分解能x[1]をかけて指標を物理軸に変換 return index, peaks |
以下のコードのようにdirectionに文字列として「"+"」を渡せばargrelmaxによる正のピーク検出、「"-"」を渡せばargrelminによる負のピーク検出を行うようになります。
|
1 2 |
# ピーク検出する index, peaks = findpeaks(freq, amp, n=100, w=6, direction='-') |
以下が実行結果です。サンプル波形は負のピークがノイズしかありませんが、しっかり下側に凸のピークを検出していることが確認できました。
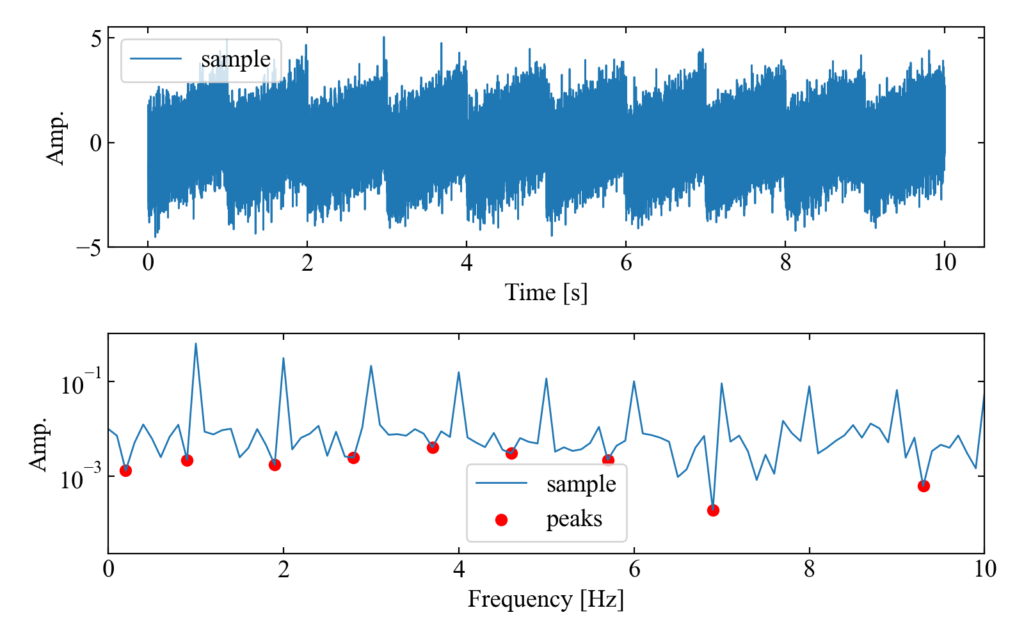
さらにノイズを軽減するためには?
ノイズをどんな状況でも取り切るw(argrelmax/argrelminではorder)の値はありません。実際のデータで最適な値を決めるべきハイパーパラメータです。
実際の計測ではノイズの度合いも毎回変わってしまうこともよくあることで、以外と自動化する時にはノイズ対策が難しくなります。
しかし、状況によってはさらにノイズを軽減させることも十分可能です。
計測対象が回転振動であれば、回転数のデータを使ってピーク探索範囲を限りなく狭めることができたり(ピーク検出アルゴリズムが必要無いくらいに)、ノイズの原因が高周波成分や低周波成分といった特定のものとわかっていれば、フィルタ処理でノイズを軽減させた波形に対してピーク検出を使うといった方法が有効です。
ローパスフィルタ、ハイパスフィルタ、バンドパスフィルタ、バンドストップフィルタについては、「信号処理」カテゴリのフィルタの項目を是非確認してみて下さい。
まとめ
本ページでは周波数波形におけるピークの重要性とピーク検出の概要、ノイズ処理の必要性を説明しました。
また、実際にPythonを使ったコードでサンプル波形のピーク検出を行い、正のピーク、負のピークが抽出されることと、ノイズの軽減に関するパラメータの有効性を確認しました。
実際の現場で使うためには、対象の波形の特徴を掴んだノイズ対策を行う必要がありますが、scipyを使えば簡単にピーク検出ができることがわかりました。
ピーク検出も信号処理の基本!またまた新しい武器を獲得しました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
はじめまして。数年前の記事にすみません
ピーク検出において、色々ノイズに悩まされていたのでとてもためになりました。
今回、使ったサンプル波として、関数を用いられているのですが、CSVから取り込んだデータを用いる場合はどのようにすればいいのでしょうか。
試しに関数yの部分を、pd.read_csvのデータに置き換えてみたのですが、うまくいかず…
エラーとしては、
KeyError: ‘ALIGNED’
また、データフレームを配列に変えてみても、
IndexError: index 64 is out of bounds for axis 0 with size 64
というエラーが吐かれてしまいます。エラーの対処法として間違っているのかもしれませんが、もしやり方をご存じてしたらご教示いただけたら幸いです
ご訪問ありがとうございます。
csvを読み出すコードはPandasならばpd.read_csvで良いと思います。
csvのエンコードがSHIFT-JISになっている場合は以下のコードのようにencodingを指定する必要があります。
df = pd.read_csv(in_file, encoding=’SHIFT-JIS’)
このあたりはご確認されましたでしょうか?
もしかしたらこちらの記事が参考んになるかもしれません。
「https://watlab-blog.com/2021/08/05/csv-digital-filter/」