
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Webページに有用な情報があっても、ページはある日突然変更されたり消えてしまったりすることがあります。ここではWebページをPDFとしてオフラインに保存する方法を紹介します。
こんにちは。wat(@watlablog)です。ここではWebページをPDF化する方法を紹介します!
WebページをPDF化するメリット2選!
①オフライン環境で外に持っていくことが出来る
Webページを閲覧する場合は当然インターネット接続環境が必要です。外出先であるWebページの内容を参照しようと思っても、どこでもWi-fi環境が満足にあるとは限りません。
そんな時、WebページがPDF等のファイルに内容がまとまっていると色々な媒体で読むことが出来るメリットがあります。
WebページをHTMLファイルとしてダウンロードすればオフラインでもWebブラウザを使って閲覧することが出来ますが、PDFファイルであれば電子ペーパー等でも読むことが出来ますね。
②ページ消失の心配を無くすことが出来る
Webページは未来永劫その場所に存在しているとは言えません。Wordpressのブログだってサーバー代金が毎月かかるし(微々たるものですが)、はてなブログ等の無料サービスだっていつ終了するかはわかりません(ついこの前も前〇プロフが終了したそうです)。
そんな時、気になるページをPDF化しておけばいつでも文章を参照することが出来ます。※しかし、著作権の問題から個人使用以外での利用は注意しましょう。
著作権に関してはおそらくWebスクレイピングの時と同じ感覚と思われます。
気になる方は「PythonでWebスクレイピング!Requestsで情報取得!」に注意点や、プログラム的にアクセスした事で発生した事件の事例を記載しましたので参照頂ければと思います。
PythonでWebページをPDF化するコード
pdfkitのインストール
PDF化のコードはpdfkitというライブラリを使います。pipについては「Pythonのパッケージ管理ツール pipの使い方とコマンド集」で詳細に紹介しています。
まずは以下のコードをWindowsであればコマンドプロンプトに打ち込んでpdfkitをインストールしましょう。
|
1 |
python -m pip install pdfkit |
wkhtmltopdfのインストール
pdfkitはライブラリ内部でwkhtmltopdfというソフトを動作させます。そのため、次はwkhtmltopdfをインストールします。ここではWindows10 64bitの場合で説明をして行きます。
公式ページからwkhtmltopdfをダウンロードする
まずはソフトをダウンロードするために、以下のwkhtmltopdf公式ダウンロードページにアクセスします。
公式ページ:https://wkhtmltopdf.org/downloads.html
上記リンクにアクセスしたら、自分の使っている環境に適したOS/bit数のリンクをクリックします。
リンクをクリックするとインストーラをダウンロードする場所を聞かれるので、任意の場所(デスクトップ等でもOK)に保存します。
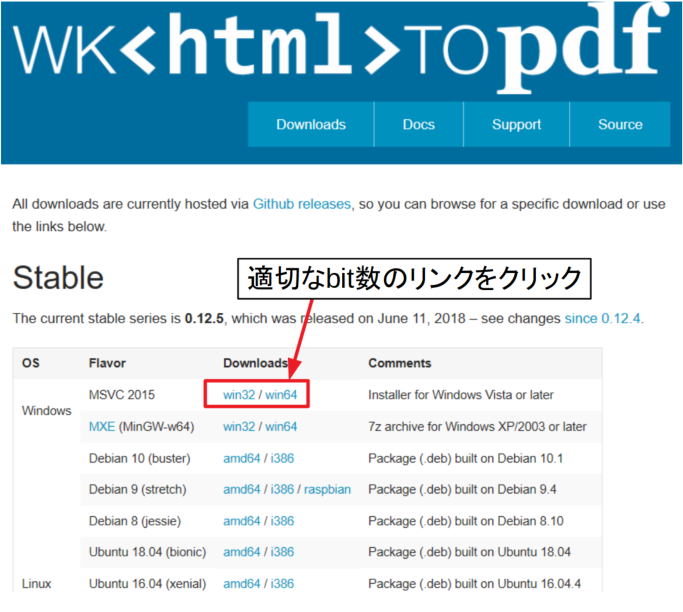
wkhtmltopdfをインストールする
先ほどダウンロードした.exeファイル(インストーラ)をダブルクリックして実行します。
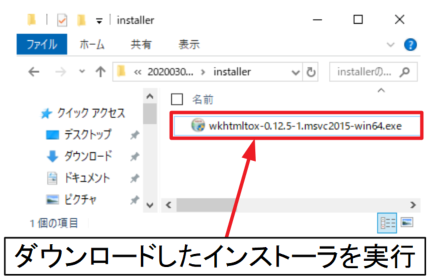
同意書を読んで同意したら「I Agree」をクリックします。
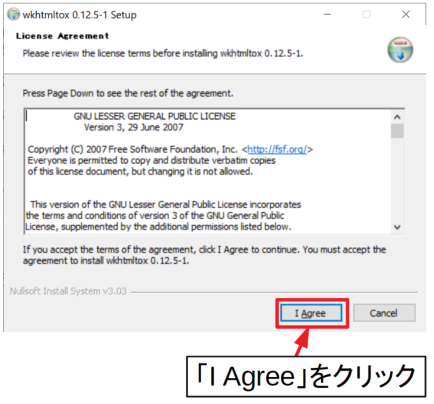
プログラムのインストール先を特に変更しないのであれば、そのまま「Install」をクリックします。
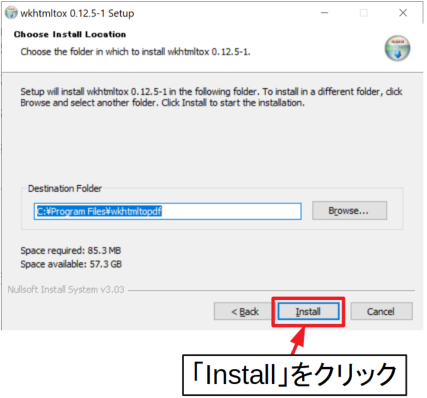
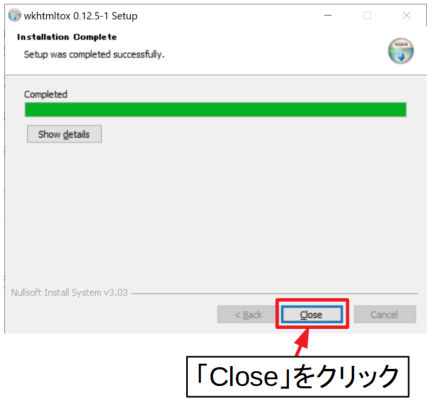
進捗バーが最後まで到達したらインストールは完了です。「Close」をクリックしてインストーラを閉じましょう。
wkhtmltopdf.exeへのパスを通す
インストールしたらプログラム的に呼び出すために、Windowsユーザならお馴染みのパスを通す作業をします。
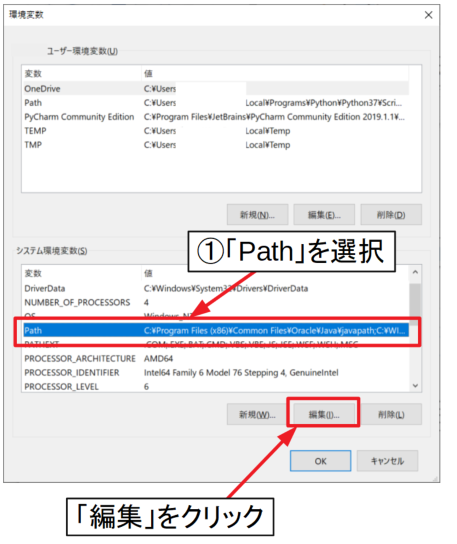
PCのプロパティ→システムの詳細設定→詳細設定タブの「環境変数」とアクセスしていきましょう。
続いて、「システムの環境変数」の中にある「Path」を選択し、「編集」をクリックします。
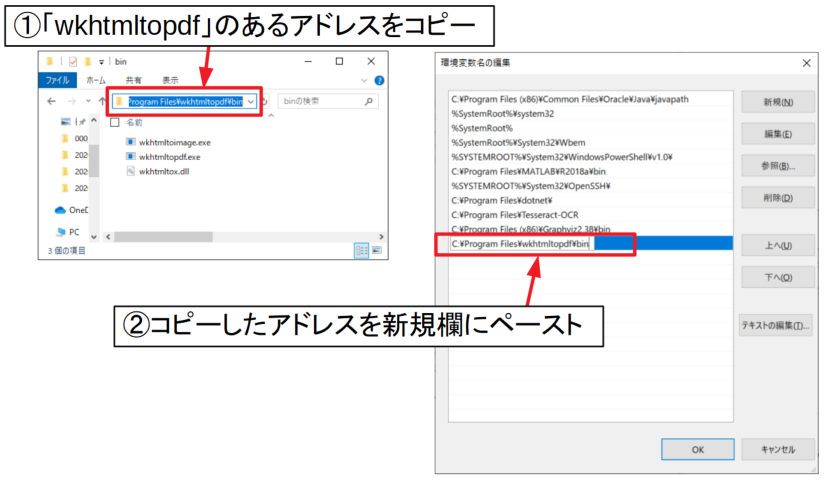
ここでwkhtmltopdf.exeがあるディレクトリのアドレス(フルパス)をコピーし、「Path」の環境変数画面下の空白にペーストして新規パスを作成します。
ペーストが完了したら全ての画面の「OK」をクリックして環境変数の設定を終了します。
PCを再起動して動作確認をする
環境変数を新規追加した後はPCを再起動し、動作確認のためにコマンドプロンプトに以下のコードを打ち込んで下さい。
|
1 |
wkhtmltopdf --version |
以下のようにwkhtmltopdfのバージョン情報が表示されればインストールとパス通しの設定は完了しています!
|
1 |
wkhtmltopdf 0.12.5 (with patched qt) |
WebページPDF化のサンプルPythonコード
全コード
以下にpdfkitによるWebページのPDF化全コードを示します。URLを設定し、optionでPDF化動作仕様を設定、pdfkit.from_urlでPDF化をしています。
技術系のブログは数式をjavascriptでTeX形式にしていることがよくありますが、javascriptの完了を待つためにjavascript-delayを30[s](コードは[ms]単位)入れています。
僕のブログのようなちょっと遅いページはこのくらい入れると調子良いかも(これを書かないと数式が読みにくいままPDF化されます)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import pdfkit url = 'https://watlab-blog.com/' # URLを設定 options = { # PDFの書式を設定 'page-size': 'A4', 'margin-top': '0', 'margin-right': '0', 'margin-left': '0', 'margin-bottom': '0', 'zoom': '1.0', 'encoding': "UTF-8", 'javascript-delay': '30000' # javascriptの完了を30s間待つ(数式の表示等) } pdfkit.from_url(url, 'watlab-home.pdf', options=options) # URLからPDFを作成 |
実行結果
以下のリンクは作成されたPDFの例です(※クリックでPDFが開きます)。
ちょっと画像レイアウトは崩れているかも知れませんが、カラーで綺麗にPDF化されていますね!
エラー「ContentNotFoundError」について
ページによっては以下のようにエラーが発生する場合があります。
Exit with code 1 due to network error: ContentNotFoundError
上記コードでurl='https://watlab-blog.com/2020/02/17/runge-kutta4-vibration/'と別のページを指定すると再現しますが、以下のようにPDFは作成されていました。
これについて原因がよくわからなかったので少しネットで調べた所、読み込めないリソース(フォント等)があるとContentNotFoundErrorが発生するそうです。
これは、レンダラーが/ some javascript/image/fontファイルを読み込めなかったときに発生しています。欠落しているリソースを解決した後、問題は修正されました。
wkhtmltopdf - ネットワークエラー
作成されたPDFを良く見てみると、コード内に記載しているコメントの日本語が軒並み文字化けしていました。
このコード記述方法のフォントを読むためのリソースが無かったためのエラーと思われます。(コード部分以外は問題無いのでまずはこのままで良いと判断しましたが、encordingの問題?)
まとめ
本ページではWebページをPDF化するメリットを紹介し、PythonによるPDF化のコードを説明しました。
pdfkitというライブラリとwkhtmltopdfという外部ソフトを使いますが、わずかな行数でWebページをPDFにすることが出来ました。
PDF化もライブラリを使えば一瞬でした!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!