
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

機械学習アルゴリズムの1つであるランダムフォレスト分析は多数の決定木を作成して多数決で予測する手法です。決定木が沢山できますが、「どんな木が出来たのかな~」っと何気なく思った人のために、眺めていると無心になれる「全決定木可視化動画」の作り方を紹介します。
こんにちは。wat(@watlablog)です。今回は完全に無益回!ランダムフォレストで作成される全決定木を動画にしてみましたという内容です!
※注意
本記事を読んだからといって、何か特別な知識が付くとか、kaggleで勝てるようになるとかそんなことは全くありません。時間に余裕のある方のみ閲覧するようにして下さい!
ランダムフォレストでは複数の決定木が作成される
決定木とは?
決定木分析とは、機械学習のアルゴリズムの1つで、条件分岐を繰り返して分類や回帰を行う手法のことです。当WATLABブログでは「Python/sklearnで決定木分析!分類木の考え方とコード」という記事で概要を紹介していますので、決定木分析で機械学習をしたことが無い方は是非この記事を読んでみて下さい!
ランダムフォレストとは?
ランダムフォレストとは、決定木とバギングを組み合わせた機械学習法で、簡単に説明すると多数の決定木を作成して多数決で分類結果を決めたり、平均をとって回帰したりする大変民主主義的なアルゴリズムです。
ランダムフォレストについても概要を「Python機械学習!ランダムフォレストの概要とsklearnコード」に記載しましたので、必要であればこちらも読んで頂ければと思います。
決定木は数ある機械学習法の中でも人間が解釈しやすいと言われています。
これは決定木が条件分岐によって構築されるため、図にすることが可能だからです。(ディープニューラルネットワークとかでは中で何が行われているかを確認することは困難と思います)
決定木可視化について
可視化方法の例
図にすることができるのでその方法も多くあり、当WATLABブログでは「Python決定木可視化!Graphvizの導入とdot処理方法」という記事でGraphvizを使った可視化方法を紹介しました。
1つの決定木の可視化であればこの方法で良く、特に問題はありませんが、ランダムフォレストの場合は決定木が沢山あります。
そらもう100本ほど。
ランダムフォレストを可視化する必要性
決定木を可視化するのはハイパーパラメータを調整したり他者に説明するために大変重宝されると思いますが、個人的にはランダムフォレストを全て可視化する意味はあまりないと思います。
importanceの分析やノード数やdepth数、ジニ係数といった指標を統計的に見てスコアと対比させる方法が良いと考えられ、人間が直接目で木を1本1本確認していく作業は必要ないのではないかと感じています。
しかし中には全ての決定木を同じように可視化してざっとみたい…という場合もあるかも知れません。
例えばスコアでソートしてナンバリングした決定木を俯瞰してみると、max_depthや初期ルートの分岐方法に人間にしか気づけない、何かの特徴を見出せるかも知れません。
他には、可視化した全決定木を画像入力の機械学習に使用する等すれば、より高いスコアが出せるかも知れません。
僕は完全に暇つぶしで可視化しました。
決定木可視化の問題(?)点
得られた画像をさらに使って異なる機械学習を行う…といった場合には画像は正規化(スケーリング)されていなければ使い勝手が悪いです。
これは通常のデータでも同じで、詳しくは「Python/sklearnで学習データの前処理!標準化と正規化」で説明していますので、ご興味のある方は是非読んでみて下さい。
しかし上記で紹介した方法を使って決定木を可視化すると、Graphvizの仕様で画像サイズを最適化してくれていることから、以下の図のようにルートノードが画像に対して必ずしも中心でなかったり、画像サイズ(縦と横)が毎回異なるといった特徴があります。
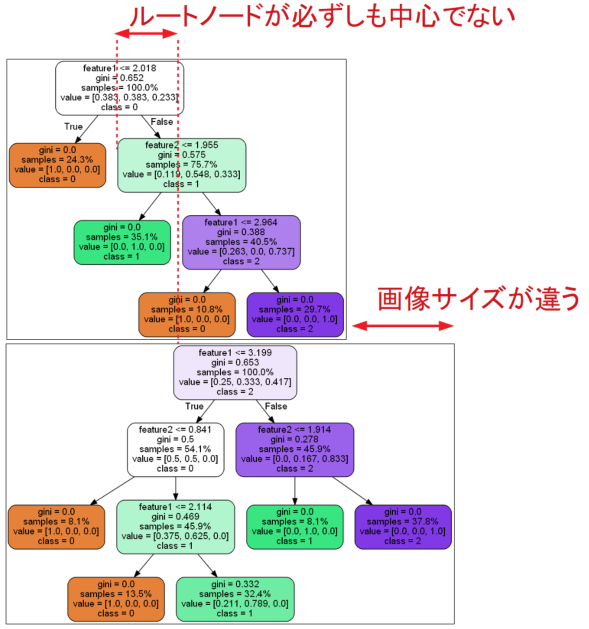
この記事の目指す所
今回は各決定木のルートノードの位置を合わせ、画像サイズを統一するという所を目指します。
これらのことを実行すれば、以下のようにGIFアニメにでもした時に木自体がどういう形をしているかが一目瞭然になります。
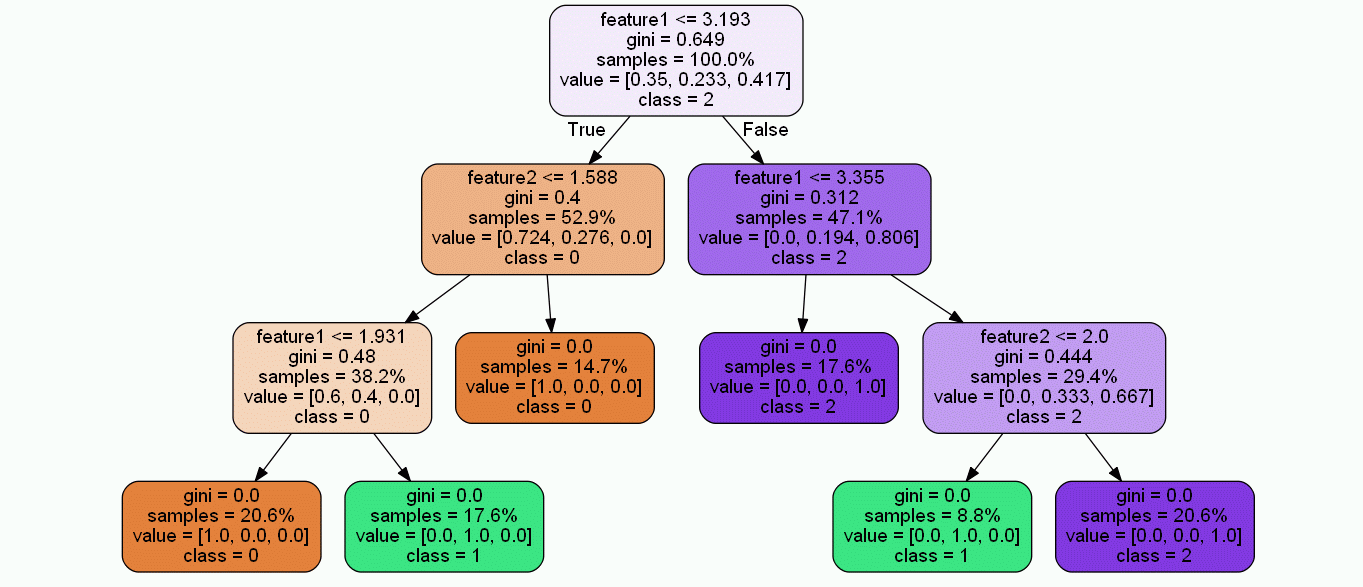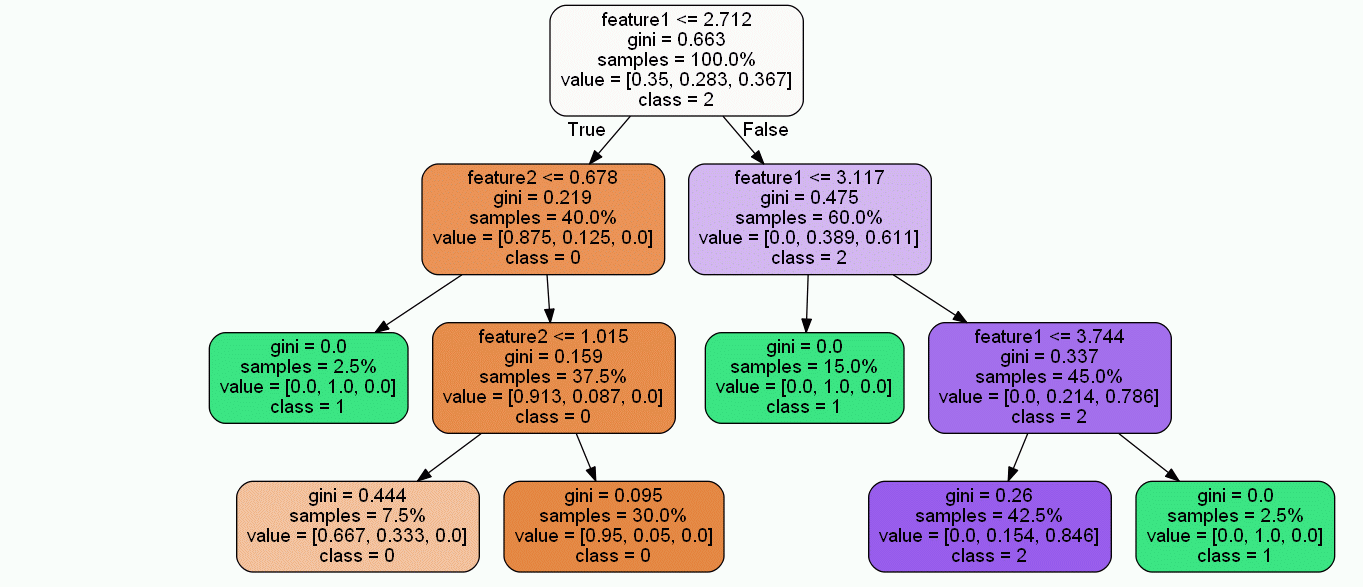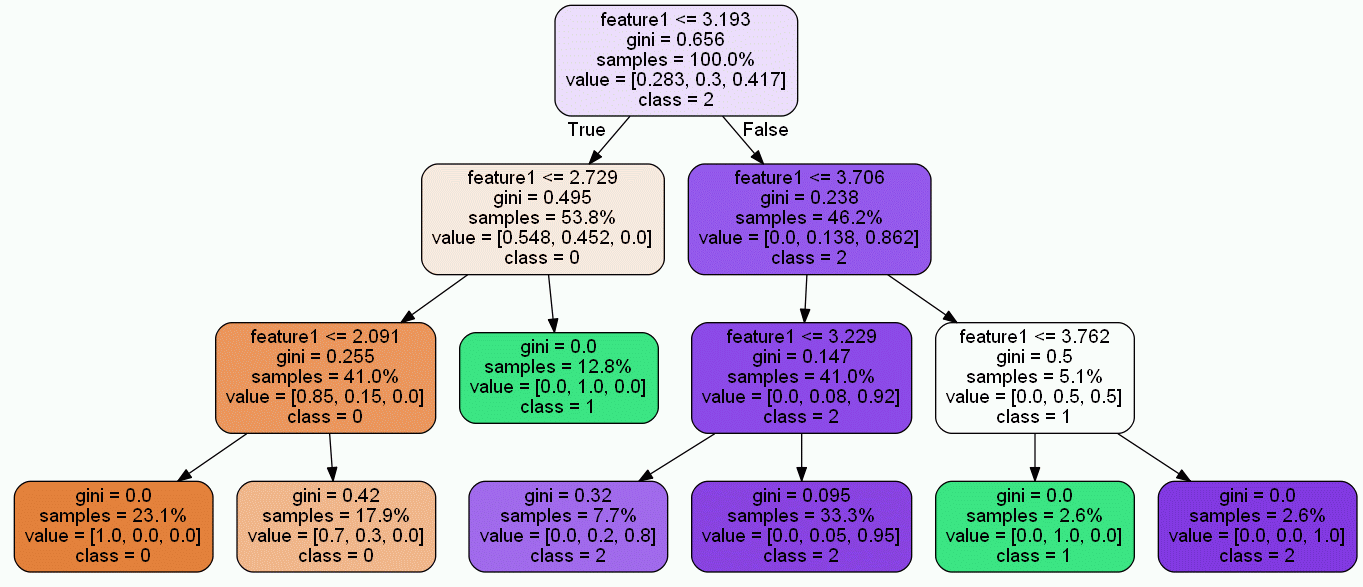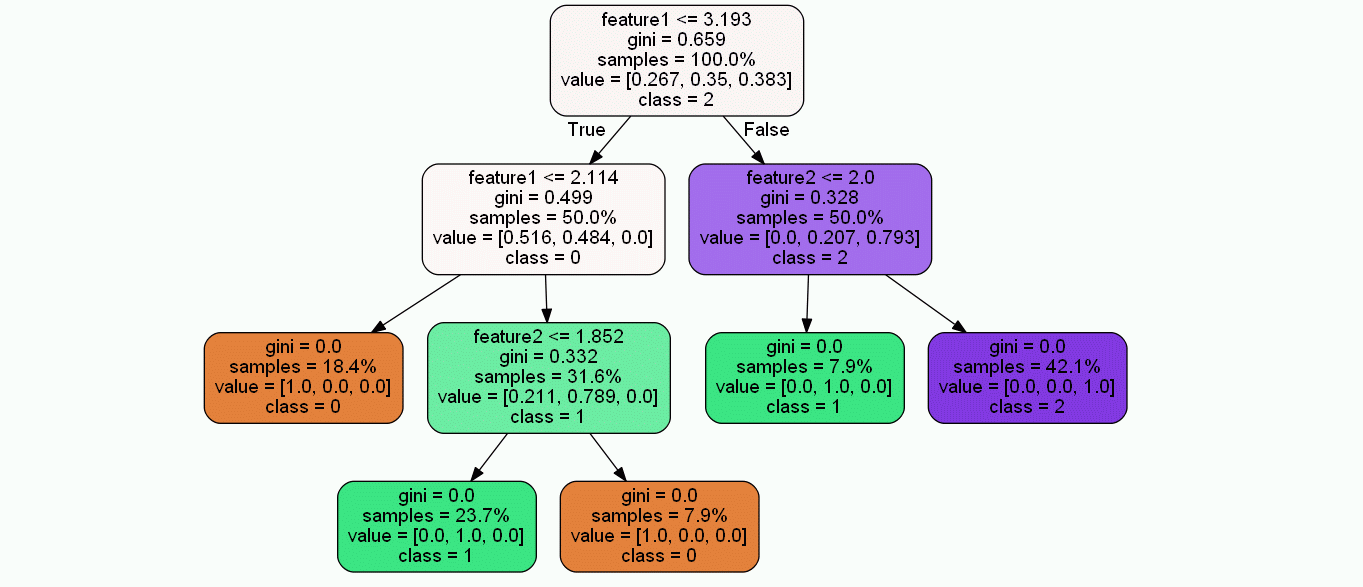
決定木可視化画像のスケーリングと位置調整の手順
ランダムフォレストから全決定木の.dotファイルを作成するPythonコード
以下のコードは「Python機械学習!ランダムフォレストの概要とsklearnコード」で紹介した全コードに「tree.export_graphviz」で.dotファイルを作成する部分を追加しただけです。
このコードを実行する.pyファイルがあるフォルダ内に「dir」フォルダを作っておくと、そのフォルダの中にランダムフォレストで構築された全決定木の.dotファイルが自動ナンバリングされて作成されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn import tree from matplotlib import pyplot as plt # データを用意する------------------------------------------ df = pd.DataFrame() # データフレーム初期化 n = 20 # 1クラス毎のデータ数 for i in range(3): # データ作成ループ if i == 0: x = pd.Series(np.random.uniform(0.5, 2.8, n)) y = pd.Series(x * np.random.uniform(0.8, 1.2, n)) elif i == 1: x = pd.Series(np.random.uniform(2.2, 3.8, n)) y = pd.Series(np.random.uniform(0.5, 1.8, n)) else: x = pd.Series(np.random.uniform(3.2, 3.8, n)) y = pd.Series(np.random.uniform(2.2, 3.8, n)) label = pd.Series(np.full(n, i)) # ラベル(クラス)を作成 temp_df = pd.DataFrame(np.c_[x, y, label]) # クラス毎のデータフレームを作成 df = pd.concat([df, temp_df]) # 作成されたクラス毎のデータを逐次結合 df.index = np.arange(0, len(df), 1) # index(行ラベル)を初期化 # クラス毎のデータフレームに分離(プロット用) class_0 = df[df[2] == 0] # ラベル0を抽出 class_1 = df[df[2] == 1] # ラベル1を抽出 class_2 = df[df[2] == 2] # ラベル2を抽出 # ---------------------------------------------------------- # 学習させる値(訓練データ)とクラス(正解ラベル)に分離 data = df[[0, 1]] # 訓練データ data_class = pd.Series(df[2]) # 正解ラベル # 決定木による学習 clf = RandomForestClassifier(n_estimators=100, # 決定木の数 criterion='gini', # 不純度評価指標の種類(ジニ係数) max_depth=3, # 木の深さ min_samples_leaf=1, # 1ノード(葉)の最小クラス数 max_features='auto') # 最大特徴量数 clf.fit(data, data_class) # フィッティング r2 = clf.score(data, data_class) # 決定係数を算出 # dotファイルの生成 for j in range(len(clf.estimators_)): tree.export_graphviz(clf.estimators_[j], out_file='dir\\'+'tree'+str("{:03}".format(j))+'.dot', # 決定木の.dotファイル名自動ナンバリング filled=True, # 色を塗る rounded=True, # 角を丸める feature_names=['feature1', 'feature2'], # 特徴量名 class_names=['0', '1', '2'], # クラス名 proportion=True) # 位置調整True # 決定境界可視化用 grid_line = np.arange(-10, 10, 0.05) # グリッドデータのための配列を生成 X, Y = np.meshgrid(grid_line, grid_line) # グリッドを作成 Z = clf.predict(np.array([X.ravel(), Y.ravel()]).T) # .predictが使えるデータshapeに変換して予測 Z = Z.reshape(X.shape) # 3Dプロットするためにshapeを再変換 # ここからグラフ描画---------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' fig = plt.figure() ax1 = plt.subplot(111) # グラフの上下左右に目盛線を付ける。 ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('x') ax1.set_ylabel('y') # スケールの設定をする。 ax1.set_xlim(0, 4) ax1.set_ylim(0, 4) # データプロットする。 ax1.contourf(X, Y, Z, cmap='coolwarm') ax1.scatter(class_0[0], class_0[1], label='class=0', edgecolors='black') ax1.scatter(class_1[0], class_1[1], label='class=1', edgecolors='black') ax1.scatter(class_2[0], class_2[1], label='class=2', edgecolors='black') plt.text(0.5, 2.2, '$\ R^{2}=$' + str(round(r2, 2)), fontsize=20) plt.legend() # グラフを表示する。 plt.show() plt.close() # ---------------------------------------------------------- |
全決定木の.dotファイルを画像にするバッチファイル
次に、「Python決定木可視化!Graphvizの導入とdot処理方法」で可視化した時の「dot -Tpng 入力ファイル(.dot) -o 出力ファイル(.png)」コマンドをWindowsバッチファイルのforループを使って自動で.png画像に変換します。
このバッチファイルは.pyファイルと同じ位置に置いて実行します。事前にGraphvizは先ほどの記事に従ってインストールしてあります。
|
1 2 3 4 5 6 |
cd dir set EXT=.png for %%i in (*.dot) do ( dot -Tpng %%i -o %%~ni%EXT% echo %%~ni ) |
echo offにしなかったり、ループの最後にechoを書いているのは、実行されていることがわかるようにという意味がありますが、無くても構いません。
このファイルを実行するとdirフォルダの中に自動ナンバリングされた.png画像が作成されます。
決定木のルートノードの位置と画像サイズをそろえるPython画像処理コード
全コード
最後に、最終目的である「全決定木のルートノードと画像サイズをそろえるPythonコード」を紹介します。
この.pyファイルもその他.pyファイルやバッチファイルと同じ場所に入れて実行します。
実行すると、全ての決定木画像の画像サイズが同じになり、ルートノードが中央揃えになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import glob import os import cv2 import numpy as np def root_node_adjuster(dir): path_list = glob.glob(dir + '\*.png') # 指定されたディレクトリ内の.pngファイルを取得 h_list = [] # 全画像の高さサイズリスト初期化 w_list = [] # 全画像の幅サイズリスト初期化 root_w_list = [] # 全画像のルートノード幅リスト初期化 root_c_list = [] # 全画像のルートノード中心位置リスト初期化 img_list = [] # 画像リスト初期化 for i in range(len(path_list)): # 全画像のサイズとルート位置情報を取得するループ img = cv2.imread(path_list[i], 1) # カラー画像として読み込み img_list.append(img) h, w, ch = img.shape[:3] # 縦(h)横(w)画像サイズを取得 h_list.append(h) # hをリストに追加 w_list.append(w) # wをリストに追加 img_g = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 二値化のためのグレースケール化 ret, i_binary = cv2.threshold(img_g, # 二値化処理 250, # 閾値(この値以上が白) 255, # 画像の最大輝度値 cv2.THRESH_BINARY) # 実行アルゴリズム(単純二値化) line = i_binary[50, :] # ルートノードのボックス部分を横方向にスライス index = np.where(line == 0) # 0と一致する指標を検索 index = np.array(list(index)).ravel() # 1D配列化 root_w = index[-1] - index[0] # ルートノードの幅 root_c = int(index[0] + root_w / 2) # ルートノードの幅方向中心座標 root_w_list.append(root_w) # root_wをリストに追加 root_c_list.append(root_c) # root_cをリストに追加 h_max = np.max(h_list) # 全画像の中で最大高さを算出 w_max = np.max(root_c_list) * 2 # 背景画像のサイズを設定(ルートノードが最も右にあるものを中心にする) size = h_max, w_max, 3 for j in range(len(path_list)): # 全画像(決定木)のルートノード位置を補正するループ img_out = np.full(size, 255) # 出力するベース画像を白紙にする img_roi = img_list[j] # 決定木画像(カラー)をリストから取り出す calibration = int((w_max / 2) - root_c_list[j]) # 幅方向補正量 # ベースの白紙画像にルートノードで位置補正した決定木画像を貼り付ける img_out[0:h_list[j], calibration:calibration + w_list[j]] = img_roi file = os.path.basename(path_list[j]) # 拡張子ありファイル名を取得 name, ext = os.path.splitext(file) # 拡張子なしファイル名と拡張子を取得 out_path = os.path.join(*[dir, 'cal_' + name + ext]) # 保存パスを作成 cv2.imwrite(out_path, img_out) # 補正後の画像を保存 return root_node_adjuster('dir') |
以下より概要を説明します。
画像を2値化してルートノードの両端エッジ座標を取得する
ルートノードは横方向の位置を合わせます。
それぞれの画像ルートノードの横方向の位置を取得するために、今回は下の図のように画像を横方向にスライスして四角形の両端エッジを検出しました。
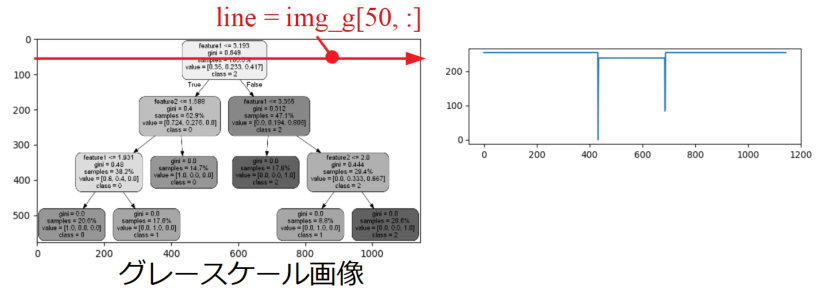
但し、画像を読み込んだだけでは画像の輝度値が安定していないので、以下の画像のように二値化してからスライスし、「index = np.where(line == 0)」と0位置を検索、配列1D化後に始めと最後の要素を取得すれば画像内でルートノードの中心位置が計算可能です。
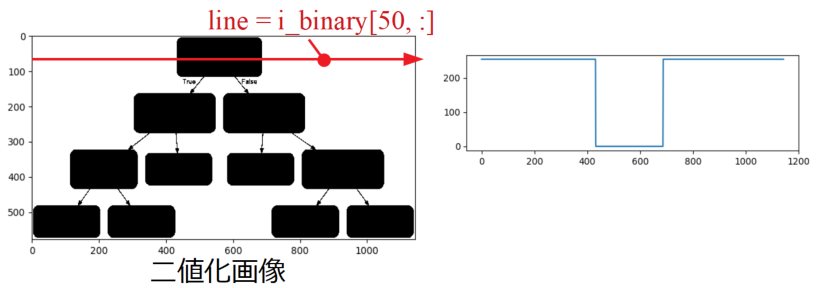
画像の二値化は「Python/OpenCVで画像の二値化をする方法」に詳細を書きましたので、是非参考にして下さい。
背景画像を作成する
画像サイズのスケーリングは各画像をリサイズ等で変えるのではなく(それだと決定木ノードの大きさがまちまちになるため)、背景画像を作成して各決定木画像を貼り付けるということを行っています。
背景画像は全画像の中で最も大きくする必要がありますが、縦サイズは全決定木画像の最大縦サイズ、幅サイズは全決定木画像の中で最大のルートノード中心位置(np.max(root_c_list))の2倍としました。
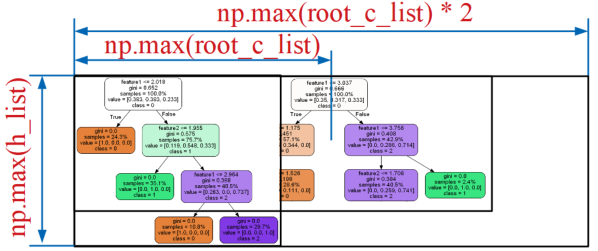
こうすることで全決定木の中で最もルートノードが右に来る画像のルートノード中心(つまり最大画像幅の半分)に全画像のルートノード中心を合わせれば幅方向位置合わせが完了します。
画像を貼り付ける
画像の貼り付けは「Python/OpenCVのROI抽出!領域の切り出しとコピー」で習得したROI抽出の方法をそのまま使っています。ROIは元の決定木画像そのもので、貼り付け先に背景画像、貼り付け位置に補正計算座標値を設定しています。
これらのコードを実行すると、以下のように複数決定木の画像が出来上がります。お好みの方法でGIFにしたり、その他機械学習に利用したりして活用(?)可能と思います。
まとめ
今回の記事は本当に思い付きの内容であまりに無益で申し訳ございませんが、機械学習と画像処理は意外と密接な関係があるのではと思い、これまで習得したコードを組み合わせてみました。
まだ本手法を使った画期的なソリューション等は思いつきませんが、本内容は暇つぶしにでもしていただければと思います。。
今回は正月休みぼけでちょっと「何の役に立つんだ!」感が強い記事でした!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!