
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

機械学習で構築した学習済モデルは通常一度プログラムを終了してしまうとメモリから解放され、再び使うためには再度学習し直さなければなりません。ここでは学習して出来上がったモデルをPythonのpickleを使ってファイルに保存し、再度復元する方法を紹介します。
こんにちは。wat(@watlablog)です。
機械学習は非常に時間がかかるケースもありますが、ここでは一度学習したモデルをファイルに保存し、復元して使うまでの方法を紹介します!
学習済モデルを保存するメリット3選
具体的なコードを紹介する前に、機械学習において、学習済モデルを保存するとどのようなメリットがあるのかを整理してみましょう。
①無駄な計算時間を省くことができる

1つ目のメリットはなんといっても「無駄な計算時間を省くことができる」という点です。
機械学習で学習を行ったモデルは、その後テストデータが何のクラスになるかといった分類問題や、どのような値になるかといった回帰問題を予測するために使います。
機械学習を使った分類や回帰の例として、以下の2つの記事でサポートベクターマシンによる予測の概要を紹介していますので、ご興味のある方は是非参照してみて下さい!
「Python機械学習初心者用!サポートベクターマシンの概要と実装」
「Pythonサポートベクターマシンで回帰分析!SVRの概要と実装」
これらの予測を行う時に、最初から目的のテストデータが全て揃っていることは稀で、大抵はデータを測定した時に都度予測器としてモデルを使います。
機械学習のデータは次元が増えれば増えるほど学習に時間がかかってしまうので、毎回トレーニングデータを使った学習からやり直すのは非常に効率が悪いです。
一度学習をしたモデルをファイルとして保存し再利用可能な状態にしておけば、予測する時に学習からやり直さなくても良いというメリットがあります。
②学習の経過を記録することができる
2つ目のメリットは「学習の経過を記録することができる」点です。
機械学習ではデータの前処理、学習アルゴリズムの選定、ハイパーパラメータの調整…と様々な工程を経てモデル構築を行います。
つまり一回の学習で実用的なモデルになるケースはほとんどなく、通常はいくつかのトライを行います。
この時に、学習内容の異なるモデル同士で精度を比較する場合にも、モデルがファイルとして保存されていれば簡単に参照することができ、かつ管理も容易になるメリットがあります。
③第3者に配布することができる
3つ目のメリットは「第3者に配布することができる」点です。
複数人で機械学習プロジェクトを推進している人や、開発した学習済モデルをインターネットを使って配布したい人は、モデルがファイルになっていた方が送受信が楽になります。
モデルファイルを使わない場合はトレーニングデータと学習コードを送信することになり、受信者は再度学習計算からプログラムを実行しなければなりません。
1つ目のメリットと似ていますが、学習済モデルをファイルとして残すのは、しなくても良い計算を極力しないスマートな方法であると言えます。
ここでは機械学習の学習済モデルをファイルとして保存する1つの方法として、pickleというライブラリを使う方法を紹介します!
pickleで学習済モデルを保存することができる
pickleとは?
pickleとは、Pythonで作成したオブジェクトの状態をファイルとして保存したり、保存したオブジェクトをファイルから読み取り復元することを可能にするライブラリです。
「オブジェクトの状態をファイルに保存する」とは、プログラム上で得られたオブジェクト(機械学習で.fitした後のmodel等)をバイト列に変換することを意味し、シリアライズ(Serialize)、または直列化すると言います。
その反対に、保存されたオブジェクトを読み込みプログラム上で復元することをデシリアライズ(Deserialize)または非直列化すると言います。
pickleはインストールしなくても良い
pickleはPython標準ライブラリであるため、Python本体のインストールがされていれば別途pipインストールをする必要はありません。
ちなみに、本ページで紹介する内容はWindows10 64bit、Python3.7で動作させています。環境の問題で動作出来ない場合もあるかも知れませんが、僕の環境の詳細は「Python入門!初心者がインストールから学習開始するまでの3ステップ」でも紹介していますので必要であれば参考にしてみて下さい。
pickleでオブジェクトを保存・復元するコードはこれだけ!
オブジェクトを保存するコード
pickleでオブジェクトを保存するコードを以下に示します。
ファイルクローズ処理を省略することが出来るためwith構文を使っていますが、本質はpickle.dumpの部分です。ここではmodelというオブジェクトをpickle.dumpでシリアライズし保存しています。
|
1 2 |
with open('model.pickle', mode='wb') as f: # with構文でファイルパスとバイナリ書き込みモードを設定 pickle.dump(model, f) # オブジェクトをシリアライズ |
ファイルはバイナリ形式で保存する必要があるため、mode='wb'としています。
オブジェクトを復元するコード
pickleでオブジェクトを復元するコードを以下に示します。
同じくwith構文を使ってファイル処理をしますが、バイナリ形式のファイルを読むためにmode='rb'としています。実際にオブジェクトを読み込みデシリアライズしている部分はpickle.loadの部分です。
|
1 2 |
with open('model.pickle', mode='rb') as f: # with構文でファイルパスとバイナリ読み来みモードを設定 model = pickle.load(f) # オブジェクトをデシリアライズ |
以下に実際の機械学習プログラムで使う例を紹介します!
Python/pickleで機械学習済モデルを保存・復元するコード
ここでは過去の「Pythonサポートベクターマシンで回帰分析!SVRの概要と実装」という記事で紹介したサポートベクターマシンを使った回帰問題を例に、機械学習済モデルの保存と復元の方法を紹介します。
機械学習済モデルを保存するコード
まずはトレーニングデータを生成して機械学習を行い、モデルを保存するコードを以下に示します。
モデルの保存はmodelオブジェクトを生成し、.fitまでさせた後にpickle.dumpでmodelをシリアライズすれば良いので、テストデータによる確認や決定係数の計算、グラフ化は可視化用途だけで保存とは無関係です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import numpy as np import pickle from sklearn import svm from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D # データを用意する------------------------------------------------------------------ x = np.random.uniform(0, 10, 500) # ノイズを含んだx軸を作成 y = np.random.uniform(0, 10, 500) # ノイズを含んだy軸を作成 z = np.sin(x) * np.cos(y) * np.random.uniform(1, 1.5, 500) # ノイズを含んだz値を作成 X = np.c_[x, y] # SVRが使えるように変数を結合 # --------------------------------------------------------------------------------- # サポートベクターマシンによる学習 model = svm.SVR(C=1.0, kernel='rbf', gamma='auto', epsilon=0.1) # RBFカーネルを使用 model.fit(X, z) # フィッティング # 学習済モデルを使って予測 grid_line = np.arange(0, 10, 0.5) # 回帰式の軸を作成 X2, Y2 = np.meshgrid(grid_line, grid_line) # グリッドを作成 Z2 = model.predict(np.array([X2.ravel(), Y2.ravel()]).T) # 予測 Z2 = Z2.reshape(X2.shape) # プロット用にデータshapeを変換 r2 = model.score(X, z) # 決定係数算出 with open('model.pickle', mode='wb') as f: # with構文でファイルパスとバイナリ書き込みモードを設定 pickle.dump(model, f) # オブジェクトをシリアライズ # ここからグラフ描画---------------------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # グラフの入れ物を用意する。 fig = plt.figure() ax1 = Axes3D(fig) # 軸のラベルを設定する。 ax1.set_xlabel('x') ax1.set_ylabel('y') ax1.set_zlabel('z') # データプロットする。 ax1.scatter3D(x, y, z, label='Dataset') ax1.plot_wireframe(X2, Y2, Z2, label='Regression plane K=rbf') plt.legend() # グラフ内に決定係数を記入 ax1.text(0.0, 0.0, 1.5, zdir=(1,1,0), s='$\ R^{2}=$' + str(round(r2, 2)), fontsize=20) # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------------------------------------- |
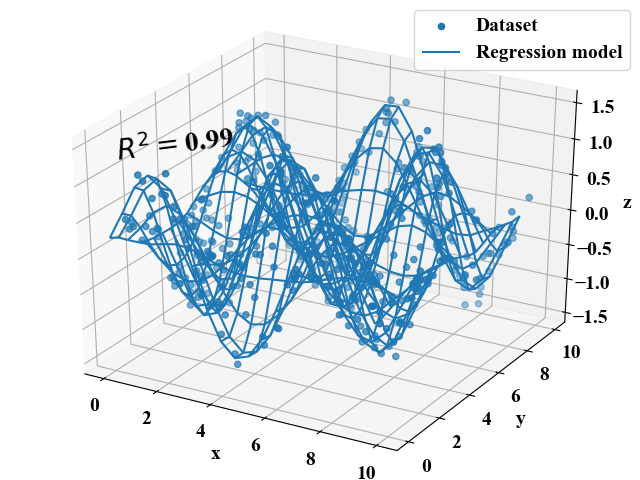
上記コードを実行すると、以下の結果を得ます。トレーニングデータに対し、決定係数が0.99という精度の高い回帰モデルが出来上がりました。
機械学習済モデルを復元するコード
続いてモデルを復元するコードを以下に示します。
このコードはトレーニングデータを用いず、最初にpickle.loadでモデルオブジェクトをデシリアライズする所からスタートします。学習を行わず、ファイルから復元したモデルを使って回帰モデルのグラフ化をしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import numpy as np import pickle from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D with open('model.pickle', mode='rb') as f: # with構文でファイルパスとバイナリ読み込みモードを設定 model = pickle.load(f) # オブジェクトをデシリアライズ # 学習済モデルを使って予測 grid_line = np.arange(0, 10, 0.5) # 回帰式の軸を作成 X2, Y2 = np.meshgrid(grid_line, grid_line) # グリッドを作成 Z2 = model.predict(np.array([X2.ravel(), Y2.ravel()]).T) # 予測 Z2 = Z2.reshape(X2.shape) # プロット用にデータshapeを変換 # ここからグラフ描画---------------------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # グラフの入れ物を用意する。 fig = plt.figure() ax1 = Axes3D(fig) # 軸のラベルを設定する。 ax1.set_xlabel('x') ax1.set_ylabel('y') ax1.set_zlabel('z') # データプロットする。 ax1.plot_wireframe(X2, Y2, Z2, label='Restored model') plt.legend() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------------------------------------- |
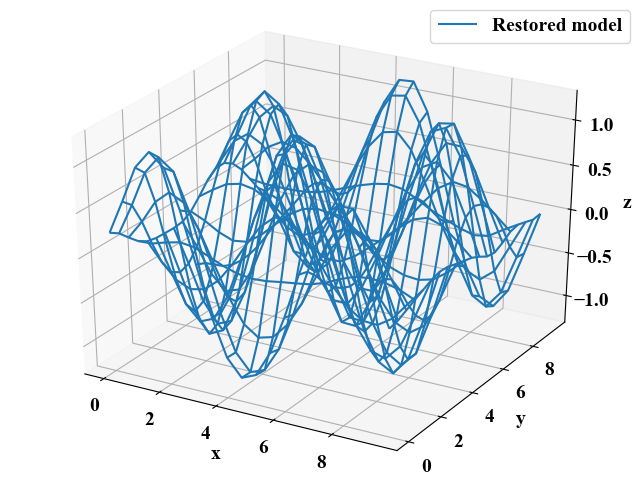
以下の図が上記コード実行で得られる結果です。見事ファイルだけでオリジナルの回帰モデルを再現することが出来ました。
まとめ
本ページでは機械学習済のモデルをファイルとして保存するためのメリットを3つ説明し、Python標準ライブラリであるpickleを使って実際の機械学習モデルの保存と復元効果を確かめました。
本方法を使うことで様々な学習モデルを使ったトライ計算の効率が向上し、簡単に第3者への配布もできるようになる見込みです。
モデルの保存は機械学習の運用面で重宝しそうですね!Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント