
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ウォーターフォール図は企業のIR資料でよく見かける図ですが、投資家向け以外でも使いこなせば大変説得力のある図となるようです。ここではPythonでウォーターフォール図を描くにはどうしたら良いかを検討した結果を紹介します。
こんにちは。wat(@watlablog)です。ここでは説得力抜群なウォーターフォール図をPythonのmatplotlibだけで描く方法を紹介します!
ウォーターフォール図の概要
ウォーターフォール図とは?
ウォーターフォール図とは、企業のIR情報でおなじみですが、増減や構成を効果的に説明可能なプロットです。
百聞は一見に如かずであるため、以下の図をご覧下さい。
これは今回このページで紹介するPythonコードで作成しました。
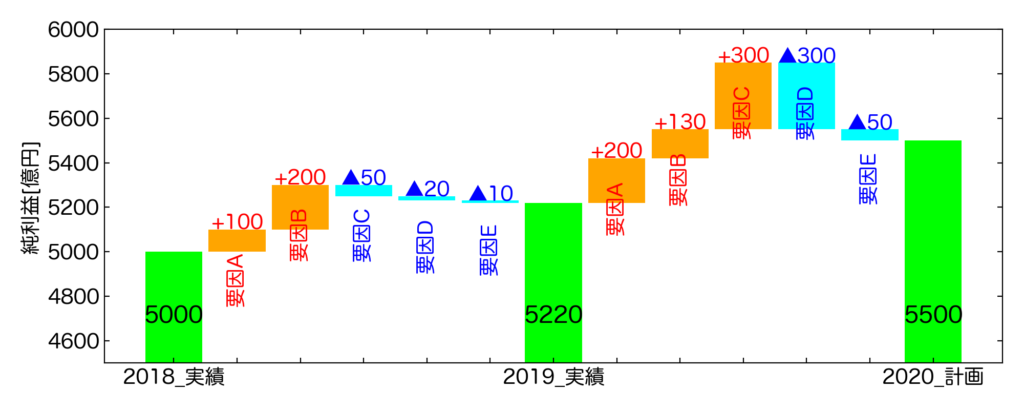
どうでしょうか。各年度の純利益という指標が、どのような要因で変化していったのか、どのように次年度の計画を立てているのかが一目瞭然だと思います。
これをウォーターフォール図を使わないで説明しようとすると、細かい表を示すか、箇条書きの文章で示すか…いずれにしても口頭で色々補足が必要と思います。
ウォーターフォール図について詳しくは、僕のTwitterのフォロワーさんが「ウォータフォール図を使いこなそう(アラサー東大卒のゆとり生活)」で紹介しています。こちらにはExcelを使った描き方の説明があるので、是非ご覧下さい。
ウォーターフォール図を描く動機
僕自身この図は自社のIR情報等でよく見ていたはずなのですが、「これは投資家のための特別な図」と思い込んでいました。
「ウォータフォール図を使いこなそう」の記事がリツイートで回ってきて読んでみると、
使わない手は無い!
と思いました。
ウォーターフォール図の効果である増減要因の説明、数値の構成の説明…というのは技術職でも頻繁に要求されます。効果的な説明図を作れるようになって、会議を短時間で終わらせよう!というのが最も大きなモチベになっています。
プログラムの処理時間の内訳をウォーターフォールで示したり…というのも良さそう??
と思ったら以下のニーズがあるようです(かなり前ですが)。
今、 jupyter notebook 上で、諸々の開始時刻と終了時刻からなるイベントデータを取得していて、それを、この Chrome のウォーターフォール図のような形で図示したいと考えました。
stackoverflow:pythonでプロセス処理時間のウォーターフォール図のようなものを図示したい
これを実現するにあたって、よく使われるライブラリなどはありますか?
本ページのコードがよく使われるライブラリの代わりになれば幸いです。
本ページの目標
スプレッドシート一つ用意して動くようにする
これに尽きます。多くの企業の方はExcel等の表計算ソフトで業務を行っていると思うので、おそらくExcelでフォーマットを作っておく方が便利とは思いますが、プログラミング言語で作るメリットは自動化が可能という所です。
所定のスプレッドシート(今回は.csv)を一つ用意して実行ボタンを押せば、求めたいウォーターフォール図が瞬時に出てくる…という所を目標にします。
ウォーターフォール図用のライブラリは使わない
外部ライブラリは大変便利なもので、時に絶大な効果を発揮します。
しかし、グラフは相手に説明する時に使うもの。僕は割とグラフにはこだわっていますが、説明用の資料は見た目も結構重要と思います。
例えばExcelのデフォルト設定そのままでは見れたものじゃないと思います。皆さん自分でカスタマイズした設定をテンプレートとして登録して使っていると思いますが、専用の外部ライブラリはカスタマイズがやり難いというデメリットがあります。
ウォーターフォール図はバープロット一つ一つの色、テキストの描画、グラフサイズ、フォントサイズや色にこだわって初めて説得力のある図となると思うので、今回は自分で色々変更できるように作ります。
ここでは、Pythonを使った表計算としてデータサイエンス界隈でデファクトスタンダードとなっているPandas、数値計算の代表格Numpy、強力なグラフ描画ライブラリのmatplotlibのみを使う事を目標とします。
Pythonでウォーターフォール図を描くコード
縦向きのウォーターフォール図
まずは縦向きのウォーターフォール図を描いてみます。
スプレッドシートを用意する
今回は以下の情報を記載したスプレッドシートを.csvファイルとして用意しました。日本語の注釈を付けてあり、ファイルは「SHIFT-JIS」でエンコードしています。
SHIFT-JISはExcelで.csvを作成する時はデフォルトだと思います。もちろんこれから紹介するプログラムを最初からExcelを開く仕様にしても使いやすいと思いますが、僕は今回Macで開発したためまずはNumbersで作った.csvでテストします。
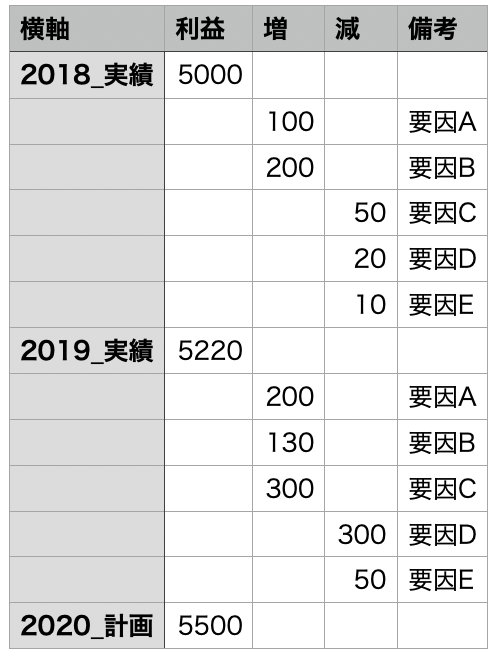
データは横軸、利益、増減、備考とよくあるIR情報のような並びにしてあります。これは「ウォータフォール図を使いこなそう」の例題を参考にしています。
import文
import文はこちら。pandas, numpy, pltはおなじみとして、今回はグラフ内に日本語を使いたいので、rcParamsををimportし、冒頭で宣言してしまいます。
僕はMacですので、「'Hiragino Maru Gothic Pro'」を使いましたが、Windowsの場合は「'Meirio'」とかが良いかも知れません。
|
1 2 3 4 5 6 |
import pandas as pd import numpy as np from matplotlib import pyplot as plt from matplotlib import rcParams rcParams['font.family'] = 'sans-serif' rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro'] |
Pandasでスプレッドシートを読み込む
スプレッドシートは何かと便利なPandasというライブラリを使って読み込みます。今回SHIFT-JISでエンコードしているので、encodingの指定も必要です。
|
1 2 3 4 |
# ファイルを読み込む df = pd.read_csv('waterfall-sample.csv', encoding='SHIFT-JIS') print(df) |
読み込んだデータは以下となります。空白部分はNaN(Not a Number)となっていますが、そのままにします。
この構成でスプレッドシートを作成すれば、後は自由に行を追加して使用して頂く事が可能です。もちろんこの構成でPandasデータフレーム型の変数を直接作成すれば、スプレッドシートを用意する必要も無くなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
横軸 利益 増 減 備考 0 2018_実績 5000.0 NaN NaN NaN 1 NaN NaN 100.0 NaN 要因A 2 NaN NaN 200.0 NaN 要因B 3 NaN NaN NaN 50.0 要因C 4 NaN NaN NaN 20.0 要因D 5 NaN NaN NaN 10.0 要因E 6 2019_実績 5220.0 NaN NaN NaN 7 NaN NaN 200.0 NaN 要因A 8 NaN NaN 130.0 NaN 要因B 9 NaN NaN 300.0 NaN 要因C 10 NaN NaN NaN 300.0 要因D 11 NaN NaN NaN 50.0 要因E 12 2020_計画 5500.0 NaN NaN NaN |
Pandasのファイル読み込みについては「Python/Pandasなら文字数値混在csvも簡単読み込み!」も併せてご覧下さい。
初期化
上記スプレッドシートの内容を読み解いたり、計算したりするのにリスト型を使って整理していきます。
layerを2つ作っていますが、これは棒グラフで色を付けたい部分と消したい部分(マスク)を表現するために必要となります。flagは格納したデータが増減のどちらかなのか、それともメインデータなのかを判断するためのフラグです。
|
1 2 3 4 5 6 |
# リストの初期化 label = [] # ラベル layer1 = [] # レイヤー1(増の時色付け、減の時マスク) layer2 = [] # レイヤー2(増の時マスク、減の時色付け) discription = [] # 備考テキスト flag = [] # フラグ |
ウォーターフォール図用データの作成
データフレームの行数でループを回し、上からデータを抽出していきます。
但し、抽出したデータが何なのか(増?減?それともメインの実績?)をNaNを使って判定し、自動分類していきます。
分類した結果は先ほどのflagにappendしていき、後でプロット時に使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# ウォーターフォール図に必要なデータを1行ずつ抽出 for i in range(len(df)): # 最初の要素がNaNであれば増減データを抽出する if pd.isnull(df.iloc[i][0]): label.append('') # ラベル(増減の場合は空白) if pd.isnull(df.iloc[i][2]): # 減の項目 layer1.append(layer1[i - 1] - df.iloc[i][3]) # マスク部分 layer2.append(layer1[i - 1]) # 色付ける部分 discription.append(df.iloc[i][4]) # 備考 flag.append(-1) # 減のデータとわかるよう-1を格納する else: # 増の項目 layer1.append(layer1[i - 1] + df.iloc[i][2]) # 色付ける部分 layer2.append(layer1[i - 1]) # マスク部分 discription.append(df.iloc[i][4]) # 備考 flag.append(1) # 増のデータとわかるよう1を格納する # 最初の要素がNaNでない場合はメインラベルのデータとする else: label.append(df.iloc[i][0]) # メインラベル layer1.append(df.iloc[i][1]) # 色を付ける部分 layer2.append(0) # メインデータはマスク0 discription.append(df.iloc[i][4]) # 備考(現在は機能していない) flag.append(0) # メインデータとわかるよう0を格納する axis = np.arange(0, len(df), 1) # バープロット用横軸を作る |
プロット
ウォータフォール図はプロット部分もキーポイントです。
flagの値に応じてプロットの色、テキストの書式や内容を変更しています。特に増加データ(flag==1)と減少データ(flag==-1)だとbar()内のlayer1, layer2の順序が事なっている所が注意点です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# ここからグラフ描画------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(10, 4)) ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_ylabel('純利益[億円]') # スケールの設定をする。 ax1.set_ylim(4500, 6000) # データプロットする。 # フラグ毎に色付けとマスクの関係を分けている。 for i in range(len(df)): # メインデータの場合 if flag[i] == 0: ax1.bar(axis[i], layer1[i], width=0.9, color='lime') ax1.text(axis[i], np.max(layer1) - (np.max(layer1) / 5), str(int(layer1[i])), horizontalalignment='center', fontsize=16) # 増加データの場合 elif flag[i] == 1: ax1.bar(axis[i], layer1[i], width=0.9, color='orange') ax1.bar(axis[i], layer2[i], width=0.9, color='white') ax1.text(axis[i], layer1[i], '+' + str(int(layer1[i] - layer2[i])), horizontalalignment='center', fontsize=14, color='red') ax1.text(axis[i], layer1[i] - 100, discription[i], horizontalalignment='center', verticalalignment='top', fontsize=14, color='red', rotation='vertical') # 減少データの場合 else: ax1.bar(axis[i], layer2[i], width=0.9, color='cyan') ax1.bar(axis[i], layer1[i], width=0.9, color='white') ax1.text(axis[i], layer2[i], '▲' + str(int(layer2[i] - layer1[i])), horizontalalignment='center', fontsize=14, color='blue') ax1.text(axis[i], layer2[i] - 100, discription[i], horizontalalignment='center', verticalalignment='top', fontsize=14, color='blue', rotation='vertical') plt.xticks(ticks=axis, labels=label) # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- |
全コード(コピペ用)
ここにコピペしてすぐに動かせるように全コードを載せておきます。以下にサンプルのcsvファイルもアップロードしておきますので、もし手元にデータが無い場合はお使い下さい。
全コードではdef関数形式にまとめています。ファイル名を引数に実行するだけにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
import pandas as pd import numpy as np from matplotlib import pyplot as plt from matplotlib import rcParams rcParams['font.family'] = 'sans-serif' rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro'] def plot_waterfall_chart(filename): # ファイルを読み込む df = pd.read_csv(filename, encoding='SHIFT-JIS') # リストの初期化 label = [] # ラベル layer1 = [] # レイヤー1(増の時色付け、減の時マスク) layer2 = [] # レイヤー2(増の時マスク、減の時色付け) discription = [] # 備考テキスト flag = [] # フラグ # ウォーターフォール図に必要なデータを1行ずつ抽出 for i in range(len(df)): # 最初の要素がNaNであれば増減データを抽出する if pd.isnull(df.iloc[i][0]): label.append('') # ラベル(増減の場合は空白) if pd.isnull(df.iloc[i][2]): # 減の項目 layer1.append(layer1[i - 1] - df.iloc[i][3]) # マスク部分 layer2.append(layer1[i - 1]) # 色付ける部分 discription.append(df.iloc[i][4]) # 備考 flag.append(-1) # 減のデータとわかるよう-1を格納する else: # 増の項目 layer1.append(layer1[i - 1] + df.iloc[i][2]) # 色付ける部分 layer2.append(layer1[i - 1]) # マスク部分 discription.append(df.iloc[i][4]) # 備考 flag.append(1) # 増のデータとわかるよう1を格納する # 最初の要素がNaNでない場合はメインラベルのデータとする else: label.append(df.iloc[i][0]) # メインラベル layer1.append(df.iloc[i][1]) # 色を付ける部分 layer2.append(0) # メインデータはマスク0 discription.append(df.iloc[i][4]) # 備考(現在は機能していない) flag.append(0) # メインデータとわかるよう0を格納する axis = np.arange(0, len(df), 1) # バープロット用横軸を作る # ここからグラフ描画------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(10, 4)) ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_ylabel('純利益[億円]') # スケールの設定をする。 ax1.set_ylim(4500, 6000) # データプロットする。 # フラグ毎に色付けとマスクの関係を分けている。 for i in range(len(df)): # メインデータの場合 if flag[i] == 0: ax1.bar(axis[i], layer1[i], width=0.9, color='lime') ax1.text(axis[i], np.max(layer1) - (np.max(layer1) / 5), str(int(layer1[i])), horizontalalignment='center', fontsize=16) # 増加データの場合 elif flag[i] == 1: ax1.bar(axis[i], layer1[i], width=0.9, color='orange') ax1.bar(axis[i], layer2[i], width=0.9, color='white') ax1.text(axis[i], layer1[i], '+' + str(int(layer1[i] - layer2[i])), horizontalalignment='center', fontsize=14, color='red') ax1.text(axis[i], layer1[i] - 100, discription[i], horizontalalignment='center', verticalalignment='top', fontsize=14, color='red', rotation='vertical') # 減少データの場合 else: ax1.bar(axis[i], layer2[i], width=0.9, color='cyan') ax1.bar(axis[i], layer1[i], width=0.9, color='white') ax1.text(axis[i], layer2[i], '▲' + str(int(layer2[i] - layer1[i])), horizontalalignment='center', fontsize=14, color='blue') ax1.text(axis[i], layer2[i] - 100, discription[i], horizontalalignment='center', verticalalignment='top', fontsize=14, color='blue', rotation='vertical') plt.xticks(ticks=axis, labels=label) # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- # ウォーターフォール図を描く関数を実行 plot_waterfall_chart('waterfall-sample.csv') |
本コードはMITライセンスの考え方を採用してありますので、ご自由に使用して頂いて構いません。
実行結果
上記コードを実行すると、以下の結果を得ます。サイズや位置、色といった設定はコードをお好みで変更して下さい。
横向きのウォーターフォール図
全コード(コピペ用)
ウォーターフォール図は横向きで使う事もあります。以下に横向きの場合の全コードを載せます。
変更点はaxisを逆順にしたり、プロット部分のhorizontalとverticalの変更、テキストの座標変更のみです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
import pandas as pd import numpy as np from matplotlib import pyplot as plt from matplotlib import rcParams rcParams['font.family'] = 'sans-serif' rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro'] def plot_waterfall_chart(filename): # ファイルを読み込む df = pd.read_csv(filename, encoding='SHIFT-JIS') # リストの初期化 label = [] # ラベル layer1 = [] # レイヤー1(増の時色付け、減の時マスク) layer2 = [] # レイヤー2(増の時マスク、減の時色付け) discription = [] # 備考テキスト flag = [] # フラグ # ウォーターフォール図に必要なデータを1行ずつ抽出 for i in range(len(df)): # 最初の要素がNaNであれば増減データを抽出する if pd.isnull(df.iloc[i][0]): label.append('') # ラベル(増減の場合は空白) if pd.isnull(df.iloc[i][2]): # 減の項目 layer1.append(layer1[i - 1] - df.iloc[i][3]) # マスク部分 layer2.append(layer1[i - 1]) # 色付ける部分 discription.append(df.iloc[i][4]) # 備考 flag.append(-1) # 減のデータとわかるよう-1を格納する else: # 増の項目 layer1.append(layer1[i - 1] + df.iloc[i][2]) # 色付ける部分 layer2.append(layer1[i - 1]) # マスク部分 discription.append(df.iloc[i][4]) # 備考 flag.append(1) # 増のデータとわかるよう1を格納する # 最初の要素がNaNでない場合はメインラベルのデータとする else: label.append(df.iloc[i][0]) # メインラベル layer1.append(df.iloc[i][1]) # 色を付ける部分 layer2.append(0) # メインデータはマスク0 discription.append(df.iloc[i][4]) # 備考(現在は機能していない) flag.append(0) # メインデータとわかるよう0を格納する axis = np.arange(0, len(df), 1)[::-1] # バープロット用縦軸を反転して作る # ここからグラフ描画------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure(figsize=(8, 6)) ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('純利益[億円]') # スケールの設定をする。 ax1.set_xlim(4500, 6000) # データプロットする。 # フラグ毎に色付けとマスクの関係を分けている。 for i in range(len(df)): # メインデータの場合 if flag[i] == 0: ax1.barh(axis[i], layer1[i], height=0.9, color='lime') ax1.text(np.max(layer1) - (np.max(layer1) / 5), axis[i], str(int(layer1[i])), verticalalignment='center', fontsize=16) # 増加データの場合 elif flag[i] == 1: ax1.barh(axis[i], layer1[i], height=0.9, color='orange') ax1.barh(axis[i], layer2[i], height=0.9, color='white') ax1.text(layer1[i], axis[i], '+' + str(int(layer1[i] - layer2[i])), verticalalignment='center', fontsize=14, color='red') ax1.text(layer1[i] - 20, axis[i], discription[i], horizontalalignment='right', verticalalignment='center', fontsize=14, color='red') # 減少データの場合 else: ax1.barh(axis[i], layer2[i], height=0.9, color='cyan') ax1.barh(axis[i], layer1[i], height=0.9, color='white') ax1.text(layer2[i], axis[i], '▲' + str(int(layer2[i] - layer1[i])), verticalalignment='center', fontsize=14, color='blue') ax1.text(layer2[i] - 20, axis[i], discription[i], horizontalalignment='right', verticalalignment='center', fontsize=14, color='blue') plt.yticks(ticks=axis, labels=label) # レイアウト設定 fig.tight_layout() # グラフを表示する。 plt.show() plt.close() # --------------------------------------------------- # ウォーターフォール図を描く関数を実行 plot_waterfall_chart('waterfall-sample.csv') |
実行結果
以下が実行結果です。横向きになりました!
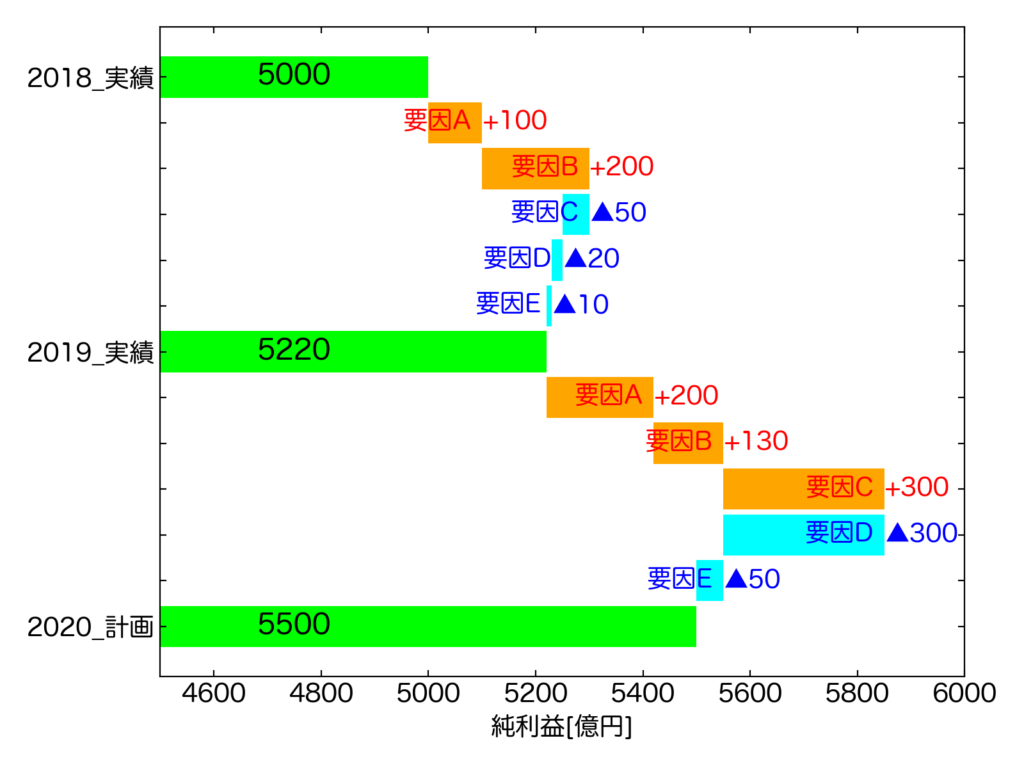
まとめ
本記事はウォーターフォール図の簡単な紹介と、Pythonによる自作コードでプロットを検討した結果を紹介しました。
結果、縦向きと横向きの両方でウォーターフォール図を描く事ができました。
…これは今後の社会人生活で役立つ武器が一つ手に入ったのでは?
実益の大きそうなコードが書けました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!