

前回は最小二乗法を使って直線近似する方法を習得しました。最小二乗法は何も直線を近似させるためだけにあるわけではありません。ここでは、同様の考え方で2次以降の高次関数へのフィッティングがPythonで簡単にできることを示します。
続きを読む
前回は最小二乗法を使って直線近似する方法を習得しました。最小二乗法は何も直線を近似させるためだけにあるわけではありません。ここでは、同様の考え方で2次以降の高次関数へのフィッティングがPythonで簡単にできることを示します。
続きを読む
実験結果等の様々な誤差を含む点列データは通常折れ線グラフでは描かず、そのまま点を散布図で示すか、適切にカーブフィットした直線、または曲線で近似する手法をよくとります。ここではPythonで代表的な最小二乗法による直線近似を行う方法を紹介します。
続きを読む
csvファイルは様々なソフトで互換性が高く、データフォーマットとしての汎用性が非常に高いファイルです。ここでは文字列と数値が混合されたcsvファイルをPandasで簡単に読み込みする方法を習得します。
続きを読む
Pythonでプログラミングをしていて最もイヤな事はエラーですね。初心者がよく陥るエラーにimport時のエラーがあります。特に文法も間違っているわけでも無いのにエラーが出る場合もあるので、まず最初にファイル名等気を付けるポイントを説明します。
続きを読む
動画をYoutube等にアップロードする場合、ユーザビリティを考えてテロップを入れたい時があります。動画編集のソフトは有料無料様々ありますが、プログラムを自分で組むことができれば、細かい演出も自由自在です。ここではPythonで動画の任意の位置・時間にテロップを入れる方法を紹介します。
続きを読むPythonで画像や動画にテロップを入れる時、テキストの配置位置を制御したい時はテキストのピクセルサイズを把握する必要があります。ここではPythonのPillowを使ってテキストのピクセルサイズ情報を取得する方法を紹介します。
続きを読む
Pythonで文字列の長さを計算するlen()は文字列の個数を算出してくれる便利な関数ですが、全角と半角の判別をしてはくれません。ここでは、文字列の全角と半角を考慮した長さを算出する方法について学びます。
続きを読む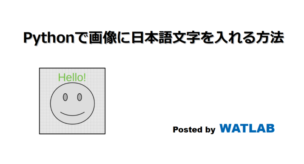
Pythonで画像処理をする場合はOpenCVが便利ですが、細かい機能はPillow等のライブラリが優秀だったりします。ここではPillowを使って日本語フォントを任意画像に描画する方法を紹介します。
続きを読む
Pythonで書いたコードは、その他の言語で書いたコードよりも比較的綺麗になると言われています。その大きな理由は「インデント」を揃えなければ動かないことにあります。ここでは、Pythonの統合開発環境(IDE)であるPyCharmで複数行インデントを一括で変更する方法を習得します。
続きを読む
PythonでSeleniumを使うと、Google Chromeを自動操作することが可能です。実際にChromeが画面上に立ち上がる動作をしますが、決まった操作であればあえてPC画面に表示させる必要はありません。ここではSeleniumでChromeを使う時に画面に何も表示させないヘッドレス起動の方法を紹介します。
続きを読む