
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

音声ファイルをスペクトログラム表示することで、音声の周波数・時間・レベルの変化を一度に確認することが可能です。ここではさらにフォルダ内に保存された全wavファイルに対しSTFT計算し、スペクトログラム画像を作成する方法を紹介します。
こんにちは。wat(@watlablog)です。ここではフォルダ内一括処理のスペクトログラム版を紹介します!
STFTとスペクトログラム表示のおさらい
STFT/スペクトログラムとは?
STFT(Short-Time Fourier Transform : 短時間フーリエ変換)とは、フーリエ変換を応用した計算方法のことで、時系列データを細かく窓(フレーム)で区切ってFFTし、その窓を順次横にずらしながらFFTを繰り返していく解析方法です(下図参考)。
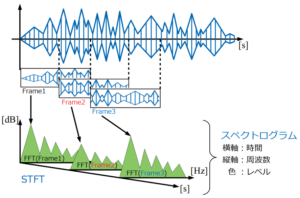
一方、スペクトログラムとは時間×周波数×振幅レベルという3つの要素で構成された3次元グラフのことで、STFT計算した結果をそのように並べてプロットしたものになります(下図参考)。
STFTやスペクトログラムについての詳細な説明、Pythonコードは「Pythonで音のSTFT計算を自作!スペクトログラム表示する方法」に記載しましたので、是非確認してみて下さい!
スペクトログラムの例
当WATLABブログでは、STFT計算とスペクトログラム表示を使ってピアノ音楽の可視化を行った「Pythonでピアノ音楽のスペクトログラムを作ってみた」や、自分の声の声帯振動やフォルマントを確認した「Pythonの音声解析でフォルマントを抽出してみた」で記事を書いていますので、ご興味のある方は是非こちらもご覧ください!
フォルダ一括処理の考え方
上記で紹介した記事は1つの音声ファイルやデータに対して1つのスペクトログラムを作成するコードを書いていました。
プログラムはコンピュータに沢山仕事をさせるのが良いと思いますので、できるだけ自動化させたいですね。
自動化の基本的な考え方に、「フォルダに関連ファイルを全て入れて、その中のファイルを一括で処理する」というものがあります。
当WATLABブログでは「Pythonでフォルダ内の画像を自動一括リサイズする方法」という記事で初めてフォルダ内のファイル一括処理を行いました。
基本的な知識は「フォルダ内のファイルパスを取得する」、「パスをファイル名と拡張子に分ける」、「新規パスを作る」、「作ったパスで保存する」というものがあれば十分と考えます。
今回はwavファイルを任意のフォルダに複数入れた状態でプログラムを実行し、フォルダ内のwavファイルを全てスペクトログラム画像に変換、.png画像を保存フォルダに格納するという処理を書きます。
それでは早速Pythonコードを見てみましょう!
フォルダ内全wavをスペクトログラム画像に変換するPythonコード
準備
まずプログラムを実行する.pyファイルフォルダの直下に、「wav」というフォルダに予めwavファイルを複数置いておきます。
参考までに以下に図として示します。
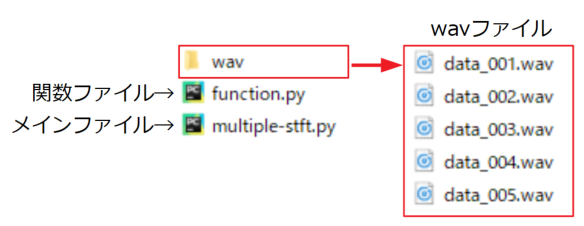
サブプログラム(function.py):STFTの計算に使う関数群
「Pythonで音のSTFT計算を自作!スペクトログラム表示する方法」の記事と同様に、STFT計算をするコードは長いので関数ファイルとしてまとめておきます。ここでは「function.py」というファイル名です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import numpy as np from scipy import signal from scipy import fftpack import soundfile as sf def wavload(path): data, samplerate = sf.read(path) return data, samplerate # オーバーラップ処理 def ov(data, samplerate, Fs, overlap): Ts = len(data) / samplerate # 全データ長 Fc = Fs / samplerate # フレーム周期 x_ol = Fs * (1 - (overlap / 100)) # オーバーラップ時のフレームずらし幅 N_ave = int((Ts - (Fc * (overlap / 100))) /\ (Fc * (1 - (overlap / 100)))) # 抽出するフレーム数(平均化に使うデータ個数) array = [] # 抽出したデータを入れる空配列の定義 # forループでデータを抽出 for i in range(N_ave): ps = int(x_ol * i) # 切り出し位置をループ毎に更新 array.append(data[ps:ps + Fs:1]) # 切り出し位置psからフレームサイズ分抽出して配列に追加 final_time = (ps + Fs)/samplerate #切り出したデータの最終時刻 return array, N_ave, final_time # オーバーラップ抽出されたデータ配列とデータ個数、最終時間を戻り値にする # 窓関数処理(ハニング窓) def hanning(data_array, Fs, N_ave): han = signal.hann(Fs) # ハニング窓作成 acf = 1 / (sum(han) / Fs) # 振幅補正係数(Amplitude Correction Factor) # オーバーラップされた複数時間波形全てに窓関数をかける for i in range(N_ave): data_array[i] = data_array[i] * han # 窓関数をかける return data_array, acf # FFT処理 def fft_ave(data_array, samplerate, Fs, N_ave, acf): fft_array = [] fft_axis = np.linspace(0, samplerate, Fs) # 周波数軸を作成 a_scale = aweightings(fft_axis) # 聴感補正曲線を計算 # FFTをして配列にdBで追加、窓関数補正値をかけ、(Fs/2)の正規化を実施。 for i in range(N_ave): fft_array.append(db\ (acf * np.abs(fftpack.fft(data_array[i]) / (Fs / 2))\ , 2e-5)) fft_array = np.array(fft_array) + a_scale # 型をndarrayに変換し、A特性をかける fft_mean = np.mean(fft_array, axis=0) # 全てのFFT波形の平均を計算 return fft_array, fft_mean, fft_axis # リニア値からdBへ変換 def db(x, dBref): y = 20 * np.log10(x / dBref) # 変換式 return y # dB値を返す # dB値からリニア値へ変換 def idb(x, dBref): y = dBref * np.power(10, x / 20) # 変換式 return y # リニア値を返す #聴感補正(A特性カーブ) def aweightings(f): if f[0] == 0: f[0] = 1 else: pass ra = (np.power(12194, 2) * np.power(f, 4)) / \ ((np.power(f, 2) + np.power(20.6, 2)) * \ np.sqrt((np.power(f, 2) + np.power(107.7, 2)) * \ (np.power(f, 2) + np.power(737.9, 2))) * \ (np.power(f, 2) + np.power(12194, 2))) a = 20 * np.log10(ra) + 2.00 return a |
メイン処理(multiple-stft.py)
続いて、メインのファイルを以下に示します。import文で先ほどのfunction.pyを読んでいるのはこれまでと同様ですが、フォルダやファイル処理を行うために、globとosも読み込んでいます。
詳細の説明はコード内にコメントを書きましたので参照下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
import function import numpy as np import glob import os from matplotlib import pyplot as plt # STFT計算の関数 def stft(path, Fs, overlap): # wavファイルを読み込む(縦軸の校正はしていない) data, samplerate = function.wavload(path) # オーバーラップ抽出された時間波形配列 time_array, N_ave, final_time = function.ov(data, samplerate, Fs, overlap) # ハニング窓関数をかける time_array, acf = function.hanning(time_array, Fs, N_ave) # FFTをかける fft_array, fft_mean, fft_axis = function.fft_ave(time_array, samplerate, Fs, N_ave, acf) # スペクトログラムで縦軸周波数、横軸時間にするためにデータを転置 fft_array = fft_array.T return fft_array, fft_axis, final_time, samplerate # 設定--------------------------------------------------------------------------------------------------- dir = 'wav' # 複数のwavファイルを入れたフォルダを指定する dir_out = os.path.join(*[dir, 'spectrogram']) # スペクトログラム画像を保存するフォルダ # if os.path.exists(dir_out) == 0: # spectrogramフォルダが無い場合はフォルダを新規作成 os.mkdir(dir_out) else: pass path_list = glob.glob(dir + '\*.wav') # フォルダ内全wavファイルのパスを検索する Fs = 4096 # FFT時のフレームサイズ overlap = 75 # FFT時のオーバーラップ率 # forループ前にグラフオブジェクトを作成しておく fig = plt.figure() ax1 = fig.add_subplot(111) # ------------------------------------------------------------------------------------------------------- # フォルダ内の全wavファイルをスペクトログラム画像にするループ-------------------------------------------- for i in range(len(path_list)): fft_array, fft_axis, final_time, samplerate = stft(path_list[i], Fs, overlap) # STFT計算の関数を実行 # データをプロットする。 im = ax1.imshow(fft_array, vmin=-10, vmax=60, # 色の物理値範囲(データにより調整必要) extent=[0, final_time, 0, samplerate], # 横軸(時間軸)設定 aspect='auto', # 縦横比 cmap='jet') # 色の種類 # カラーバーを設定する(初回のみ)。 if i == 0: cbar = fig.colorbar(im) cbar.set_label('SPL [dBA]') else: pass # 軸設定する。 ax1.set_xlabel('Time [s]') ax1.set_ylabel('Frequency [Hz]') # スケールの設定をする。 ax1.set_yticks(np.arange(0, 20000, 1000)) ax1.set_ylim(0, 4000) file = os.path.basename(path_list[i]) # 拡張子ありファイル名を取得 name, ext = os.path.splitext(file) # 拡張子なしファイル名と拡張子を取得 ext = '.png' # 拡張子を画像ファイル(.png)に変更 out_path = os.path.join(*[dir_out, name + ext]) # 画像ファイル保存パスを作成 # 画像を保存する plt.savefig(out_path, bbox_inches='tight') print(str(i+1) + ' done...') # 計算中がわかるように一応いれとく print('Finish calculation') # 計算終了の合図 # ------------------------------------------------------------------------------------------------------- |
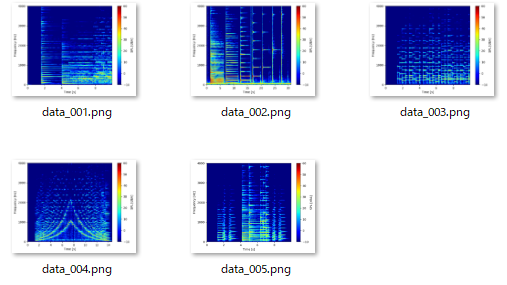
実行結果
以下が実行結果です。spectrogramというフォルダ内にwavファイルと同様の名前の.pngファイルが作成されました。
まとめ
本記事では過去のSTFT計算によるスペクトログラム画像の生成をおさらいし、フォルダ内wavファイルに対し一括スペクトログラム処理をしてみました。
このフォルダ内ファイル処理は様々な自動化の基本になりますので、是非応用してみて下さい。
今回は覚えたコードを組み合わせて音声ファイルの自動処理をしてみました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
いつも拝見させて頂いています。現在大学の研究として機械音を測定し、その音をスペクトログラムとして表示、ある一定のグラフ数値から異常ありか、なしかを判別できるようなシステムを目指しこちらのサイトを活用させて頂いています。そんな中でフォルダのパスを入手し展開しているのですが、スペクトログラム表示がされません。エラーもでていなく正常に作動しているのですが、スペクトログラム表示されないため、何か考えられる要因などありましたら教えて頂きたいです。
また、異常あり、なしをどのようなコードを打てば自動通達できるのか教えて頂けると嬉しいです。
いつもありがとうございます。
エラーが出ていなく正常に動作しているという事ですが、
「print(str(i+1) + ‘ done…’) # 計算中がわかるように一応いれとく」
の下くらいに、
「print(out_path)」
と書いて実行し、書かれているout_pathにおかしい所が無いか確認すると良いと思います。
→そもそもこのprint文が実行されているかどうか、実行されていれば文字列は存在するディレクトリにあるか、という感じです。
このページのコードはフォルダ内全てのwavをスペクトログラム画像として保存するので、リアルタイム表示はしない仕様です。
>異常あり、なしをどのようなコードを打てば自動通達できるのか
これだけだとどのような事を実現したいかはわかりませんが、
音判定システムでは通常異常音と正常音の特徴をピーク値やオーバーオール値で評価し、ある閾値でOKやNGで判定します。
複雑な異常音の場合は、最近は機械学習、ディープラーニングのモデルで判定する事が多いようです。
自動通達は、システムが工場等の場合にはランプを光らせたり音を鳴らしたり…自宅に通達したい場合はメールを送信したり…でしょうか。
とはいえ、実現したい目的に応じてこの辺は変わると思います。
いつも参考にさせて頂いています。
このコードにピークを抽出する機能をつけるにはどうすればいいのでしょうか?
他のページでご紹介頂いているのを見ましたが、組み合わせ方が今ひとつ分かりません。ご教授頂けると嬉しいです。
以上、よろしくお願いします。
ご訪問ありがとうございます。
作り方は色々あると思いますが、以下の組み合わせでできそうと思いました。
そしてピークをマークするだけで良いのか、それとも数値としてファイルに保存したいのかによって構成を組み立てるのが良いと思います。
①はじめにdef文でピーク検出関数(以下の記事のfindpeaks, findpeaks_2d)を定義しておく。
「https://watlab-blog.com/2020/09/29/findpeaks-spectrogram/」
②ピーク情報をファイルに保存する場合は、別途def文等で時間、周波数、振幅情報を保存する関数を作っておく。
(テキストファイルやcsv等。Pandasやnumpyでできそう)
②このページのコード「# STFT計算の関数を実行」の次の行で②を実行する。
ピークを画像の中で図示するだけで良い場合は②を使わず、先ほどの記事の「# ピークを描画する」部分をこのページのコード「# 軸設定する。」の前に記載する。
という感じでしょうか。
組み合わせ方の案としてご参考までに!
以下のエラーがでているのですが、対処法を教えていただけないでしょうか。
メイン処理の40行目において、
ValueError: operands could not be broadcast together with shapes (4096,2) (4096,)
のエラーが出ています。
これの修正方法を教えていただけると幸いです。
ご訪問ありがとうございます。
メイン処理40行目というと、stft関数実行部分ですね。もう少し詳しくみると関数のどこで発生しているかの特定ができると思います。
また、そのエラー自体はshapeの異なるデータに値をマッピングしようとした時に発生するものです。
(4096, 2)の2が少し気になります。このコードはモノラルのwavを想定したものですが、ステレオで録音されたwavを使っていたりしますか?
例えばlenやshapeを使ってdataのサイズを見てみる方法等がデバッグとしては良さそうです。
以上、よろしくお願いいたします。
はじめまして。いつも参考にさせていただいております。
質問なのですがこの記事のように.wavファイルではなくスマートフォンで録音した.m4aの音声ファイルでも同じようにスペクトログラムに変換することは可能でしょうか。
何卒、ご教授いただけますと幸いです。
ご訪問ありがとうございます。
mp4でも音声を抽出して、横軸時間のデータにすればスペクトログラムに変換することは可能ですよ。
お返事ありがとうございます。
この記事にあるプログラムに関してでしたら、どの部分をどのように変換すれば良いでしょうか。
お手数おかけしますが何卒よろしくお願いします。
こちらも高速化については未検討なので検証できていませんが、スペクトログラムをつくる段階でライブラリを利用するのが最も手軽であると思います。
以下の記事で紹介しているsignal.spectrogram()を使ってこの記事のコードを書き換えてみれば速くなる可能性があります。
https://watlab-blog.com/2019/05/19/python-spectrogram/#Scipy%E3%81%AEsignalspectrogram%E3%82%92%E4%BD%BF%E3%81%A3%E3%81%A6%E3%81%BF%E3%81%9F
コメント失礼します.
現在大学の研究で,こちらのソースコードを参考にスペクトログラム画像の生成コードを実装し,さらに生成速度を上げたいと考えているのですが,何か考えられる方法はないでしょうか?
ご訪問ありがとうございます。
僕はまだ速度の問題に直面していないのでまだ考えていませんが、
forループになっていてかつ演算をしている部分は線形代数の知識を使って効率を上げることができそうです。
てっとり早いのはSciPyのscipy.signal.spectrogramを使うのが良いかもしれません。
(外部ライブラリは裏でより高速なC++を走らせていたりするので)
あとはNumbaのJIT(以下記事参考)を使ってコンパイルを試みる…等もありますが、今回のケースに通用して速くなるかは未確認です。
https://watlab-blog.com/2020/06/14/numba-jit/
一度SciPyの使用を検討してみたいと思います.
参考にさせて頂きます.
返信ありがとうございました.