
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

画像への文字入れを自動化する事で動画への字幕入れができるようになりますが、標準の文字入れだと目立ちません。ここではテレビの字幕のような装飾された文字の入れ方をPythonで色々検討してみます。
こんにちは。wat(@watlablog)です。Pythonなら文字の装飾も簡単です!ここではテレビのような装飾文字(縁取り/影付き/透過/ぼかし)の実現をPythonで目指します!
この記事の対象者
Pythonによる単純な文字入れに不満のある人
この記事は動画や画像に対して文字を入れたい人を対象としていますが、
単色の文字入れは簡単なんだけど、イマイチ目立たないな〜。
という、現状の文字入れに満足できていない方を特に対象としています。
当WATLABブログでは「Pythonで画像に日本語文字を入れる方法」という記事でOpenCVやPIL(Pillow)による画像への文字入れを学びました。
しかし、画像に描画された文字は単色であるため、カラー画像に対して文字入れをすると下図のようにあまり目立たない結果となってしまいます。

本記事ではこのような文字を目立たせるため、縁取り文字の入れ方の基礎を紹介します。
縁取り文字の例を以下に示します。輪郭をくっきりさせる事で背景に色があっても読みやすくなりました。

この記事ではここがスタート地点です。この縁取りをPythonで実現した後に、色々な表現方法を検討していきます。
これらの処理はPythonでしかできないのかというとそんな事はなく、文字入れくらいだったらフリーソフトは沢山あるようです。ただ、プログラム的に文字入れをすると自動化ができるという事がメリットなので、ここでは初心者でも簡単に扱えるPythonを使います。
Pythonでテレビ字幕のような文字装飾をしたい人
縁取り文字入れの方法を学んだ後は、文字装飾を検討します。
影付き文字やぼかしといった装飾をつける事で、動画の視聴者に効果的に内容を伝える事ができます。
僕は普段あまりテレビは見ないのですが、装飾文字分野においては長年の歴史を持つテレビ業界の成果物(番組)は格好の教材だと思います。
ここでは著作権の観点からサンプル画像は載せませんが、是非Googleで「テレビ 字幕 例」とかで検索してみて下さい。
ここではテレビ字幕のような効果をつける事ができないかどうか、Pythonで検討した結果をメモ的に残していきます。
単純文字入れのPythonコード(復習)
まず初めに「Pythonで画像に日本語文字を入れる方法」で紹介しているコードを使って、今回のサンプル画像生成と単純文字入れを行ってみます。
以下のコードをコピペして動かす事でテストパターンで作った背景画像上に'Hello World!'の文字が描画されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import cv2 from PIL import Image, ImageFont, ImageDraw import numpy as np # 画像に文字を入れる関数 def telop(img, message, W, H, font_color, edge_color, stroke_width): #font_path = 'C:\Windows\Fonts\meiryo.ttc' # Windowsのフォントファイルへのパス font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc'# Macのフォントファイルへのパス font_size = 80 # フォントサイズ font = ImageFont.truetype(font_path, font_size) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw = ImageDraw.Draw(img) # 描画用のDraw関数を用意 w, h = draw.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 # テロップの位置positionは画像サイズと文字サイズから決定する position = (int((W - w) / 2), int(H - (font_size * 1.5))) # テキストを描画(位置、文章、フォント、文字色(BGR+α)を指定) #draw.text(position, message, font=font, fill=(255, 255, 255, 255)) draw.multiline_text(position, message, font=font, fill=font_color, stroke_width=stroke_width, stroke_fill=edge_color) # 画像を表示 img.show() # PIL型の画像をcv2(NumPy)型に変換 img = np.array(img) return img # サンプルの背景画像を生成 w = 600 h = 400 img = np.full((h, w, 3), 100, dtype=np.uint8) bgd = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (200, 200, 200)] for i in range(len(bgd)): cv2.rectangle(img, (i * int(w / len(bgd)), 0), ((i + 1) * int(w / len(bgd)), h), bgd[i], thickness=-1) # メッセージ設定 message = 'Hello World!' font_color = (255, 255, 255, 255) edge_color = (0, 0, 0, 255) stroke_width = 2 # 画像に文字を入れる関数を実行 telop(img, message, w, h, font_color, edge_color, stroke_width) |

縁取り文字を入れるPythonコード
multiline_textを使う方法
僕は最初いきなり下で紹介する自作縁取りコードの作成から入ってしまいましたが、単純に縁取りをしたいだけであれば「multiline_text」というメソッドを使うのが最も効率的と思います。
上記基本のコードのdraw.textの代わりに書き、stroke_widthで縁の太さ、stroke_fillで縁の色を指定する事が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import cv2 from PIL import Image, ImageFont, ImageDraw import numpy as np # 画像に文字を入れる関数 def telop(img, message, W, H): #font_path = 'C:\Windows\Fonts\meiryo.ttc' # Windowsのフォントファイルへのパス font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc'# Macのフォントファイルへのパス font_size = 80 # フォントサイズ font = ImageFont.truetype(font_path, font_size) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw = ImageDraw.Draw(img) # 描画用のDraw関数を用意 w, h = draw.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 # テロップの位置positionは画像サイズと文字サイズから決定する position = (int((W - w) / 2), int(H - (font_size * 1.5))) # テキストを描画(位置、文章、フォント、文字色(BGR+α)を指定) #draw.text(position, message, font=font, fill=(255, 255, 255, 255)) draw.multiline_text(position, message, font=font, fill=(255, 255, 255, 255), stroke_width=2, stroke_fill=(0, 0, 0, 255)) # 画像を表示 img.show() # PIL型の画像をcv2(NumPy)型に変換 img = np.array(img) return img # サンプルの背景画像を生成 w = 600 h = 400 img = np.full((h, w, 3), 100, dtype=np.uint8) bgd = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (200, 200, 200)] for i in range(len(bgd)): cv2.rectangle(img, (i * int(w / len(bgd)), 0), ((i + 1) * int(w / len(bgd)), h), bgd[i], thickness=-1) message = 'Hello World!' telop(img, message, w, h) |

このメソッドであれば簡単に文字色や縁色、縁太さを変更可能です。
例えばdraw.multiline_textで文字色に白以外を選択し、縁色を白にするコードはこちら。
|
1 2 3 |
# テキストを描画(位置、文章、フォント、文字色(BGR+α)を指定) draw.multiline_text(position, message, font=font, fill=(0, 255, 128, 255), stroke_width=10, stroke_fill=(255, 255, 255, 255)) |
下図が結果です。簡単に見映えが変わるので重宝できそうです。

モルフォロジー変換を使う方法(詳細操作目的)
続いて、より細かい操作を必要とする場合の縁取り方法として、モルフォロジー変換を用いた方法を紹介します。
モルフォロジー変換とは、画像の興味オブジェクトを膨張させたり収縮させたりする画像処理技術です。
AI実装検定S級の勉強をした時にやりましたが、興味のある方は「AI実装検定S級対策!「画像処理100本ノック」学習記録・カンペ」のQ47か、本家「画像処理100本ノック」の関連ページ、OpenCVの実装は「チュートリアル:モルフォロジー変換」をご覧下さい。
本方法の方針としては、まず真にテキスト描画したい画像ではなく、別途テキスト描画用の背景画像を用意して、その背景画像に文字入れをした後にモルフォロジー変換の「膨張」操作を行なって縁取りをします。
少々手順を踏みますので、以下に手順毎にまとめます。
①ダミーでDrawを作ってフォントのサイズを測定する
背景画像のサイズをフォントサイズ基準で決定するために、一度フォントのサイズを測定します。しかし、フォントサイズは一度drawインスタンスを作ってからでないと測定できないので、以下のようにダミーdrawにて計測します。
|
1 2 3 |
img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw_dummy = ImageDraw.Draw(img) # 描画用のDraw関数をダミーで用意(テキストサイズ計測用) w, h = draw_dummy.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 |
②黒色背景画像に白色文字入れする
次に黒一色で背景画像を生成し、テキストを白一色で描画します(下図)。

img_bgdが背景画像で、ここで本命のdrawを作ります。
|
1 2 3 4 5 6 |
# テキストのサイズで黒一色背景画像を作成(PIL形式)してDrawを用意 img_bgd = Image.fromarray(np.full((h, w, 3), 0, dtype=np.uint8)) draw = ImageDraw.Draw(img_bgd) # 背景画像にテキストを白色で描画 draw.text((0, 0), message, font=font, fill=(255, 255, 255, 255)) |
③背景画像にゼロパディングする
このテキストをモルフォロジー変換で膨張させるわけですが、テキストサイズにぴったりな背景画像なので、膨張させた文字が枠外に出てしまいます。そのため、膨張させる前に背景画像そのものをゼロパディングにて拡げます。
ゼロパディングとは、画像の周りに輝度値0の帯(ボーダー)を追加する事を言います(画像処理以外でも機械学習や信号処理で使われています)。
以下の画像がゼロパディング後の結果です。文字の周りに余裕が出ました。
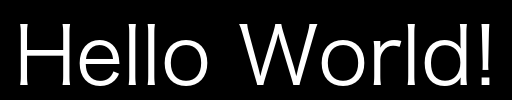
コードはこちら。cv2.copyMakeBorderにcv2.BORDER_CONSTANTを指定して行います(OpenCVを使うためソース画像はNumpy配列に戻しています)。パディングの量は背景画像の高さ基準にしました。
|
1 2 3 |
# 画像高さの20%でゼロパディング pad = int(h * 0.2) img_bgd = cv2.copyMakeBorder(np.array(img_bgd), pad, pad, pad, pad, cv2.BORDER_CONSTANT, 0) |
④Dilationでテキストを膨張させる
このタイミングでモルフォロジー変換の一種である膨張(Dilation)を行います。この処理を行う事によってテキストが一回り大きくなります。この大きくなった部分を縁として使うわけです。

dilation_iを大きくするほど膨張します。
|
1 2 3 |
# モルフォロジー変換でテキスト膨張 kernel = np.ones((5, 5), np.uint8) img_bgd = cv2.dilate(img_bgd, kernel, iterations=dilation_i) |
⑤マスク画像を作る
膨張させた文字の部分のみを元画像に貼り付けたいので、マスク画像を作ります。以下のマスク画像(残したい部分が黒)を作らないと元画像に貼り付けた時にそのまま背景画像の四角形が残ってしまいます。
マスク画像の概要や作り方は「Python/OpenCVで任意色を透過させたpng画像に変換」という記事にまとめましたので、是非ご覧下さい。
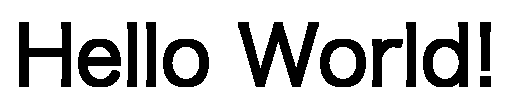
コードはこちら。この時点で画像の各ピクセルを透明化する事が出来るアルファチャンネルを追加しておきます。
|
1 2 3 4 5 6 7 8 9 |
# 背景画像へアルファチャンネルの追加 alpha = np.full((img_bgd.shape[0], img_bgd.shape[1]), 255, dtype=img_bgd.dtype) b, g, r = cv2.split(img_bgd) img_bgd = cv2.merge((b, g, r, alpha)) # マスクの作成(抽出する色) color_lower = np.array([255, 255, 255, 255]) color_upper = np.array([255, 255, 255, 255]) mask = cv2.inRange(img_bgd, color_lower, color_upper) |
⑥縁の色を変更する
テキストを膨張させているので、縁となるピクセル表現までは出来ていますが、このままでは縁は常に白色になってしまいます。
冒頭で紹介した縁取り文字のように黒やその他任意色に変更するためには、ここまでの背景画像で白色の部分だけを別の色にしてあげる必要があります(下図は例。黒だと真っ黒画像になるので赤にしています)。

特定色を任意色に変更するのは、先ほど紹介した任意色を透過させる方法の記事に記載のものとほぼ同じコードで実現可能です。
|
1 2 |
# 縁色を変更する img_bgd[np.where((img_bgd == (255, 255, 255, 255)).all(axis=2))] = edge_color |
⑦再度テキストを描画して縁取り文字とする
ここまで行なった画像に対して、もう一度テキストを描画します。こうすることで膨張したテキストとそうでないテキストが組み合わさって縁取り文字となります。

既にゼロパディングしてある画像なので、テキスト描画の開始位置を(pad, pad)にするのを忘れずに。
⑥の段階のedge_colorとこちらのfont_colorを任意色とする事であらゆる色組み合わせの縁取り文字を作る事が出来ます。
|
1 2 3 4 |
# 再度背景画像にテキスト描画 img_bgd = Image.fromarray(img_bgd) draw = ImageDraw.Draw(img_bgd) draw.text((pad, pad), message, font=font, fill=font_color) |
⑧ブーリアン演算で文字部分のみ抽出
文字部分のみを元画像に貼り付けたいので、先ほど⑤で作成したマスク画像を使ってブーリアン演算(論理演算)を行います。こうする事で、文字以外の部分は透明になります(アルファチャンネルを追加したのはこのため)。

コードはやはり任意色を透過させる方法の記事で使ったものです。ここではandまたはorが目的の操作に合致しました。
|
1 2 3 |
# マスク部分で論理演算 img_bgd = np.array(img_bgd) bool = cv2.bitwise_and(img_bgd, img_bgd, mask=mask) # 元画像とマスク画像のブーリアン演算 |
⑨元画像へ縁取り文字の貼り付け
最後は元画像に作成した縁取り文字を貼り付けます。アルファチャンネルの割合に応じて演算をした結果を元画像に足すだけですが、以下のQiita記事がそのまま答えになったので参考としてリンクを紹介します。
Qiita:「アルファチャンネルつき png を透過画像で貼り付ける with Python/OpenCV」

コードはこちら。貼り付ける位置は背景画像の高さサイズ×1.5としていますが、この部分を修正する事で任意位置に変更する事が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 文字位置は画像の下段幅中心 w_bgd = img_bgd.shape[1] h_bgd = img_bgd.shape[0] x1 = int((W - w_bgd) / 2) y1 = int(H - (h_bgd * 1.5)) x2 = x1 + w_bgd y2 = y1 + h_bgd # 元画像へ作成した文字を重ね書き(アルファチャンネル演算) img = np.array(img) img[y1:y2, x1:x2, :3] = img[y1:y2, x1:x2] * (1 - bool[:, :, 3:] / 255) + \ bool[:, :, :3] * (bool[:, :, 3:] / 255) |
コピペ用全コード
全部でかなりの工程がありましたが、ここまでが自作した縁取り文字作成コードの主要部分です。以下に全コードをMITライセンス(再利用して良いという意味)で載せます。是非コピペして使ってみて下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
import cv2 from PIL import Image, ImageFont, ImageDraw import numpy as np import os # 画像に文字を入れる関数 def telop(img, message, W, H, font_color, edge_color, dilation_i): #font_path = 'C:\Windows\Fonts\meiryo.ttc' # Windowsのフォントファイルへのパス font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc'# Macのフォントファイルへのパス font_size = 80 # フォントサイズ font = ImageFont.truetype(font_path, font_size) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw_dummy = ImageDraw.Draw(img) # 描画用のDraw関数をダミーで用意(テキストサイズ計測用) w, h = draw_dummy.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 # テキストのサイズで黒一色背景画像を作成(PIL形式)してDrawを用意 img_bgd = Image.fromarray(np.full((h, w, 3), 0, dtype=np.uint8)) draw = ImageDraw.Draw(img_bgd) # 背景画像にテキストを白色で描画 draw.text((0,0), message, font=font, fill=(255, 255, 255, 255)) # 画像高さの20%でゼロパディング pad = int(h * 0.2) img_bgd = cv2.copyMakeBorder(np.array(img_bgd), pad, pad, pad, pad, cv2.BORDER_CONSTANT, 0) # モルフォロジー変換でテキスト膨張 kernel = np.ones((5, 5), np.uint8) img_bgd = cv2.dilate(img_bgd, kernel, iterations=dilation_i) # 背景画像へアルファチャンネルの追加 alpha = np.full((img_bgd.shape[0], img_bgd.shape[1]), 255, dtype=img_bgd.dtype) b, g, r = cv2.split(img_bgd) img_bgd = cv2.merge((b, g, r, alpha)) # マスクの作成(抽出する色) color_lower = np.array([255, 255, 255, 255]) color_upper = np.array([255, 255, 255, 255]) mask = cv2.inRange(img_bgd, color_lower, color_upper) # 縁色を変更する img_bgd[np.where((img_bgd[:, :, :3] == (255, 255, 255)).all(axis=2))] = edge_color # 再度背景画像にテキスト描画 img_bgd = Image.fromarray(img_bgd) draw = ImageDraw.Draw(img_bgd) draw.text((pad, pad), message, font=font, fill=font_color) # マスク部分で論理演算 img_bgd = np.array(img_bgd) bool = cv2.bitwise_and(img_bgd, img_bgd, mask=mask) # 元画像とマスク画像のブーリアン演算 Image.fromarray(bool).save('sample-telop_bool.png') # 文字位置は画像の下段幅中心 w_bgd = img_bgd.shape[1] h_bgd = img_bgd.shape[0] x1 = int((W - w_bgd) / 2) y1 = int(H - (h_bgd * 1.5)) x2 = x1 + w_bgd y2 = y1 + h_bgd # 元画像へ作成した文字を重ね書き(アルファチャンネル演算) img = np.array(img) img[y1:y2, x1:x2, :3] = img[y1:y2, x1:x2] * (1 - bool[:, :, 3:] / 255) + \ bool[:, :, :3] * (bool[:, :, 3:] / 255) Image.fromarray(img).show() #Image.fromarray(img).save('sample-telop_with_bool.png') # 保存したい時はここを有効にする # PIL型の画像をcv2(NumPy)型に変換 img = np.array(img) return img # 指定サイズと色で背景画像を生成 w = 600 h = 400 img = np.full((h, w, 3), 100, dtype=np.uint8) bgd = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (200, 200, 200)] for i in range(len(bgd)): cv2.rectangle(img, (i * int(w / len(bgd)), 0), ((i + 1) * int(w / len(bgd)), h), bgd[i], thickness=-1) # メッセージ設定 message = 'Hello World!' font_color = (255, 255, 255, 255) edge_color = (255, 0, 0, 255) dilation_i = 1 # 画像に文字を入れる関数を実行 telop(img, message, w, h, font_color, edge_color, dilation_i) |
font_color, edge_color, dilation_iを変更すると色々な縁取り文字が作成出来ます。
以下がPILライブラリのmultiline_text(stroke_width=2)と、モルフォロジー変換を使って自作したコードで作成した同一縁取り文字の比較画像です。ややライブラリを使った方が綺麗でしょうか。
単純文字入れだけならライブラリを使った方が良いと思いますが、この後紹介する細かい処理をするのであれば間に特殊処理を追加できる自作コードの方が良いでしょう。目的に応じて使い分けが必要です。

影付き文字を入れるPythonコード
文字効果として次に影付き文字を作ってみます。
影付き文字の例を下画像に示します。縁取りの太さも含めて影を付けています。もちろん影の色も変更する事が可能です。

影付き文字を描画するPythonコードを以下に示します。関数の引数にshadowとして基準座標からのずらし量、shadow_colorとして影の色を設定できるようにしてあります。
shadowが(0, 0)でない時、本来描画する文字の前に影を描画しておくというだけなので、全てmultiline_textで実現させています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import cv2 from PIL import Image, ImageFont, ImageDraw import numpy as np # 画像に文字を入れる関数 def telop(img, message, W, H, font_color, edge_color, stroke_width, shadow, shadow_color): #font_path = 'C:\Windows\Fonts\meiryo.ttc' # Windowsのフォントファイルへのパス font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc'# Macのフォントファイルへのパス font_size = 80 # フォントサイズ font = ImageFont.truetype(font_path, font_size) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw = ImageDraw.Draw(img) # 描画用のDraw関数を用意 w, h = draw.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 # テロップの位置positionは画像サイズと文字サイズから決定する position = (int((W - w) / 2), int(H - (font_size * 1.5))) # テキストを描画:shadowに数値が入っていれば影効果を与える if shadow != (0, 0): shadow_position = (position[0] + shadow[0], position[1] + shadow[1]) draw.multiline_text(shadow_position, message, font=font, fill=shadow_color, stroke_width=stroke_width, stroke_fill=shadow_color) draw.multiline_text(position, message, font=font, fill=font_color, stroke_width=stroke_width, stroke_fill=edge_color) # 画像を表示 img.show() img.save('shadow_text.png') # PIL型の画像をcv2(NumPy)型に変換 img = np.array(img) return img # サンプルの背景画像を生成 w = 600 h = 400 img = np.full((h, w, 3), 100, dtype=np.uint8) bgd = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (200, 200, 200)] for i in range(len(bgd)): cv2.rectangle(img, (i * int(w / len(bgd)), 0), ((i + 1) * int(w / len(bgd)), h), bgd[i], thickness=-1) # メッセージ設定 message = 'Hello World!' font_color = (255, 255, 255, 255) edge_color = (0, 0, 0, 255) stroke_width = 2 shadow = (6, 6) shadow_color = (0, 0, 0, 255) # 画像に文字を入れる関数を実行 telop(img, message, w, h, font_color, edge_color, stroke_width, shadow, shadow_color) |
shadowの数値を以下の(a)-(d)のように変更する事で、投影する位置を制御する事も出来ます。

透過文字を入れるPythonコード
縁部分に背景画像を透過させるような処理をする場合を検討してみます。
multiline_textでは失敗する
まずはライブラリでできた方が良いので、事前に画像にアルファチャンネルを追加してから、multiline_textでアルファチャンネルの値を128といったように透過指定してみました。
しかし、以下のようにアルファチャンネルの数値は反映されていました(縁は黒ではなくグレーに変化)が、背景画像との演算まではやってくれていないようでした(他に方法あるかは未探索)。

自作コードで実現する
縁を透過する
モルフォロジー変換を使って作った自作コードであれば、アルファチャンネルの演算を行なっているので、背景画像の透かしも表現する事が出来ます。
例えばedge_colorのアルファチャンネル(4番目の値)を255以外にすれば、
|
1 2 3 4 5 |
# メッセージ設定 message = 'Hello World!' font_color = (255, 255, 255, 255) edge_color = (255, 255, 255, 128) dilation_i = 3 |
縁取り部分が透過されます。

内部文字を透過する
font_colorのアルファチャンネルの方を255以外にすれば、
|
1 2 3 4 5 |
# メッセージ設定 message = 'Hello World!' font_color = (255, 255, 255, 128) edge_color = (0, 0, 0, 255) dilation_i = 3 |
縁内部の文字が透過されます。色や縁の太さと組み合わせて使えば色々な効果を出せそうです。

縁をぼかす文字を入れるPythonコード
以下の(a)は黒文字に白縁取りをした場合ですが、(b)と縁部分をぼやかす処理を検討してみます。

下記コードのコメント「# blur==Trueであればぼかし処理を行う」直後のif文でガウシアンフィルタによるぼかし処理を行なっています。boolに対してフィルタ処理を行い、その後に正規のテキストを描画する事で、縁取り部分のみぼかす事が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
import cv2 from PIL import Image, ImageFont, ImageDraw import numpy as np # 画像に文字を入れる関数 def telop(img, message, W, H, font_color, edge_color, dilation_i, blur): #font_path = 'C:\Windows\Fonts\meiryo.ttc' # Windowsのフォントファイルへのパス font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc'# Macのフォントファイルへのパス font_size = 80 # フォントサイズ font = ImageFont.truetype(font_path, font_size) # PILでフォントを定義 img = Image.fromarray(img) # cv2(NumPy)型の画像をPIL型に変換 draw_dummy = ImageDraw.Draw(img) # 描画用のDraw関数をダミーで用意(テキストサイズ計測用) w, h = draw_dummy.textsize(message, font) # .textsizeで文字列のピクセルサイズを取得 # テキストのサイズで黒一色背景画像を作成(PIL形式)してDrawを用意 img_bgd = Image.fromarray(np.full((h, w, 3), 0, dtype=np.uint8)) draw = ImageDraw.Draw(img_bgd) # 背景画像にテキストを白色で描画 draw.text((0,0), message, font=font, fill=(255, 255, 255, 255)) # 画像高さの20%でゼロパディング pad = int(h * 0.2) img_bgd = cv2.copyMakeBorder(np.array(img_bgd), pad, pad, pad, pad, cv2.BORDER_CONSTANT, 0) # モルフォロジー変換でテキスト膨張 kernel = np.ones((5, 5), np.uint8) img_bgd = cv2.dilate(img_bgd, kernel, iterations=dilation_i) # 背景画像へアルファチャンネルの追加 alpha = np.full((img_bgd.shape[0], img_bgd.shape[1]), 255, dtype=img_bgd.dtype) b, g, r = cv2.split(img_bgd) img_bgd = cv2.merge((b, g, r, alpha)) # マスクの作成(抽出する色) color_lower = np.array([255, 255, 255, 255]) color_upper = np.array([255, 255, 255, 255]) mask = cv2.inRange(img_bgd, color_lower, color_upper) # 縁色を変更する img_bgd[np.where((img_bgd[:, :, :3] == (255, 255, 255)).all(axis=2))] = edge_color # マスク部分で論理演算 img_bgd = np.array(img_bgd) bool = cv2.bitwise_and(img_bgd, img_bgd, mask=mask) # 元画像とマスク画像のブーリアン演算 # 再度背景画像にテキスト描画 # blur==Trueであればぼかし処理を行う if blur == True: bool = cv2.GaussianBlur(bool, (33, 33), 0) bool = Image.fromarray(bool) draw = ImageDraw.Draw(bool) draw.text((pad, pad), message, font=font, fill=font_color) bool = np.array(bool) # 文字位置は画像の下段幅中心 w_bgd = img_bgd.shape[1] h_bgd = img_bgd.shape[0] x1 = int((W - w_bgd) / 2) y1 = int(H - (h_bgd * 1.5)) x2 = x1 + w_bgd y2 = y1 + h_bgd # 元画像へ作成した文字を重ね書き(アルファチャンネル演算) img = np.array(img) img[y1:y2, x1:x2, :3] = img[y1:y2, x1:x2] * (1 - bool[:, :, 3:] / 255) + \ bool[:, :, :3] * (bool[:, :, 3:] / 255) Image.fromarray(img).show() #Image.fromarray(img).save('sample-telop_with_bool.png') # 保存したい時はここを有効にする # PIL型の画像をcv2(NumPy)型に変換 img = np.array(img) return img # 指定サイズと色で背景画像を生成 w = 600 h = 400 img = np.full((h, w, 3), 100, dtype=np.uint8) bgd = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (200, 200, 200)] for i in range(len(bgd)): cv2.rectangle(img, (i * int(w / len(bgd)), 0), ((i + 1) * int(w / len(bgd)), h), bgd[i], thickness=-1) # メッセージ設定 message = 'Hello World!' font_color = (0, 0, 0, 255) edge_color = (255, 255, 255, 255) dilation_i = 3 blur = True # 画像に文字を入れる関数を実行 telop(img, message, w, h, font_color, edge_color, dilation_i, blur) |
但し、上記コードの結果は色付きの背景画像上で行うと、縁部分が黒っぽくなっています。この部分を改善しようと試みましたが、現時点でNo ideaでした…。今回はプログラミングで挑戦してみましたが、この辺を綺麗にしようと思ったら素直にフォトショとかイラレが良いのかも。
下図のように、黒背景であれば文字が光っている演出は可能です(これがやりたかった)。

もちろん日本語も大丈夫です(OpenCVだと日本語非対応であるので、PILを使っています)。但し、テキストの全体サイズが貼り付け先画像をはみ出すようだと別のエラーが出ます。このページでは折り返し等はまだ考えていないので別課題。
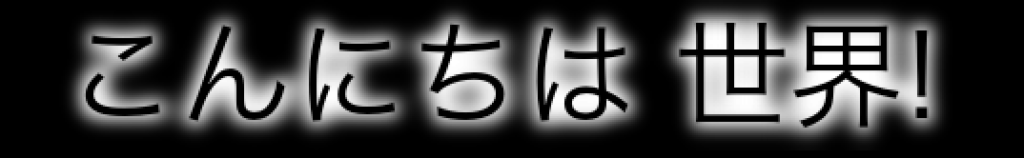
ぼかし境界が黒くならない良いアイデアはないものか?今は今後の課題という事にしておきます…。
(あったら教えて下さい!)
まとめ
Pythonで単純に画像への文字入れをしただけだと、非常に素人っぽい字幕しか作れない事に不満を持った人のために(自分)、本記事ではいくつかの文字装飾方法を検討してみました。
今回は縁取り文字、影付き文字、透過文字、ぼかし文字…と3つの装飾を検討してみました。
おそらく色、サイズ、太さやぼかし具合等を組み合わせればテレビ番組のような字幕を自動で入れる事も可能になってくると思います。
ぼかしがあまり綺麗でないといった問題もあり、今後綺麗にする所は課題として残してしまいましたが、本記事が少しでも皆様の文字入れライフのヒントになっていると良いなと思います。
文字入れについて少し検討をしてみました!次は動画への文字入れ自動化コードのアップデートを行います!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!