
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

機械学習に強いPythonとはいえ、ゼロから精度の良い物体検出アプリをつくるのは骨が折れるでしょう。しかしultralyticsというライブラリを使えば数行のコードでキーとなる検出部分を書くことができます。ここではultralyticsを用いたYOLOv8の説明を行います。
こんにちは。wat(@watlablog)です。今回は機械学習モデルを使ってYOLOによる物体検出を行ってみます!
※今回は「ただ使ってみた」程度の記事です。他にも書きたいことがありますが、ボリュームが大きくなってしまうので別記事にします。まずは使ってみたい!という人向けの記事です。
YOLOの概要とultralyticsについて
YOLOとは?
YOLO(You Only Look Once)は、リアルタイム物体検出用の深層学習アルゴリズムの一つです。従来の物体検出手法は、画像内の複数の領域を個別に評価して物体を検出するのに対して、YOLOは画像を一度だけ処理することで、物体の位置とクラスを同時に検出します。そのため、高速でありながら高い精度を達成することが特徴です。
従来の画像処理技術の問題点と進化の変遷
従来の画像処理技術の一例として、WATLABブログでは1枚の画像に対し、四角いフレームを移動させながら抽出するコードを紹介しました(以下の記事)。
・Python/OpenCVで画像内の領域を縦横に走査する方法
・Python/OpenCVでPIV計測!粒子移動をベクトル化する

しかし、これらの処理は1枚の画像だけで何回も画像切り出しと解析を行う必要があり、forループを使わざるを得ないことから非常に処理が遅い欠点を持っていました。
それが2012年のILSVRCあたりからディープラーニングの絶大な効果が認知され、CNNを使った物体検出技術(R-CNN)\(^{[1]}\)で精度UPがされましたが、この方法でも処理速度はまだ遅いです。
しかし最初のYOLOの論文\(^{[2]}\)では画像をグリッドに分割し、各セルで物体のクラスとバウンディングボックス(物体の領域)を検出し、最終的には統計的に最も確率の高いボックスを検出結果とする内容が提案されました。
この辺りの歴史は以下の外部サイト様のページが非常によくまとまっていました。
・Deep Learningによる一般物体検出アルゴリズムの紹介
ultralyticsについて
今回紹介するultralyticsは、Pythonベースの深層学習リサーチプラットフォームで、特にYOLOを中心とした物体検出のタスクに強いことで知られています。
ultralyticsは過去にYOLOv3、YOLOv5とバージョンアップを重ねた物体検出プロダクトをリリースしており、今回2023年現在はYOLOv8が最新版です。説明は以下の公式ページを参照するとして、早速コードを書きながらどんなことができるのか確認していきましょう!
・ultralytics YOLOv8 docs:https://docs.ultralytics.com/
・ultralytics PyPI:https://pypi.org/project/ultralytics/
動作環境
このページのコードは以下の開発環境で動作を確認しました。pip install ultralyticsをすると依存ライブラリが色々とインストールされるので心配な方は仮想環境下で作業することをオススメします。
| Windows | OS | Windows10 64bit |
|---|---|---|
| CPU | Intel 11th Core i7-11800H:2.3[GHz] | |
| メモリ | 16[GB] |
| Mac | OS | macOS Ventura 13.2.1 |
|---|---|---|
| CPU | 1.4[GHz] | |
| メモリ | 8[GB] |
| Python | Python 3.9.6&3.11.4 |
|---|---|
| PyCharm (IDE) | PyCharm CE 2020.1 |
| opencv-python | 4.2.0.76 |
| ultralytics | 8.0.154 |
画像から物体検出をするコード
サンプル画像
ultralyticsをインストールした時にassetフォルダも一緒に作られますが、そこに2枚の画像が入っていました。今回はこの画像をテストデータとしてコードで使ってみましょう。フォルダがどこにできるかはそれぞれです。ライブラリがどこにインストールされたかをprint(cv2.__path__)等で確認してみましょう。
全コード
以下にコピペ動作が可能な全コードを示します。画像のパスは適宜自分のものに変更してください。
公式ページに載っている内容とほぼ同じですが、個人的には関数に引数を渡して結果を処理してもらう方が好きなので、このような書き方をしてみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from ultralytics import YOLO import cv2 def object_detection(img, model): """ 画像とモデルを受け取って物体検出する関数 """ # 物体検出 results = model(img) # バウンディングボックスをオーバーレイ img_annotated = results[0].plot() # 物体検出結果画像を表示 cv2.imshow("Result", img_annotated) cv2.waitKey(0) cv2.destroyAllWindows() return if __name__ == '__main__': """ Main """ # サンプル画像(ultralyticsインストールフォルダのassetに入っている) # インポートしたパッケージのディレクトリはprint(cv2.__path__)等で確認可能。 img1 = '/usr/local/lib/python3.9/site-packages/ultralytics/assets/bus.jpg' img2 = '/usr/local/lib/python3.9/site-packages/ultralytics/assets/zidane.jpg' # モデルを設定 model = YOLO('yolov8n.pt') # 物体検出関数を実行 object_detection(img1, model) |
実行結果
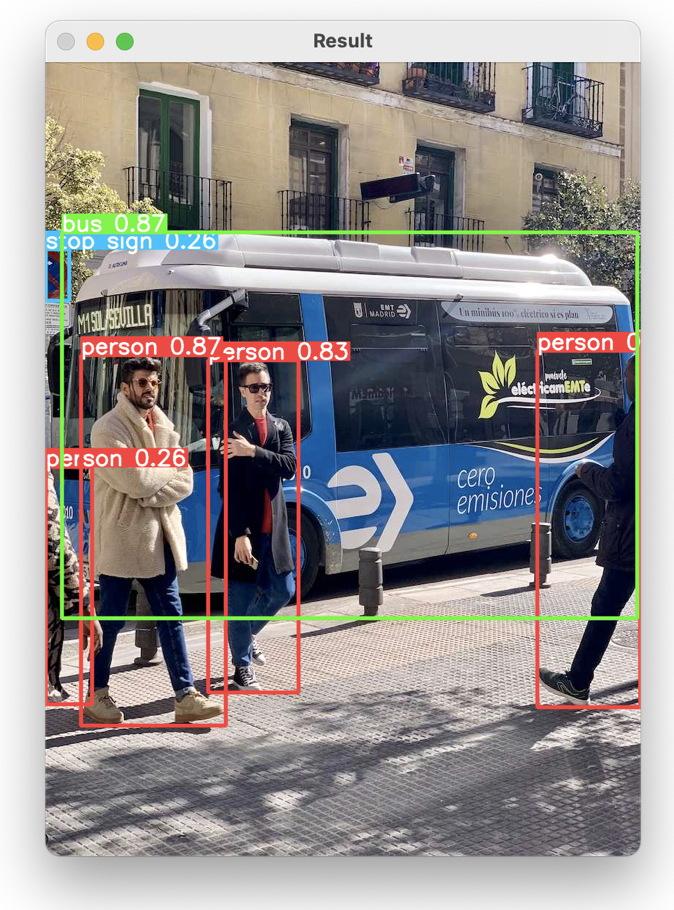
こちらが実行結果です。人間が4人(しかもフレームアウトしかけている人も!!)、バス、ストップサイン(?)と一度に複数の物体を検出できました。これは既にすごいのではないでしょうか?
2枚目のサンプル画像に対する結果はこちら。ネクタイも検出されていますね。

カメラからリアルタイム物体検出をするコード
全コード
上記コードをベースとして、カメラを使ったリアルタイムな物体検出コードを以下に示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
from ultralytics import YOLO import cv2 def object_detection_camera(model): """ カメラからリアルタイム物体検出する関数 """ # 動画撮影を開始 cap = cv2.VideoCapture(0) while cap.isOpened(): # フレームを抽出する success, frame = cap.read() if success: # 物体検出 results = model(frame) # バウンディングボックスをオーバーレイ img_annotated = results[0].plot() # 物体検出結果画像を表示 cv2.imshow("Movie", img_annotated) # qキーが押されたらウィンドウを閉じる if cv2.waitKey(1) & 0xFF == ord("q"): break else: break # リリース cap.release() cv2.destroyAllWindows() return if __name__ == '__main__': """ Main """ # モデルを設定 model = YOLO('yolov8n.pt') # 物体検出関数を実行 object_detection_camera(model) |
実行結果
videoAC(https://video-ac.com/)さんの動画素材をPCモニタに映してそれをWebカメラで撮影…ということをしてみました。リアルタイムに物体検出ができています。
動画から物体検出をするコード
全コード
動的なアルゴリズムの検証には動画ファイルを読み込んで処理だけをリアルタイムに行うコードも有用かも知れません。
そのため次は動画ファイルを使った物体検出方法について紹介してみます。
とは言ってもOpenCVを使ったカメラ撮影処理と動画ファイル処理は先ほどのコードとほぼ変わりがありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
from ultralytics import YOLO import cv2 def object_detection_camera(moviefile, model): """ 動画ファイルからリアルタイム物体検出する関数 """ # 動画撮影を開始 cap = cv2.VideoCapture(moviefile) while cap.isOpened(): # フレームを抽出する success, frame = cap.read() if success: # 物体検出 results = model(frame) # バウンディングボックスをオーバーレイ img_annotated = results[0].plot() # 物体検出結果画像を表示 cv2.imshow("Movie", img_annotated) # qキーが押されたらウィンドウを閉じる if cv2.waitKey(1) & 0xFF == ord("q"): break else: break # リリース cap.release() cv2.destroyAllWindows() return if __name__ == '__main__': """ Main """ moviefile = 'video.mp4' # モデルを設定 model = YOLO('yolov8n.pt') # 物体検出関数を実行 object_detection_camera(moviefile, model) |
実行結果
同じくvideoACさんの動画ファイルを読み込み物体検出をしてみました。移動するトラックや人が検出されています。ただし人は全て検出できていないようです。
特にモデルをyolov8n.ptからyolov8x.ptに変えても精度向上はしませんでした(n→s→m→l→xとなるにつれて機械学習モデルの規模が大きくなり、精度の向上が期待できる)。
まとめ
今回はただただ「YOLOv8を使ってみた!」という内容でまとめてみました。記事の初めに物体検出技術の歴史を少しおさらいしましたが、最近の技術進歩は1年単位で進みが確認できて驚いてばかりです。
この記事では使うことを重視し、①画像ファイル、②カメラ、③動画ファイルに対する物体検出コードを紹介しました。
検出結果から情報を取得するメソッドやJSON形式でテキストにできたりも可能なようで、今後深掘りしていきたいと思います。ゆくゆくはファインチューニングも扱って実際の課題に使えるレベルにできればと思いますが、それは少し時間がかかると思います。
簡単に使うシリーズとしてトラッキングや姿勢推定もできるそうですが、記事としてまとめられそうであればちょっと書いてみたいですね。
YOLOはYou Only Live Once(人生一度きり)をモジってLookに変更したとの説があるそうです。Attention Is All You Needという有名な論文もあったと思いますが、機械学習界隈の科学者はユーモアがありますね!
参考文献
まずは簡単なコードで物体検出ができることを確認しました!
Twitter(今はXと呼ぶ?)でも関連情報をつぶやいているので、wat(@watlablog)のフォローをYOLOしくお願いします!