
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

JDLAが主催するディープラーニングG検定は試験時にGoogle検索や書籍の参照がOKなWeb検定です。ここでは筆者が受験時に素早く用語の参照ができるようメモを残しておきます。
こんにちは。wat(@watlablog)です。ここではG検定の模擬テスト等を受けた結果、重要そうな用語をまとめます!
このブログで学習結果をアウトプットし、このページのカンペをお守りにしていたおかげ(?)か一発で合格する事ができました!

G検定のための基礎知識
G検定対策のための過去記事リンク
ここでは過去に当WATLABブログで記事にしたG検定学習ノートの記事リンク集を作成します。リンク先を開かなくても、ひと目で必要な情報があるかどうか判断できるように目次の画像キャプチャを貼っておきます。
人工知能の定義と分類

人工知能の定義
サミュエルが「明示的にプログラミングすることなく,コンピュータに 学ぶ能力を与えようとする研究分野」と定義。
ディープラーニング
ディープニューラルネットワークを使った機械学習。
AI(人工知能)>機械学習>ディープラーニング。
AIブーム
【G検定の学習】3度のAIブーム整理!過去の終焉理由と研究の動向

第1次AIブーム(1950年代~1960年代)
推論と探索のAIでブームになった。
1966年に開発されたELIZA(イライザ)がルールベースで作られたにも関わらずチューリングテストの審査員を欺いた。
後にELIZAはPARRY(パーリー)とも会話している。
推論と探索ではトイ・プロブレムしか解けずに衰退した。
第2次AIブーム(1980年代)
専門家の知識を定式化するエキスパートシステムがごく一部の領域で成果を出したことでブームとなった。
(DENDRAL(デンドラル:有機化合物特定AI)やMYCIN(マイシン:抗生物質処方AI))
しかし、知識のボトルネックの問題で定式化が難しく複雑な問題に対応できなかったため衰退した。
第3次AIブーム(2000年代~)
ディープラーニングが成果を出し現在までに至るブームとなった。
勾配消失問題を解消しつつネットワークを多層化することで多彩な表現力を得たことがきっかけ。
特徴量を自動で抽出するという革新を初めて得た。
機械学習の手法

ディープラーニングの概要

前提知識となる問題集・参考書・模擬テスト
徹底攻略 ディープラーニングG検定ジェネラリスト問題集
当ブログのG検定対策はこの問題集を解きながらWeb等で情報収集していました。この問題集を皮切りに各種機械学習やディープラーニングの概要が掴めました。
※2022年2月追記:今は第2版が最新のようです。

AI白書
G検定には世界各国のAI戦略、法律や研究動向に関する「最新情報」も出題されます。AI白書に記載の内容が例年多く出題されているようです。僕はAI白書2019すらまだ購入していませんが、2020年3月2日にAI白書2020が発売されました。
最新情報が欲しかったので、2019版ではなく、2020版を購入することにしました。
※2022年2月追記:現在も2020が最新のようです。

G検定は自宅受験なので、本の参照やWeb検索はし放題。このAI白書は辞書的に使う予定です。
Study AIの模擬テスト
上記問題集は最低限の知識を得るためには非常に有用で、僕は100%の正答率が出るまで学習しましたが、Study-AIさんが無料で実施してくれている模擬テストを受けるとその自信は崩壊します。
リンクはこちらです。まだ受けていない方は是非受けてみて下さい。
G検定チートシート(個人用カンペ)
ここでまとめるのは問題集をやってもStudy-AIさんの模擬テストでわからなかった用語や、Webから収集してきた情報の他に、いちいち本を参照すると時間のかかりそうな人名や発言集、定理といった内容を一言程度でまとめます。
あくまで僕個人が僕のブログで好きなようにまとめているだけですので、G検定本番でここの内容が出題されなかったとしても僕を攻めないで下さい…。
ご自身で利用する場合は必ず試験前にご自身で検証しておくことを推奨します(記載に間違いがある可能性があります)。
AIの問題・課題
フレーム問題
無限にある可能性からの探査には無限の時間がかかってしまう問題。このフレーム問題を克服したAIを強いAI(汎用AI)、克服できないAIを弱いAI(特化型AI)と呼ぶ。
シンボルグラウンディング問題
記号システムのシンボルを実世界で意味のあるものと結びつけるのは難しい。言葉の関係がわかったからといって概念と結びついたとは言えない。
知識獲得のボトルネック
現実世界の専門家の豊富な知識を定式化するのは難しい。ルールを決めていっても矛盾が発生してしまう。
次元の呪い
特徴量が多くなり問題が高次元になると分布が高次元空間の表面に集まる(回帰や分類のアルゴリズムがうまく働かない。計算量も多くなる)。
勾配消失問題
ディープラーニングにおいて、出力層から入力層に向かうにつれて勾配が消失し、誤差が見積もれなくなる現象。
過学習
オーバーフィッティングとも呼ばれ、訓練誤差は小さくなっても汎化誤差が大きくなってしまい、汎用的な問題に適用できなくなってしまうこと。
人物の発言・企業や功績
シンギュラリティについての発言内容
レイ・カーツワイル「シンギュラリティは2045年に到来する。」(著書:The Singularity is Near)
ヒューゴ・デ・ガリス「シンギュラリティは21世紀の後半に来る。そのとき人工知能は人間の知能の1兆の1兆倍だろう。」
スティーブン・ホーキング「AIの完成は人類の終焉を意味するかも知れない。」
オレン・エツィオーニ「シンギュラリティを迎える可能性はあるが、賢いコンピュータが世界制覇するという終末論的思想は馬鹿げている。」
ヴァーナー・ヴィンジ「シンギュラリティが来れば、機械が人間の役に立つふりをしなくなるだろう。」
上記以外の人物
ジェフリー・ヒントン
ディープラーニングの父と呼ばれる。2012年ILSVRCでヒントン率いるトロント大学のチームが、従来のサポートベクターマシンと大幅な差をつけて優勝した。
自己符号化器(オートエンコーダ)を提唱。確定的モデルである深層信念ネットワークを提唱。
ヤン・ルカン
CNNの基礎であるLeNetを考案。手書き文字MNISTを作成。
ニューヨーク大学の教授で同大学にデータサイエンスセンターを設立した。
2013年FacebookのAIラボに招かれ所長になった。
アンドリュー・エン(Andrew Ng)
Baidu元副社長兼チーフサイエンティスト。
CourseraというAI分野を幅広く扱う講義を立ち上げた。
deeplearning.ai, AI Fundの創始者でもある。
アーサー・リー・サミュエル
1956年に一般紙のインタビューで「明示的にプログラミングすることなく,コンピュータに 学ぶ能力を与えようとする研究分野」と発言し、機械学習の定義とされた。
機械学習を用いたチェスプログラム(チェッカープログラム)を作り、高レベルなアマチュアと互角に戦えるよう仕立てた。
イアン・グッドフェロー
GAN(敵対的生成ネットワーク)を考案し、ヤン・ルカンに「機械学習において、この10年間で最も面白いアイデア」と形容された。
福島邦彦
現在のCNNの原型であるネオコグニトロンを提唱した。
定理等
バーニーおじさんのルール
機械学習には調整が必要なパラメータ数の最低10倍はデータが必要であるとする経験則。
ノーフリーランチの定理
あらゆる問題に対して万能なアルゴリズムはない。
みにくいアヒルの子定理
機械学習における定式化で「普通のアヒル」と「みにくいアヒル」の区別はできないという定理。
モラベックスのパラドックス
機械は高度な推論よりも、人間の1才児レベルの知恵や運動能力を身につける方が難しいというパラドックス。
性能評価
| 予測 | |||
|---|---|---|---|
| 陽性 | 陰性 | ||
| 正解 | 陽性 | TP(True Positive) | FN(False Negative) |
| 陰性 | FP(False Positive) | TN(True Negative) | |
正答率
再現率(検出率・感度)
適合率
偽陽性
ディープラーニングのネットワーク名
LeNet
1988年にヤン・ルカン氏が発表したCNNの原型。
AlexNet
2012年のILSVRCでトロント大学のジェフリー・ヒントン率いるチームが使用し、2位以下に圧倒的な差をつけて優勝したネットワーク。8層。調整するパラメータは60,000,000にものぼる。
GoogLeNet
2014年のILSVRCで優勝。22層。横方向に幅のあるインセプション構造をとる。
VGG16
2014年のILSVRCでGoogLeNetに劣らない性能を誇ったオックスフォード大学のチームのCNN。16層。GoogLeNetには及ばなかったが、シンプルなネットワークなので技術者に好んで使われる。
ResNet
2015年のILSVRCで優勝。152層。Microsoftのチームが開発。これまで以上に層を深くできるようにスキップ構造を導入した。
ElmanNet
JordanNetと並ぶ初期の有力なRNNの一種。
WaveNet
Deep Mind社の音声処理ネットワーク。
その他DNNモデルやキーワード
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、2018年にGoogleから発表された最先端の自然言語モデルのこと。
YOLO
YOLO(You Only Look Once)はCNNで直接画像全体から物体らしさと位置を検出すること。グリッドセルを使って画像を分割、何の物体であるかを示すBounding boxを示す。
データの前処理
欠損値の扱い
リストワイズ法
欠損値があるサンプルをそのまま削除してしまう方法。
回帰補完
欠損しているある特徴量と相関が強い他の特徴量が存在している場合に、回帰を利用して欠損値を埋める方法。
リストワイズ法だとデータが減ってしまうので、データが少ない時に有効。
正則化手法
LASSO
Least Absolute Shrinkage and Selection Operator。L1ノルムという制約条件を与える正則化手法。パラメータのスパース推定を行う。
Ridge正則化
L2正則化項を使って説明変数の影響が大きくなり過ぎないようにする正則化。
学習方法
転移学習
別のタスクで学習しておき、学習済みの特徴やパラメータを利用すること。少ないデータ、短時間で学習することができる。学習済モデルの最終出力層のみを付け替えて、新しいデータで学習するが、事前に学習していたパラメータは重み更新しない。
友達のノートを借りて自分で勉強するイメージ。
ファインチューニング
転移学習では出力層以外を再学習させないのに対し、ファインチューニングは他の層もチューニングの意味で学習させる。1から学習させるよりかは効率的。
蒸留
別のモデルでトレーニングした知識を、別の軽量なモデルに継承させて使うこと。元のモデルを教師モデル、継承先のモデルを生徒モデルと呼ぶ。
End to End Learning
入力から出力まで一括で学習すること。コンピュータの性能が乏しい時は分割して学習させるしかなかった。
DQN
ディープラーニングを使った強化学習(Deep Q-Network)。ルールを教わることなく、ランダムな操作からハイスコアを狙っていくことができる。
正規化
バッチ正規化(Batch Normalization)
学習途中でデータの分布が偏ってしまう内部共変量シフトの問題を改善するために行う正規化。2015年に考案された。
局所コントラスト正規化
減算正規化、除算正規化を使ってCNNの画像に対して局所的にコントラストをスケーリングすること。その名の通り。
最適化手法や関連用語
勾配降下法
勾配情報を利用して重みを増加させるか減少させるかを決める。学習率がハイパーパラメータ。逐次学習(オンライン学習)の場合は確率的勾配降下法(SGD)、ミニバッチ学習の場合はミニバッチ勾配降下法と呼ぶ。
Momentum
勾配降下法に慣性項を追加し、急激に学習進捗が遅くなることを防いだ手法。
AdaGrad
学習率をパラメータに適応させる方法。重みベクトルの勾配毎に学習率を変える。学習率が大きいと収束は速いが最適な解を得ることが難しい。逆に学習率が小さいと計算時間が長いという問題を解決しようと考えられた。
RMSprop
AdaGradの発展。Adagradでは一度勾配が緩くなると学習率は小さくなるため、その先に急な勾配がある場合に対応できない。RMSpropは十分過去の勾配情報の影響を小さくすることで勾配の変化に対応しようと考えられた。
AdaDelta
RMSpropの次元数の不一致による問題を解決しようと考えられた。ニュートン法の応用となっている。
Adam
RMSpropの発展。パラメータ毎に適切なスケールで重みが更新される。AdaGradとMomentumの特徴を持つ。
勾配の平均と分散をオンラインで推定し利用する。
Adabound
2019年に発表。Adamに学習率の上限と下限(クリッピング)を設定したもの。最初はAdamのように動作し、学習後半からSGDのように動くように設計されている。
プラトー
最適化計算中に鞍点や停留点にとまってしまい、学習が停滞していること。
自然言語処理の流れと用語
①形態素解析で文章を最小単位(単語等)に分ける。
②データクレンジングで不要な文字列を除去する。
③Bag-of-Words等でベクトル化する。
④TF-IDF等で単語の重要度評価をする。
Bag of Words(BoW)
文章に単語が含まれているかどうかを考えてテキストデータを数値化すること。
形態素解析を行ったデータをベクトルの形式に変換する。
TF-IDF
文章に含まれる単語の重要度を特徴量とする。
Word2Vec
単語をベクトルとして表現するGoogleによって2013年に開発された手法。単語同士の意味の近さをベクトルの足し算引き算で計算することができる。
例)王様-男+女=女王
DL関連備忘録
CNNの畳み込み
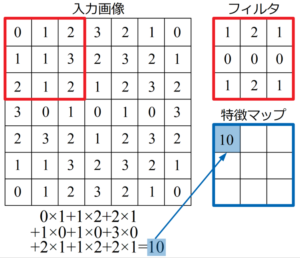
CNNの特徴マップのサイズ
LSTMのゲート
LSTMには以下の3つのゲートがあり、ゲートの開け閉めによって信号の重み付け(全開1、全閉0、その中間)をしている。
・忘却ゲート
・入力ゲート
・出力ゲート
強化学習
バンディットアルゴリズム
複数の選択肢の中から、どの選択肢が最も評価が高いか事前にわからない問題を扱うアルゴリズム。多腕バンディット問題。探索と活用を行い、報酬を動的に評価する。
ε-greedy方策
確率εで探索、1-εで活用を行い累積報酬最大化を狙う最も単純な方策。
UCB方策
Upper Confidence Bound方策。標本平均の大きいアームが選択される時は活用、小さい時は探索を行う事でバランスを調整する。選択回数が少ないアームの報酬を正しく見積もれない事に対する対応を狙う。
モデル利用時の問題
コールドスタート問題
初期や仕様追加時、データ不足時にレコメンデーション等ができない問題。
倫理・法律・世界動向
人工知能学会の倫理指針
①人類への貢献
②法規制の遵守
③他者のプライバシーの尊重
④公正性
⑤安全性
⑥誠実な振る舞い
⑦社会に対する責任
⑧社会との対話と自己研鑽
⑨人工知能への倫理遵守の要請
AI社会原則(日本の内閣府より)
①人間中心の原則
②教育・リテラシーの原則
③プライバシー確保の原則
④セキュリティ確保の原則
⑤公正競争確保の原則
⑥公平性、説明責任及び透明性の原則
⑦イノベーションの原則
自動運転のレベルと関連情報
Level0:運転自動化無し
Level1:運転支援
Level2:部分運転自動化
Level3:条件付運転自動化
Level4:高度運転自動化
Level5:完全運転自動化
自動運転関連有名企業に、Google傘下のWeimoがある。
自動車メーカは0から順番にLevelを上げていこうという方針だが、大手IT企業は一気にLevel3以上のシステムを実現させようという傾向がある。
米国における自動運転
米カリフォルニア州は自動運転の試験走行を認めている。
外部サイト:米カリフォルニア州、自動運転デリバリー車の試験走行を許可
外部サイト:カリフォルニア州がWaymoに自動運転タクシーによる乗客輸送を許可
外部サイト:Uberがカリフォルニア州で自動運転車の路上テスト許可を取得
日本における自動運転制度キーワード
自動運転等先進技術に係る制度整備小委員会報告書(2019年1月)
・運転設計領域(ODD)
自動運転システムが正常に作動する前提となる設計上の走行環境に係る特有の条件。
・自動運転システムが引き起こす人身事故の定義に含まないもの
故意の飛び出し等、被害者側に責任がある事故や整備不良等に起因する事故は自動運転システムが引き起こしたものと考えない。
・安全性に関する10要件
①運行設計領域(ODD)の設定
②自動運転システムの安全性
③保安基準などの遵守など
④ヒューマン・マシン・インターフェース(ドライバー状態監視機能等)
⑤データ記録装置の搭載
⑥サイバーセキュリティ
⑦無人自動運転移動サービス用車両の安全性(追加要件)
⑧安全性評価
⑨使用過程における安全確保
⑩自動運転車の使用者への情報提供
自動車業界の重要協調分野
自動車業界は企業が独自に開発するには難しく、協調が必要と考えている重要10分野がある(自動走行ビジネス検討会報告書(.pdf)より)。
①地図
②通信インフラ
③認識技術
④判断技術
⑤人間工学
⑥セーフティ
⑦サイバーセキュリティ
⑧ソフトウェア人材
⑨社会受容性
⑩安全性評価
ドローンの法律
国土交通省:無人航空機(ドローン・ラジコン機等)の飛行ルール
飛行禁止空域
・空港周辺
・150m以上の上空
・人家の集中地域(DID)
飛行ルール
・日中のこと
・距離の確保を行うこと
・催しを行っている場所は飛行禁止
・危険物輸送の禁止
・物件投下の禁止
国土交通省への申請で許可を受ければ飛ばすことができる。守らないと50万円以下の罰金。ルールは総重量(バッテリー等本体以外の重量含む)が200g未満の場合は対象外。
データ流通分野の制度キーワード
・PDS(Personal Data Store)
「他者保有データの集約を含め、個人が自らの意思でデータを蓄積・管理するための仕組み(システム)であって、第三者への提供に係る制御機能(移管を含む)を有するもの」と定義される。
・情報銀行
「個人とのデータ活用に関する契約等に基づき、PDS等のシステムを活用して個人のデータを管理するとともに、個人の指示又は予め指定した条件に基づき個人に代わり妥当性を判断の上、データを第三者(他の事業者)に提供する事業」と定義される。
・データ取引市場
「データ保有者と当該データの活用を希望する者を仲介し、売買等による取引を可能とする仕組み(市場)」と定義される。
・CBPR(一般データ保護規則)の9つのプライバシー原則
①被害の防止
②通知
③収集の制限
④個人情報の利用
⑤選択の機会提供
⑥個人情報の完全性確保
⑦安全管理措置
⑧アクセスと訂正
⑨責任
各国のAI活用経済成長戦略
日本:新産業構造ビジョン
英国:RAS2020戦略
ドイツ:デジタル戦略2025
中国:インターネットプラスAI3年行動実施法案
米国の人工知能に関する報告書
①THE NATIONAL ARTIFICIAL INTELLIGENCE RESEARCH AND DEVELOPMENT STRATEGIC PLAN
2016年10月:長期投資の重要性、人間とAIの協働方法、倫理や法律、安全性やセキュリティ、公共データセット開発、標準化やベンチマーク、AI研究開発人材等。
②PREPARING FOR THE FUTURE OF ARTIFICIAL INTELLIGENCE
2016年10月:AI社会実装の課題。AI利用、規制、研究と人材、経済的影響、公平性安全性、未来のための準備等。AI実務家や学生に対して倫理観が必要であると主張。
③THE NATIONAL ARTIFICIAL INTELLIGENCE RESEARCH and DEVELOPMENT STRATEGIC PLAN
2016年10月:判断結果の理由をユーザーに説明できるAIプログラムを開発することが必要であることを主張した。
④ARTIFICIAL INTELLIGENCE, AUTOMATION, AND THE ECONOMY
2016年12月:AIの雇用と経済への影響やそのための対応、①②の内容と同じ範囲も網羅。
⑤SUMMARY OF THE 2018 WHITE HOUSE SUMMIT ON ARTIFICIAL INTELLIGENCE FOR AMERICAN INDUSTRY
2018年5月:ホワイトハウスが開催した「米国産業のためのAIサミット」をまとめた報告書。米国におけるAI開発のエコシステム支援、人材育成、米国におけるイノベーション障壁の除外、AIアプリケーション等。
⑥Harnessing AI to Advance Our Security and Prosperity
2019年2月:国防総省(DoD)が発表。安全保障分野のAI活用に関する報告書。共同AIセンター(JAIC)の設立、軍事倫理等。
技術動向
説明可能なAI(XAI)
ディープラーニングの予測は特徴量が自動的に抽出される。AIを自動運転や医療への活用した結果、問題が発生した場合のことを考慮し、説明可能なAIであるXAI(Explainable AI)が検討されている。
米国DARPAがXAI研究開発投資プログラムを開始。
AIをブラックボックスと認めつつ説明しようとするアプローチが以下のように複数ある。
説明可能なAIのアプローチは以下の4つが考えられている。
・解釈可能なモデル抽出(Black Box Model Explanation)
・出力の説明を生成(Model Output Explanation)
・ブラックボックスの中身の検査(Model Inspection)
・透明性のある学習器の設計(Transparent Box Design)
ニューロモルフィックコンピューティング
ディープラーニングをするためには、大量のデータが必要・計算機の処理能力が必要・エネルギー効率が多いと解決すべき問題がある。
ニューロモルフィクコンピューティングとは、脳の省電力情報処理機構(我々は約20Wの電力で生きている)を理解し、工学的にデバイスを実現させることを意味する。
まとめ
ちょっと粗めですが、模擬試験を受けた時によくわからなかった用語や、いちいち覚えていたくない人物名や発言等をメモしました。
本番までに基本は見なくても解けるようにしておき、忘れた時にメモを見るという程度で使おうと思います。
本番までに学習した内容は随時追加する予定。
自分用にこんなページを作ってしまった…!ブログだからご勘弁。
X(旧Twitter)でも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント