
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

前回当ブログでは、WebスクレイピングをするためにWebサイトにリクエストを送信して情報を取得する方法を紹介しました。しかし得られた情報はHTMLであるため様々なHTMLタグが密集していて、欲しい情報を抽出するにはもう少し処理が必要のようです。ここではHTMLタグを除去する方法を紹介します。
こんにちは。wat(@watlablog)です。
Webスクレイピングについて少し学習していきます!ここでは、まずは自力で得られたHTMLから好きな情報を抽出する方法を紹介します!
ここで紹介している内容はWebスクレイピングの一例に過ぎません。僕はPython特化型学習サービス「PyQ(パイキュー)」で基礎を覚えました。体系的にPythonプログラミングやWebスクレイピングを覚えたい方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」の記事をご覧下さい。
またこのページではBeautifulSoupやSeleniumといったライブラリを用いない方法でコードを書いています。
まずはそれらの便利なツールを使わないで情報を整理する方法を「やってみた」という内容であることにご注意下さい。
Webから得られた情報を分析するにはHTMLの理解が必要
Webから情報を取得する方法のおさらい
前回の記事「PythonでWebスクレイピング!Requestsで情報取得!」で、Requestsメソッドを使ってWebページへリクエストを送信し、HTMLファイルの中身をテキスト形式で取得する方法を紹介しました。
※Webページから情報を取得する時は、法的問題にならないように気を付けましょう!詳しくは先ほどの記事をご確認下さい!
取得したHTMLファイルの例を以下の図に示します。このようにHTMLファイルはWebページを構成するためにHTMLタグと呼ばれるコードで満載です。
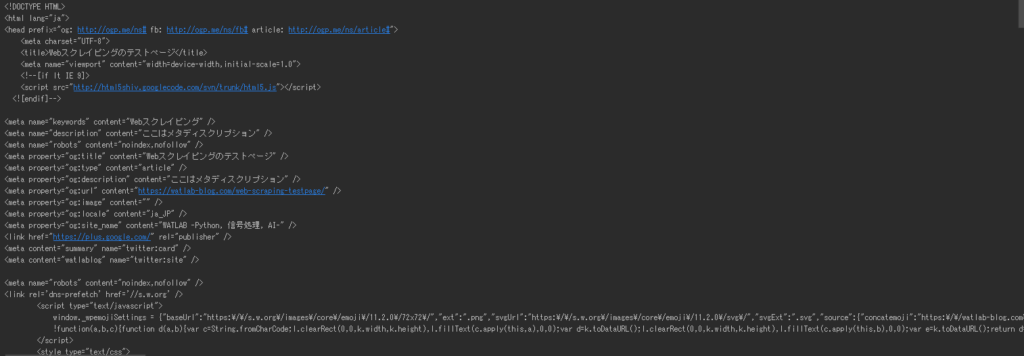
HTMLタグとは?
HTMLとは、Hyper Text Markup Languageの略で、Webページでリンクを貼ったり、フォントの色を変えたり、様々な効果を表現することができます。
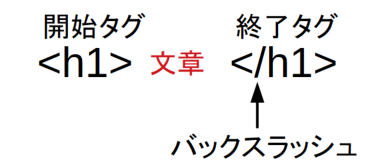
そしてそれらはHTMLタグと呼ばれる構文を使って命令文を書きます。HTMLタグの例を以下に示します。
以下はh1タグを意味しており、「h1」という文字は「<」と「>」で囲われています。最初の<h1>は開始タグと呼ばれ、文章の後にある</h1>は終了タグと呼ばれ、バックスラッシュがあることが特徴です。
Webから得られた情報から欲しい文章を抽出するためには、このHTMLタグの構造を理解し、適切に取り除く必要がありますね。
PythonでHTMLタグを取り除くコード
では、HTMLファイルからHTMLタグを取り除くPythonコードを説明します。
以下に全コードを示します。HTMLタグを含んだ文章はtextに格納しており、def文で書いたremove_bracket関数(括弧は英語でbracketというらしい)でタグを取り除きます。
詳細はコード内にテキストで書いてありますが、この関数では具体的に「<>」で挟まれた部分を削除するというだけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# テキストから<~>で挟まれた部分を削除する関数 def remove_bracket(text): check = True # whileループの終了条件に使用 word_s = '<' # タグの先頭<を検索する時に使用 word_e = '>' # タグの末尾>を検索する時に使用 # 「<>」のセットが無くなるまでループ while check == True: start = text.find(word_s) # <が何番目の指標かを検索 # もしword_sが無い場合はcheckをFにしてwhileを終了 if start == -1: check = False # word_sが存在する場合 else: end = text.find(word_e) # >が何番目の指標かを検索 # もしword_eが無い場合はcheckをFにしてwhileを終了 if end == -1: check = False # word_sとword_eの両方がセットである場合は<と>で囲まれた範囲を空白に置換(削除)する。 else: remove_word = text[start:end + 1] # 削除するワード(<と>で囲まれた所)をスライス text = text.replace(remove_word, '') # remove_wordを空白に置換 return text text = '<h1 class="post-title" itemprop="headline">文章</h1>' print(text) text = remove_bracket(text) print(text) |
文章から「<>」を検索する方法は「Pythonでテキスト処理!任意の文字列の場所を検索する方法」で紹介した通りです。
文章を削除するのにはstrip関数がありますが、ここではreplace関数を使っています。strip関数だとまとまった文章のみを削除してはくれないので、replace関数で空白と置換することで削除を表現しています。
実行結果は以下のようになります。元の文章にはHTMLタグが入っていますが、関数を実行した後の文章にはHTMLタグは入っていません。
|
1 2 3 4 |
# 元の文章 <h1 class="post-title" itemprop="headline">文章</h1> # タグを取り除いた文章 文章 |
まとめ
このページではWebの情報を分析したりするため、抽出した情報を整理する方法について紹介しました。
具体的には文章中からHTMLタグを取り除くという方法で整理しました。
世の中には便利なメソッドが沢山ありますが、まずは自分で組んでみるのも理解が深まるのでオススメですね。
中々長いコードになりましたが、自分で組んでもやりたいことはできそうですね!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント