
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

商用ソフトの中にはテキストファイルで設定を用意するものが多くあります。テキストファイルをプログラム的に処理する事で業務自動化が可能です。ここではPythonを使ってテキストファイルの中身を特定のキーワードで検索し、任意の設定値を取得するコード例を紹介します。
こんにちは。wat(@watlablog)です。今回はテキストファイル内のキーワード検索をやってみます!
この記事はメモ的に書いているので、目次から参照したい項目へジャンプしてご活用ください。
例題のテキストファイル
今回は以下のサンプルファイルを使います。
「Pythonでテキストファイルの読み書きをする時のメモ」でファイルの読み書きを学びましたが、今回は検索できるようになる事を目標にちょっと長い文にしています。
このテキストはとあるソフトの設定ファイルを模擬していますが、手入力で作成したため本物のフォーマットと異なる可能性があります(あくまでサンプル)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
$ *MAT Hogehoge Hogehoge Hogehoge $ *SET_NODE_LIST $ Title $ sid da1 da2 da3 da4 solver 1 0.0000000 0.0000000 0.0000000 0.0000000 MECH $ nid1 nid2 nid3 nid4 nid5 nid6 nid7 nid8 1 3 5 7 9 11 13 15 17 18 19 20 21 22 $ *SET_NODE_LIST $ Title $ sid da1 da2 da3 da4 solver 2 0.0000000 0.0000000 0.0000000 0.0000000 MECH $ nid1 nid2 nid3 nid4 nid5 nid6 nid7 nid8 2 4 6 8 10 12 14 16 $ *NODE $ nid x y z tc rc 1-10.000000000000-11.000000000000-12.000000000000 2-13.000000000000-14.000000000000-15.000000000000 3-16.000000000000-17.000000000000-18.000000000000 4-19.000000000000-20.000000000000-21.000000000000 5-22.000000000000-23.000000000000-24.000000000000 6-25.000000000000-26.000000000000-27.000000000000 7-28.000000000000-29.000000000000-30.000000000000 8-31.000000000000-32.000000000000-33.000000000000 9-34.000000000000-35.000000000000-36.000000000000 10-37.000000000000-38.000000000000-39.000000000000 11-40.000000000000-41.000000000000-42.000000000000 12-43.000000000000-44.000000000000-45.000000000000 13-46.000000000000-47.000000000000-48.000000000000 14-49.000000000000-50.000000000000-51.000000000000 15-52.000000000000-53.000000000000-54.000000000000 16-55.000000000000-56.000000000000-57.000000000000 17-55.000000000000-56.000000000000-57.000000000000 18-55.000000000000-56.000000000000-57.000000000000 19-55.000000000000-56.000000000000-57.000000000000 20-55.000000000000-56.000000000000-57.000000000000 21-55.000000000000-56.000000000000-57.000000000000 22-55.000000000000-56.000000000000-57.000000000000 *END |
CAE屋さんならピンと来るファイル内容かも知れませんが、ここでは「あるルールに則って文字列で記録された設定ファイル」という理解で十分でしょう。
テキスト検索を活用したPythonコード例
キーワードが何行目にあるか検索するコード
文字列完全一致/行内位置指定で検索
ファイル全体から特定のキーワードが何行目にあるのか検索する事を行いますが、まずは完全に位置を指定してしまう事を考えます。
以下のコードはopen_text_line()関数でファイルを行単位で読み込み、search_keyword()関数に読み込んだリスト形式のテキストと検索したいキーワードを与えて、キーワードが何行目にあるかを探すだけのコードです。
検索キーワードの長さを計算し、抽出した行データから文字を取り出して「==」演算子で比較をしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# テキストを行単位で読みリストに格納する def open_text_line(filename): with open(filename, 'rt') as f: text = f.readlines() return text # 指定したキーワードが何行目にあるか調べる関数 def search_keyword(text, keyword): count = [] for i in range(len(text)): line = text[i] len_word = len(keyword) # 検索キーワードの文字長さ以上で実行 if len(line) >= len_word: # 検索キーワードとリストの先頭文字が完全一致したら行数をappend if line[:len_word] == keyword: count.append(i) return count # ファイル読み込み filename = 'search-sample.txt' text_line = open_text_line(filename) # 「*SET_NODE」という文が何行目にあるか検索する lines = search_keyword(text_line, '*SET_NODE') print('Lines that match the keyword:', lines) |
以下が結果です。6行目と15行目(0からカウント)にキーワードがある正解を得ました。
|
1 |
Lines that match the keyword: [6, 15] |
文字列完全一致/行内位置不定で検索(.find)
上記コードは位置を完全に指定していましたが、.findメソッドを使えばもっと簡単に書けます。
.find()は文字列の中に検索キーワードが無い場合に-1を返し、ある場合は何文字目からかを示す位置情報が返って来ます。そのため、if文では-1かどうかを見ています。
|
1 2 3 4 5 6 7 8 9 |
# 指定したキーワードが何行目にあるか調べる関数 def search_keyword(text, keyword): count = [] for i in range(len(text)): line = text[i] # 検索キーワードとリストの文字列がある場合append(.findが-1なら無い。ある場合は位置が返ってくる) if line.find(keyword) != -1: count.append(i) return count |
文字列を一部含むか/行内位置不定で検索(in)
in演算子を使えば文字列が完全一致しなくても、一部でも含めば検索にヒットします。以下のコードは「NODE」を検索。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# テキストを行単位で読みリストに格納する def open_text_line(filename): with open(filename, 'rt') as f: text = f.readlines() return text # 指定したキーワードが何行目にあるか調べる関数 def search_keyword(text, keyword): count = [] for i in range(len(text)): line = text[i] # 検索キーワードとリストの文字列がある場合append(.findが-1なら無い。ある場合は位置が返ってくる) if (keyword in line): count.append(i) return count # ファイル読み込み filename = 'search-sample.txt' text_line = open_text_line(filename) # 「NODE」という文が何行目にあるか検索する lines = search_keyword(text_line, 'NODE') print('Lines that match the keyword:', lines) |
「*SET_NODE」2つと「*NODE」にヒットしました。
|
1 |
Lines that match the keyword: [6, 15, 23] |
指定した文字列が整数に変換できるかどうかで検索(try/except)
こちらはint型に変換できるかどうかを調べるためのコード。tryとexceptを使ってエラー検出するという方法を使ってみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 整数に変換できる行を調査する関数 def istrans_int(text): count = [] for i in range(len(text)): try: int(text[i]) except ValueError: ret = False else: ret = True if ret: count.append(i) return count # テキスト文字列を定義 text = ['000', 'aaa', '1'] # 整数に変換できる行を調査する関数を実行 lines = istrans_int(text) print('Lines that match the keyword:', lines) |
変換できたのは'000'と'1'だけでしたので正解を得ました。intをfloatにすれば浮動小数点型にも対応する事ができます。
|
1 |
Lines that match the keyword: [0, 2] |
応用例:サンプルファイルから座標値を抽出するコード
ここから先は応用例です。応用例なので実際の使用には各自でコードをチューニングする必要がありますが、単なる事例として参考にメモしておきます。
目標
テキストファイル内のとあるid値に対応する座標を抽出する
手順
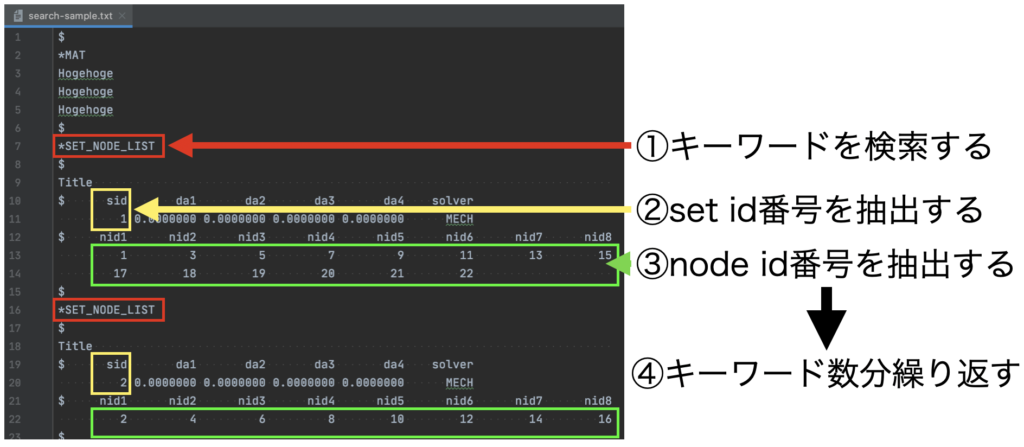
- ①キーワードを検索する
テキストファイル内に複数ある「*NODE_SET」(nidをグループ化しているキーワード)を検索します。 - ②set id番号を抽出する
「*NODE_SET」キーワードは固有のsid番号で管理されているため、この番号を抽出します。 - ③node id番号を抽出する
「*NODE_SET」にはnid番号がグルーピングされているため、これを全て抽出します。 - ④キーワード数分繰り返す
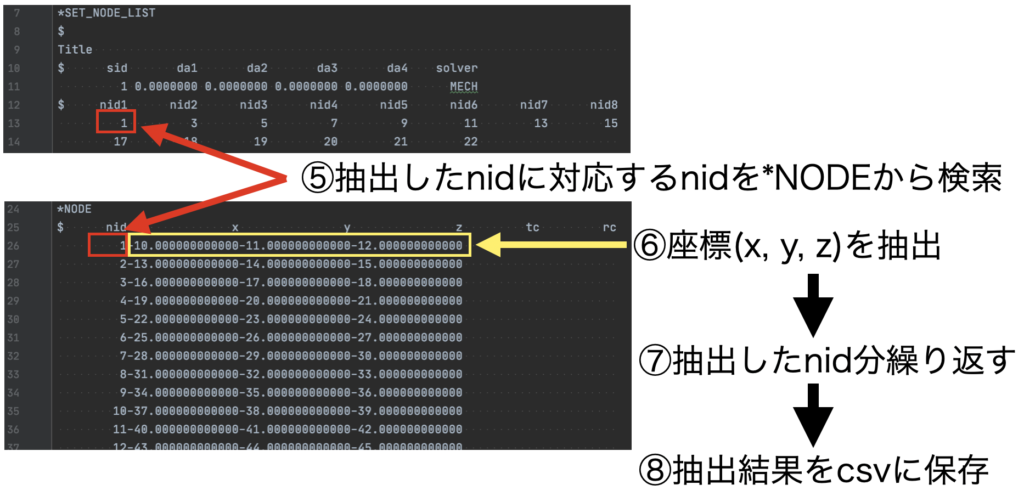
「*NODE_SET」は複数存在する場合があるため、繰り返します。 - ⑤抽出したnidに対応するnidを「*NODE」から検索する
nidは「*NODE」設定と紐付けられているので、対応を検索します。 - ⑥座標(x, y, z)を抽出する
検索にヒットしたid番号のみ、座標値を抽出します(ここが本来目的)。 - ⑦抽出したnid分繰り返す
- ⑧抽出結果をcsvに保存
図にすると以下です。
全コード
csvを扱うためPandasをimportしていますが、それ以外はPythonの標準で記述しています。
上で取り扱った基本的な関数を組み合わせたり改造したりして構成しているので、これを読み解いて理解するというよりは、自分が扱いたいテキストファイルでやりたい事を考え、うまくいく方法の参考にする程度で見る方が良い思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
import pandas as pd # テキストを行単位で読みリストに格納する def open_text_line(filename): with open(filename, 'rt') as f: text = f.readlines() return text # 指定したキーワードが何行目にあるか調べる関数 def search_keyword(text, keyword): count = [] for i in range(len(text)): line = text[i] # 検索キーワードとリストの文字列がある場合append(.findが-1なら無い。ある場合は位置が返ってくる) if line.find(keyword) != -1: count.append(i) return count # sidとnidを抽出する関数 def get_set_node_id(text): # 全てのキーワードと検索したいキーワードの行位置情報を取得 all_key_position = search_keyword(text, '*') nodeset_position = search_keyword(text, '*SET_NODE') # 抽出したい設定値:sid, nid sid = [] nid = [] for i in range(len(nodeset_position)): # キーワードが一致した行において検索設定部分の開始と終了行を計算 # 「*」から「*」までが設定の区切りである事を利用し、endは内包表記でキーワードの次の「*」位置を計算 start = nodeset_position[i] end = [l for l in all_key_position if l > nodeset_position[i]][0] - 1 lines = end - start # 検索された設定部分のみ抽出 searched_line = text[start:end] # sid値を取得して整数型に変換(sidの次の行に設定値が10文字分で記載) sid_offset = search_keyword(searched_line, '$ sid')[0] + 1 sid.append(int(searched_line[sid_offset][:10])) # nid値を配列で取得 nid_offset = search_keyword(searched_line, '$ nid')[0] + 1 temp_node = [] for j in range(lines - nid_offset): # 1行80カラムに10文字ずつ入っている設定値を抽出して整数型にする for k in range(8): id = searched_line[nid_offset + j][(k * 10):(k * 10) + 10] # 整数型に変換できる時のみ設定値を抽出する try: int(id) except ValueError: ret = False else: ret = True if ret: temp_node.append(int(id)) nid.append((temp_node)) # 表にまとめるため、nidの数だけsidをコピーしてSeries化 # 同時にnidもSeries化 copied_sid = [] copied_nid = [] for i in range(len(sid)): copied_sid.append(pd.Series([sid[i]] * len(nid[i]))) copied_nid.append(pd.Series(nid[i])) sid_series = pd.concat(copied_sid, ignore_index=True) nid_series = pd.concat(copied_nid, ignore_index=True) # データフレームにまとめる df = pd.DataFrame() df['sid'] = sid_series df['nid'] = nid_series return df # idからnode座標を抽出する関数 def get_node_coordinate(text, id_list): # 全てのキーワードと検索したいキーワードの行位置情報を取得 all_key_position = search_keyword(text, '*') node_position = search_keyword(text, '*NODE') # キーワードが一致した行において検索設定部分の開始と終了行を計算 # 「*」から「*」までが設定の区切りである事を利用し、endは内包表記でキーワードの次の「*」位置を計算 start = node_position[0] end = [l for l in all_key_position if l > node_position[0]][0] # 検索された設定部分のみ抽出 searched_line = text[start:end] # 座標値を抽出 node_offset = 2 x = [] y = [] z = [] # 総ループ数は先に抽出したid_list数 for i in range(len(id_list)): # whileループ:jが*NODE内の座標数分走査完了 and 検索にヒット(ret=True)で終了(走査を途中で打ち切るため) j = 0 ret = True while j <= len(id_list) - node_offset + 1 and ret: line = searched_line[j + node_offset] extracted_id = int(line[:10]) # 抽出されたidが検索したいidと一致したら決まった文字数で座標を抽出する if extracted_id == id_list[i]: x.append(float(line[10:10 + 16])) y.append(float(line[10 + 16:10 + 16 + 16])) z.append(float(line[10 + 32:10 + 32 + 16])) ret = False j += 1 # PandasのSeriesに変換 x_series = pd.Series(x) y_series = pd.Series(y) z_series = pd.Series(z) # PandasのDataFrameに変換 df = pd.DataFrame() df['x'] = x_series df['y'] = y_series df['z'] = z_series return df # ファイル読み込み filename = 'search-sample.txt' text_line = open_text_line(filename) # テキストからsid値とnid値を紐付けしたデータフレームを作成する df_id = get_set_node_id(text_line) # idからnode座標を抽出する df_coordinate = get_node_coordinate(text_line, df_id['nid']) # DataFrameをまとめてcsvに保存 df = df_id.join(df_coordinate) df.to_csv('node-set-and-coordinate.csv') print(df) |
実行結果
以下が結果です。sid, nid, 座標情報が一つのテーブルにまとまりました。このようにスプレッドシートでまとめる事ができると、その後の処理(この事例では座標変換等)がしやすくなります。
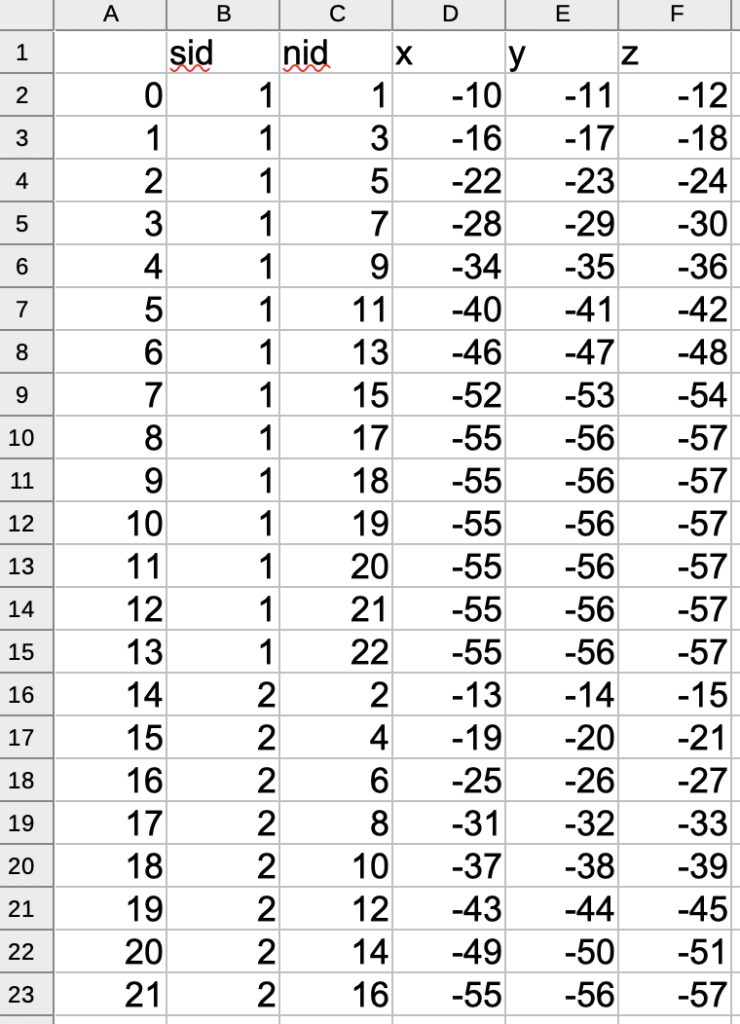
その後の処理もPythonで書く場合は、既にPandasのデータフレームに変換したdfを使う方が効率が良いでしょう。今回のdfには以下のような情報が格納されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
sid nid x y z 0 1 1 -10.0 -11.0 -12.0 1 1 3 -16.0 -17.0 -18.0 2 1 5 -22.0 -23.0 -24.0 3 1 7 -28.0 -29.0 -30.0 4 1 9 -34.0 -35.0 -36.0 5 1 11 -40.0 -41.0 -42.0 6 1 13 -46.0 -47.0 -48.0 7 1 15 -52.0 -53.0 -54.0 8 1 17 -55.0 -56.0 -57.0 9 1 18 -55.0 -56.0 -57.0 10 1 19 -55.0 -56.0 -57.0 11 1 20 -55.0 -56.0 -57.0 12 1 21 -55.0 -56.0 -57.0 13 1 22 -55.0 -56.0 -57.0 14 2 2 -13.0 -14.0 -15.0 15 2 4 -19.0 -20.0 -21.0 16 2 6 -25.0 -26.0 -27.0 17 2 8 -31.0 -32.0 -33.0 18 2 10 -37.0 -38.0 -39.0 19 2 12 -43.0 -44.0 -45.0 20 2 14 -49.0 -50.0 -51.0 21 2 16 -55.0 -56.0 -57.0 |
Pandasは機械学習の前処理、集計といったデータサイエンスが得意なライブラリなので、当ブログではできるだけPandasでテーブルデータを処理しています。
まとめ
本記事はテキストの検索方法として、Pythonで使われている方法やエラー検出の方法を使った例を紹介しました。
また、実際の応用例として、やや複雑なテキストファイルから検索や抽出を使うコードを紹介しました。
なんとなくテキスト検索、抽出の方法がわかってきたと思います!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!