
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
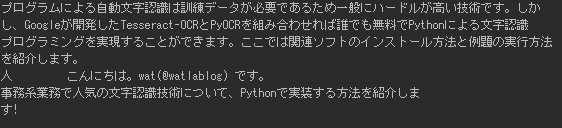
プログラムによる自動文字認識は訓練データが必要であるため一般にハードルが高い技術です。しかし、Googleが開発したTesseract-OCRとPyOCRを組み合わせれば誰でも無料でPythonによる文字認識プログラミングを実現することができます。ここでは関連ソフトのインストール方法と例題の実行方法を紹介します。
こんにちは。wat(@watlablog)です。
事務系業務で人気の文字認識技術について、Pythonで実装する方法を紹介します!
文字認識技術はこれからさらに重要になる!
文字認識技術とは?
文字認識技術とは、一般には光学文字認識(OCR:Optical Character Recognition)技術と呼ばれ、単にOCRと呼ばれることもあります。
OCR技術分野自体は1914年から始まっており、分野自体はそれほど新しくはありません。当時は光電管を使って文字列を電気信号へ変換し、予め用意された信号とのパターンマッチングによる認識をしていたようです。
1914年と聞くと歴史的には大変な時期を思い浮かべてしまいますが、現代でもよく使われるパターンマッチングの考え方はこの頃から既にあったんですね!
文字認識技術の目的は印刷物、街中で見かける建物の看板、車のナンバー…と様々な文字をコンピュータで扱えるようにすることです。
PCのキーボードで「a」と文字を打てば、コンピュータはそれが「a」であることを認識することができますが、「a」と書かれた紙をカメラで撮影してPCに取り込んだだけでは、そのデータは単なる画像でありコンピュータは「a」という文字を認識することはできません。
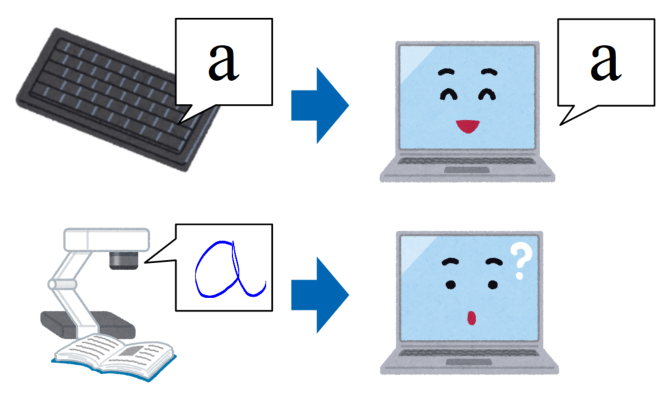
コンピュータにこれらの文字列を認識させるために、OCRプログラミングを使います。

文字認識のニーズと技術レベルがマッチしてきた
OCR技術は1900年代前半から始まっているのにも関わらず、2000年を過ぎても十分な認識率を達成できていませんでした。
その最大の理由は「手書きの多様性」(フォントの多様性も)や「言語の多様性」にあります。
OCR技術は特に手書きの文章に対して多くのニーズがあります。活字であればそもそも元データがある場合が多いと思いますが、企業間で使用される伝票や現場で使われる管理帳票等はまだまだ手書きで運用されている所も多いです。
ペーパーレスという言葉が謳われているけど、特に日本ではまだそんなに浸透しきっていないようですね。
手書きの文章は書く人によって「クセ」があったり形がくずれていたり、とにかく活字と比べて千差万別です。それが英語、日本語…と言語の種類があるために無数のパターンを持つ所に難しさがあります。
人間が特徴量を設定して閾値を設定して…という認識技術では限界がありましたが、近年はAI・ディープラーニングといったキーワードに代表されるような機械学習技術が伸びてきたことで、再びこの文字認識技術が脚光を浴びてくるようになりました。
多数の手書き文字をラーニングさせることで、一文字ずつ文字認識するだけでなく、前後の文脈から個々の文字列を特定するということも可能になってきています。
近年は現代社会が抱えていたニーズと、それを解決するための技術レベルがマッチしてきたと言えます。
既に高精度OCR技術はサービスとして世に出ています。
参考:NTT AIよみとーる(https://business.ntt-east.co.jp/service/rpa_aiocr/#anc-01-01)
さらに、一般人でもOCR技術を手軽に使える時代になっており、この記事ではTesseract-OCRとPyOCRを使った文字認識プログラミングの方法を紹介します。
Tesseract-OCRとPyOCRを使う最大の理由
繰り返しになりますが、文字認識技術というのは手書きやフォント、言語の種類が千差万別であるため高精度を出すには非常に難しい技術とされます。
機械学習がそのブレークスルーとなっていることは事実ですが、個人で大量の学習データを用意するのは至難の業です。
現代は引き算の開発、車輪の再発明はしないという思想が強く、無料で有用なライブラリが多数公開されており、その1つがTesseract-OCRです。
Tesseract-OCRというのは、Googleが開発したOCR用のソフトウェアです。このソフトは各言語毎に訓練データを使って文字認識をしています。
Googleによる学習済み訓練データが使える、というのがTesseract-OCRを使う最大の理由です。
ざっとググるとOCRのライブラリは色々あるけど、このTesseract-OCRを使うと高精度な文字認識ができるみたいね。
Tesseract-OCRはこのソフト単体でも使うことが出来ますが、カメラと一緒に、他の科学技術計算やアルゴリズムと一緒に使う場合はプログラミング言語内で呼び出して使えた方が便利です。
このブログでは、PythonでTesseract-OCRを利用するために、PyOCRというライブラリを使います。
GoogleとPythonの力に頼りましょう!
【環境構築】簡単にOCRを使うための準備をする(Windows)
PythonでOCRプログラミングをするために、ここではSTEP1でTesseract-OCR、STEP2でPyOCRを導入する方法を紹介します。
筆者の環境はWindows10であるためWindowsユーザ向けの導入方法を紹介します。
僕が使っているPython開発環境を含めた詳しい環境説明は「Python入門!初心者がインストールから学習開始するまでの3ステップ」に記載しましたので、必要に応じて参考にして下さい。
STEP1:Tesseract-OCR v5.0.0をインストールする
Githubからダウンロードする
Tesseract-OCRは以下のGithubのリンクからダウンロードします。
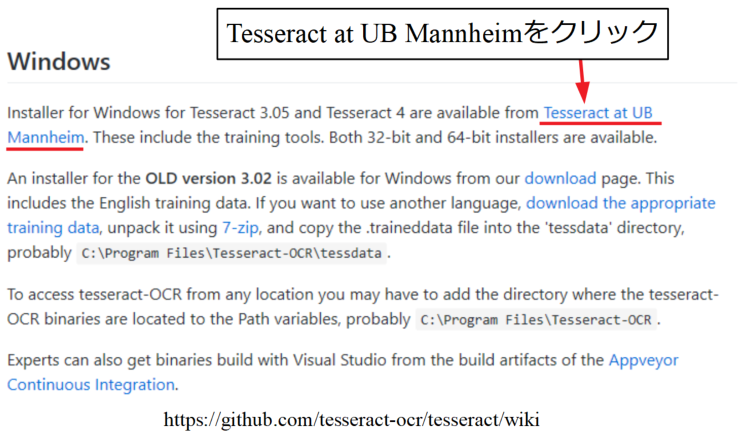
Github:https://github.com/tesseract-ocr/tesseract/wiki
上記リンクにアクセスしたらWindowsの項目までスクロールし、「Tesseract at UB Mannheim」というリンクをクリックして下さい。
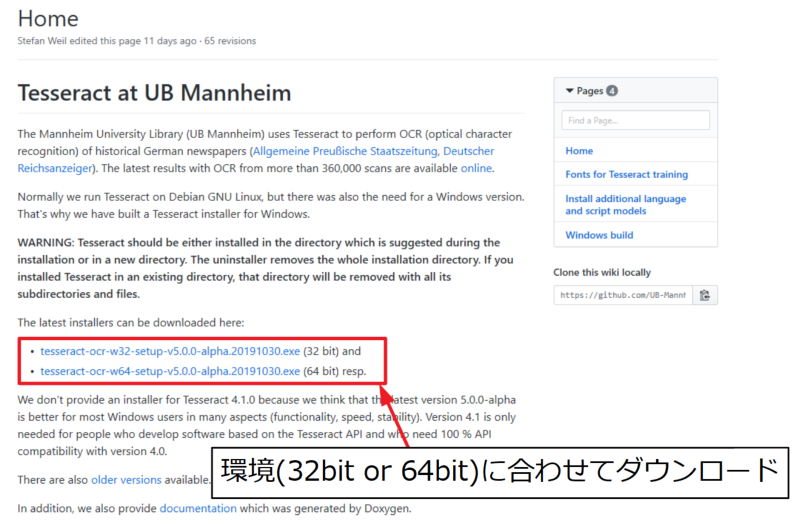
移動した先のページに32bit版と64bit版の実行ファイルがあるため、自分の環境に合わせてダウンロードします。2019年11月現在ではv5.0.0が最新のようです。
インストーラによるTesseract-OCRのインストール
ダウンロードした.exeファイルをダブルクリックで実行するとTesseract-OCRのインストーラが立ち上がります。
まずは「Next」をクリックして次に進みます。
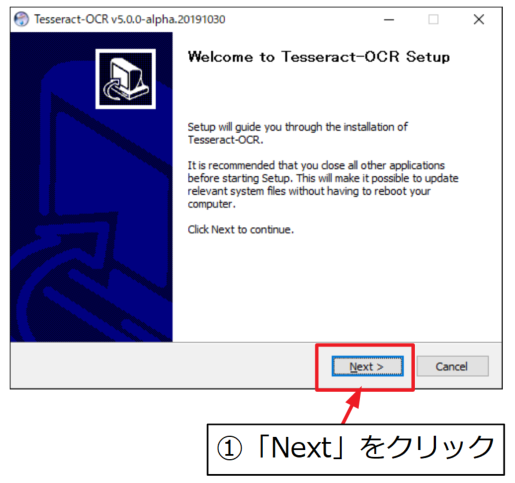
同意文書に同意したら「I Agree」をクリックします。
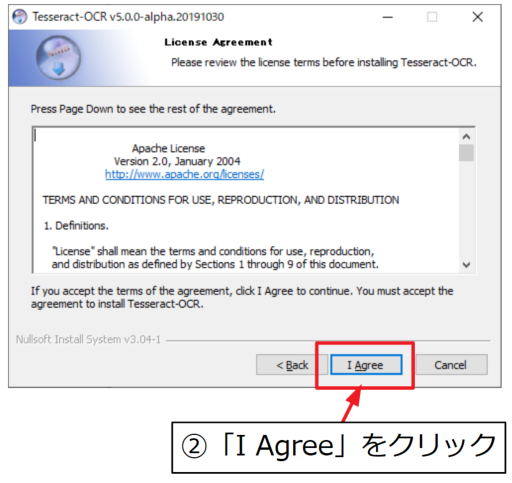
「すべてのユーザとしてインストールする」または「自分用としてインストールする」かを選択して「Next」をクリックします。
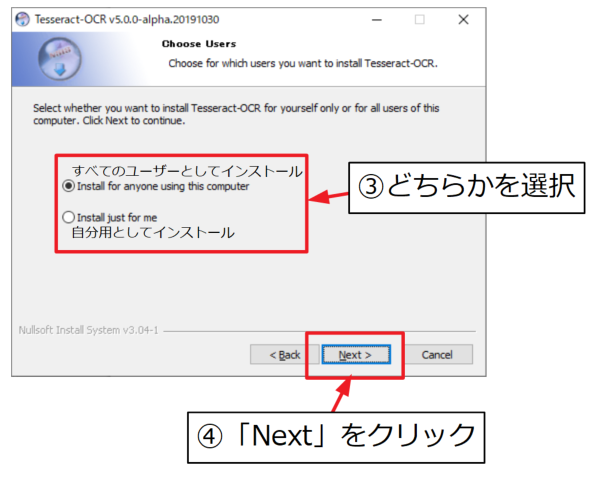
デフォルトの設定では最低限のコンポーネント(訓練データ等)がチェックされていますが、このままでは日本語の文章に対応していません。
後で別途ダウンロードすることもできますが、ここで設定しておくために「Additional script data (download)」と「Additional language data (download)」の「+」マークをクリックして展開します。
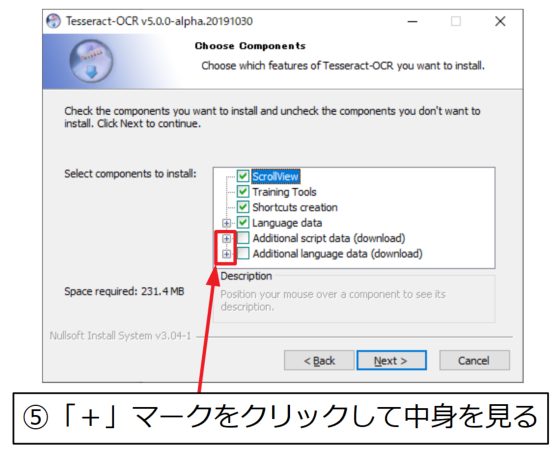
まず、Additional script dataのリストから「Japanese script」と「Japanese vertical script」にチェックを付けます。これで日本語の横書きと縦書きに対応します。
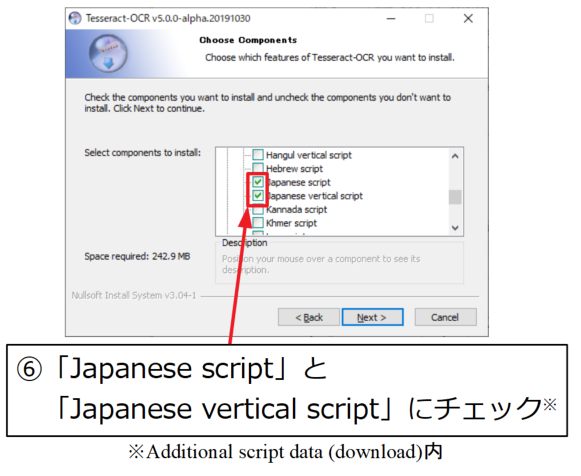
同様に、Additional language dataのリストから「Japanese」と「Japanese(vertical)」にチェックを付けます。
選択したら「Next」をクリックして先に進みます。
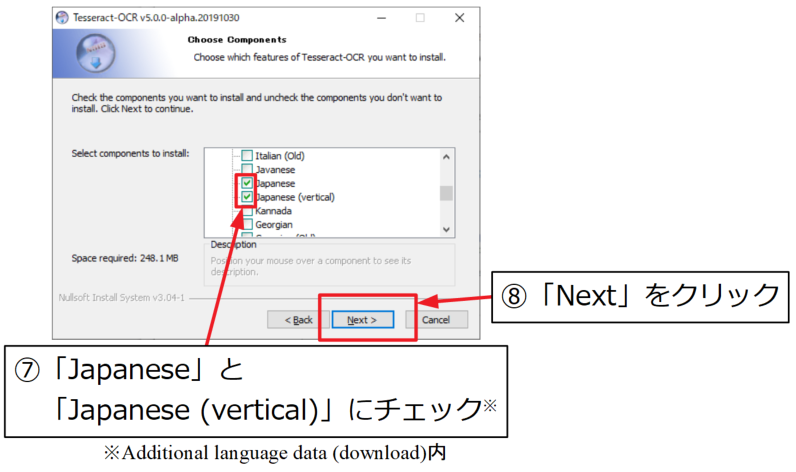
インストール場所を確認して「Next」をクリックします。
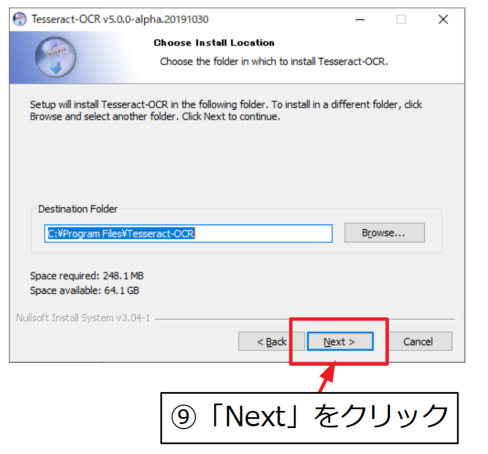
ショートカット作成はお好み。「Next」をクリックするとインストールが開始されます。
言語データや訓練データのダウンロードも行うので、インターネットに接続した状態であることを確認して下さい。
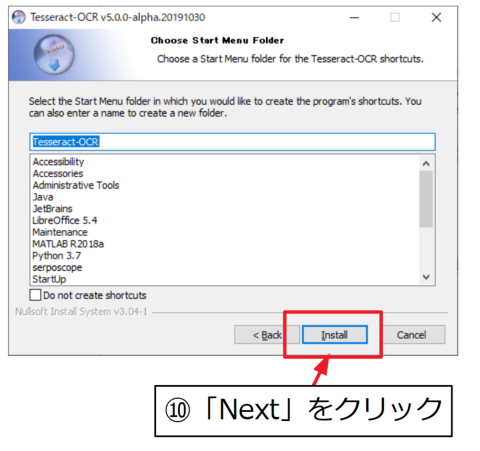
Installation Completeの文字を確認して「Next」。
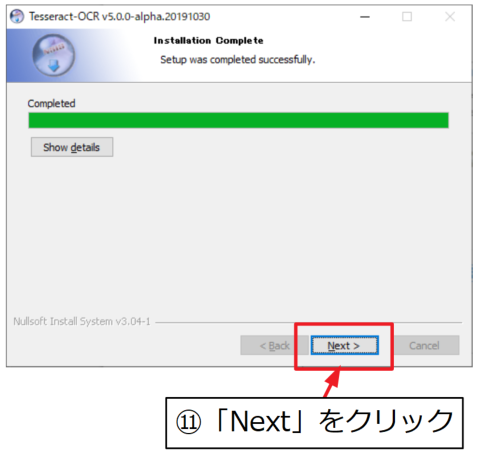
「Finish」でTesseract-OCRのインストールは完了です。
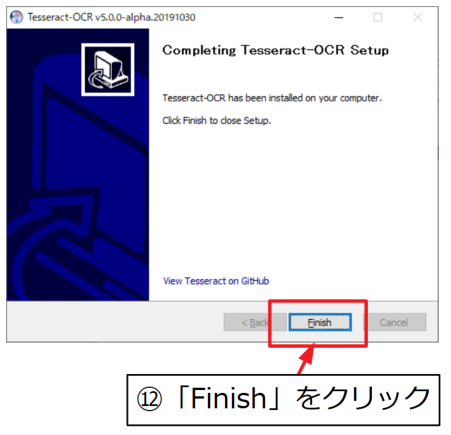
環境変数を追加する
Tesseract-OCRをPythonから使うために、システムの環境変数へ以下の変数を追加します。
変数名「TRSSDATA_PREFIX」
変数値「C:\Program Files\Tesseract-OCR\tessdata」
※変数値はインストールした環境によります。
環境変数の設定画面には、
デスクトップの「Windowsマーク」右クリック→「エクスプローラ」→ツリーの「PC」右クリック→「プロパティ」→「システムの詳細設定」→「詳細設定」タブの中の「環境変数」
で行けます。
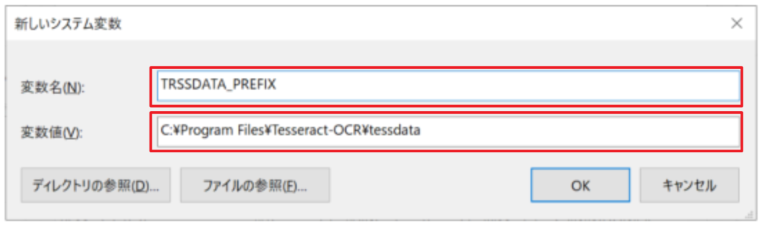
この画面で、「システム環境変数」の下にある「新規」から下図が開き追加可能です。
コンピュータを再起動する
Tesseract-OCRをインストールしたらPCの再起動を行います。
STEP2:PyOCRをインストールする
PyOCRはpipで簡単にインストール可能です。Windowsのコマンドプロンプトに以下のpipコマンドを打ち込んで実行して下さい。
|
1 |
python -m pip install pyocr |
pipについての詳細は「Pythonのパッケージ管理ツール pipの使い方とコマンド集」に記載しました。
macOSでTesseractとPyOCRを用意する場合
上記は全てWindowsの場合ですが、Macの場合はbrewを使ってtesseractを簡単にインストールすることが可能です。筆者のMacによるPython開発環境は「macOSにPython3をインストールする方法をまとめてみた」に書いていますので、これと同じであればここに記載の方法で大丈夫だと思います。
|
1 |
brew install tesseract |
pyocrはpipでインストールします。Macは元々Python2系が入っていたのでpip3としています。
|
1 |
pip3 install pyocr |
訓練データとして、「tessdata」(他にも精度の良い「tessdata_best」とかもありますが)をダウンロードします。
ダウンロードは以下のgithubから可能。
https://github.com/tesseract-ocr/
「Clone」→「Download ZIP」でtessdata-master.zip」がダウンロードされるため、解凍する。
日本語訓練データである「jpn_vert.traineddata」と「jpn.traineddata」をコピーする。

Finderを開き、メニューの「移動」→「フォルダ へ移動」または「SHIFT+command+G」で以下のアドレスへ移動する。
(tesseractのバージョンはインストールした時のものになっています)
/usr/local/Cellar/tesseract/4.1.1/share/tessdata/
先ほどコピーした2つの日本語訓練データをここに貼り付ける。
以上で上記でWindows版で紹介した作業と同様のことが完了します。
【例題】PythonでOCRを使うコード
全コード
PythonによるOCRプログラム全コードを以下に示します。
PIL(Pillow)を使っているのは、OpenCVで画像を読み込むと結局PIL形式に変換しなければpyocrでエラーが出てしまうからです。
ここでは「test.png」という画像を使って日本語のテキストを取得しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from PIL import Image import pyocr.builders # Tesseract-OCRを呼び出す tools = pyocr.get_available_tools() tool = tools[0] # 画像から日本語文字を読み取る txt = tool.image_to_string( Image.open('test.png'), # 画像読み込み lang="jpn", # 日本語を設定 builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 結果をテキストとして受け取る ) print(txt) |
.TextBuilder()の部分を変えることで認識した文字の位置座標情報等、他の情報も検出することができるようになりますが、今回はベーシックなテキスト検出のみです。
各画像に対する実行結果
wabの活字
まずはWebからキャプチャしてきた当WATLABブログの文でお試ししてみます。 OCRにかけるのは以下の画像。このページのリード文ですね。

以下がコンソールに表示された実行結果です。
「自動文字認識」の部分が一部間違っていますが、99.4%正解です。

画像付きweb活字
次はちょっといじわるをしてwebのキャプチャ画像内に僕のアイコンと吹き出しが付いている以下の画像で試してみましょう。
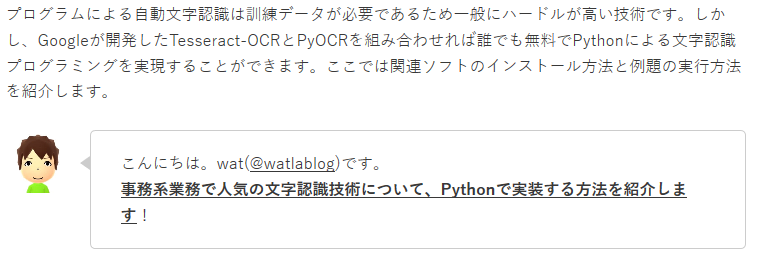
下図が実行結果です。アイコンと吹き出しの部分は「人」という字になってしまいましたが、テキストは100%正解しているようです。
手書き文字(電子ペーパーの写真)
最後に手書き文字です。
最近富士通さんから出ている電子ペーパーの「QUADERNO(※富士通WEB MARTで直販しています)」を購入してペーパーレスライフを楽しんでいるので、QUADERNOに書いた文字を写真に撮ってOCRを試してみます。


以下が実行結果…です。
読めたもんではありません!

え!?僕の字、下手すぎ!?
NTTさんから出ている商用サービスと比べると目も当てられない精度です。
手書き文字を十分な精度で認識するのは、別途画像処理やパラメータ設定、追加学習等が必要かも知れません。
まとめ
本記事では光学文字認識(OCR)技術の概要説明と、PythonでOCRを使うための環境構築を説明しました。
Tesseract-OCRとPyOCRを使えばわずか数行で簡単にOCRプログラミングができることを示しました。
お試しとして実際にwebのキャプチャ画像から文字列を認識した結果はほぼ全てのテキスト認識が出来ていることを確認しましたが、手書き文字に関してはまだまだ実用レベルではない結果を得ました。
手書き文字については、余裕があれば今後当WATLABブログで精度向上の記事を書くと思います。
PythonによるOCRプログラミングを覚えました!しかし手書き文字認識はかなりハードルが高そうです!僕の下手な字でも読み取ってくれる技術が明確になれば色々OCRプログラムの個人活用ができそうです!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
watさん。こんにちは。
上のとおり作業したが下記のエラーが出て、解決教えていただきますか?
>>>
Traceback (most recent call last):
File “C:\Users\hohao\Desktop\python\0605_16.py”, line 6, in
tool = tools[0]
IndexError: list index out of range
>>>
宜しくお願いします。
ご訪問ありがとうございます!
そちらのエラーはIndexErrorとあるため、tools[0]に何も入っていないということだと思います。
「tools = pyocr.get_available_tools()」の次の行に「print(tools)」を追加して実行すると、空の結果が返ってきませんか?
もしそうであれば、利用可能なツール、すなわちTesseractの導入がうまくいっていないと思われます。
その場合は本ページのSTEP1をもう一度ご確認頂けませんでしょうか?
こんにちは
以下のソース