
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

機械学習は万能な方法ではなく、ハイパーパラメータの調整が不可欠です。ここでは最も理解しやすい決定木分析を使ってグリッドサーチというハイパーパラメータ調整方法を習得することを目標とします。
こんにちは。wat(@watlablog)です。
ここではグリッドサーチを用いたハイパーパラメータの調整を学びます!
グリッドサーチの概要
グリッドサーチとは?
グリッドサーチ(Grid Search)とは、機械学習においてモデルの精度を向上させるための手法のことで、設定した全てのハイパーパラメータの組み合わせを試し、その中で最も良いスコアを得たモデルを探す方法です。
ハイパーパラメータ(Hyper parameter)とは、エンジニアが事前に値を調整しておく必要のある機械学習モデルの変数のことです。
下図は2つのハイパーパラメータのグリッドサーチからスコアの高低を評価した例です。このようにハイパーパラメータの値が取り得る範囲を網羅的に見ることで、各パラメータをどのように設定すれば良いかを知ることが出来ます。
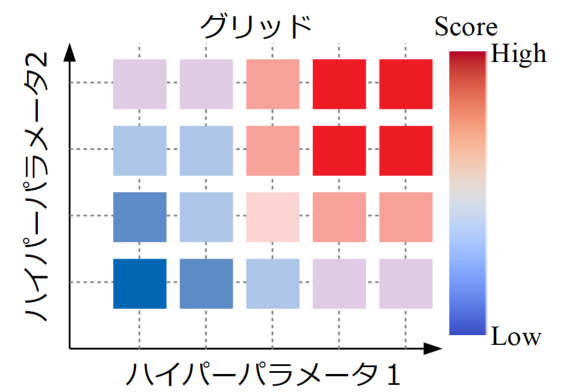
今回は理解が簡単である決定木による分類問題を例にハイパーパラメータの調整をしてみます。
決定木分析についての詳細は「Python/sklearnで決定木分析!分類木の考え方とコード」に記載しましたので、必要であればこの記事を読み進める前に確認してみて下さい。
グリッドサーチは簡単なようで面倒
グリッドサーチは設定した全てのパラメータの組み合わせを総当たりで検証します。
for文を使えば簡単に自力でも組めそうな気がしますが、ハイパーパラメータには数値型だけではなく文字列型を含んだり、データは交差検証(クロスバリデーション)でモデルにかけたかったり…以外とやることが煩雑です。
自力で作った方が色々できるというメリットが無い限りは、既に世の中で使われているライブラリを使う方が良さそうです。
今回はscikit-learnに付属しているGridSearchCVを使って簡単にグリッドサーチを計算してみます。
GridSearchCVでグリッドサーチするサンプルコード
グリッドサーチするサンプルの全コード
以下に今回の決定木分析におけるグリッドサーチのサンプルコードを紹介します。GridSearchCVとともに、train_test_splitもimportしています。
データはscikit-learnの分析ではお馴染みのiris(アヤメの分類)データセットで、事前にtrain_test_splitで訓練データとテストデータを分割しています。
データの分割については「Pythonで簡単にホールドアウト法用のデータ分割をする方法」で紹介していますので、是非ご覧下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from sklearn import datasets from sklearn.model_selection import GridSearchCV, train_test_split from sklearn import tree import pandas as pd # データを用意する iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む X = pd.DataFrame(iris.data[:, [0, 1, 2, 3]]) # 訓練データ Y = pd.Series(iris.target) # 教師データ train_X, test_X, train_Y, test_Y = train_test_split(X, Y, # 訓練データとテストデータに分割する test_size=0.3, # テストデータの割合 shuffle=True, # シャッフルする random_state=0) # 乱数シードを固定する # グリッドサーチ用のパラメータを辞書型で設定 param = {'max_depth':[1, 2, 3, 4, 5], 'min_samples_leaf':[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'min_samples_split':[2, 3, 4, 5]} # 決定木による学習 clf = GridSearchCV(tree.DecisionTreeClassifier(), # グリッドサーチで決定木を定義 param, cv=5, iid=True) clf.fit(train_X, train_Y) # フィッティング # スコアとパラメータの組み合わせ scores = clf.cv_results_['mean_test_score'] params = clf.cv_results_['params'] # 結果の確認 best_clf = clf.best_estimator_ print('最良条件:\n', best_clf) print('訓練スコア:\n', best_clf.score(train_X, train_Y)) print('テストスコア:\n', best_clf.score(test_X, test_Y)) for i in range(len(scores)): print(scores[i], params[i]) |
補足説明
個々の説明はコード内のコメントにも書いていますが、以下に補足説明します。
辞書型でパラメータの選定
まず始めにこのGridSearchCVを使う上でキーポイントであるパラメータの設定を説明します。
機械学習手法によって様々に異なるハイパーパラメータがありますが、GridSearchCVではPythonの辞書型でパラメータセットを作成します。
以下のコードは決定木分析に使用するパラメータでパラメータセットを作成した例です。{'パラメータ名':[値のリスト],… }と設定していきます。
|
1 2 3 4 |
# グリッドサーチ用のパラメータを辞書型で設定 param = {'max_depth':[1, 2, 3, 4, 5], 'min_samples_leaf':[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'min_samples_split':[2, 3, 4, 5]} |
ここでは3つのハイパーパラメータを設定しています。
GridSearchCVでモデルを定義する
そして以下のコードがグリッドサーチをする部分です。
まず始めにGridSearchCVでモデルを定義していますが、ここでは引数にcv=5と交差検証の設定も追加しています。こんなに簡単に交差検証ができるのは正直すごいと思います!
後はいつも通りfitさせるだけです。
|
1 2 3 4 |
# 決定木による学習 clf = GridSearchCV(tree.DecisionTreeClassifier(), # グリッドサーチで決定木を定義 param, cv=5, iid=True) clf.fit(train_X, train_Y) # フィッティング |
いつものモデル定義部分をGridSearachCVが包み込んだ形になっていますね。
実行結果
以下がコードの実行結果です。
.cv.results_でスコアやパラメータセットを抽出することができます。
また、.best_estimator_と最良のモデルを読み込むことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
最良条件: DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=4, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=2, min_samples_split=5, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best') 訓練スコア: 0.9809523809523809 テストスコア: 0.9777777777777777 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 1, 'min_samples_split': 2} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 1, 'min_samples_split': 3} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 1, 'min_samples_split': 4} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 1, 'min_samples_split': 5} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 2, 'min_samples_split': 2} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 2, 'min_samples_split': 3} 0.6952380952380952 {'max_depth': 1, 'min_samples_leaf': 2, 'min_samples_split': 4} …中略… 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 9, 'min_samples_split': 3} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 9, 'min_samples_split': 4} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 9, 'min_samples_split': 5} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 10, 'min_samples_split': 2} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 10, 'min_samples_split': 3} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 10, 'min_samples_split': 4} 0.9333333333333333 {'max_depth': 5, 'min_samples_leaf': 10, 'min_samples_split': 5} |
今回は訓練データの後にテストデータでスコアを確認していますが、訓練データが98.1%に対し、テストデータは97.8%と近い数値を出しました(98%くらいで正解する分類器になったという意味)。
決定木なので当たり前といっちゃ当たり前なのですが、max_depth(条件分岐の深さ)が精度に強く影響していることが、スコアとパラメータセットのリストからもわかります。
おまけ:グリッドサーチ結果をcsvに保存
グリッドサーチして探査したパラメータの組み合わせとスコアは一度プログラムを終了させるとメモリから飛んでしまいます。
ここではおまけとして、グリッドサーチで得た結果一覧をサマリとしてcsvに保存する方法を紹介します。
以下のコードを先ほどの全コードの一番下に追記して実行すると、実行した.pyファイルのあるフォルダ内に「summary.csv」が作成されます。
|
1 2 3 4 |
# データフレームに変換してサマリをcsvに保存 df_summary = pd.DataFrame(params) # 辞書型のパラメータをデータフレームに変換 df_summary['Score'] = pd.Series(scores) # スコアをデータフレームに追加 df_summary.to_csv('summary.csv', encoding='shift_jis') # csvファイルに結果一覧を保存 |
.cv_results_['params']で取得したパラメータセットは辞書型ですが、この辞書型はPandasデータフレームに変換可能です。データフレームにすることでヘッダにハイパーパラメータ名がただ1つだけ記載された表になるので、大変見やすいです。
下図が参考画像です。
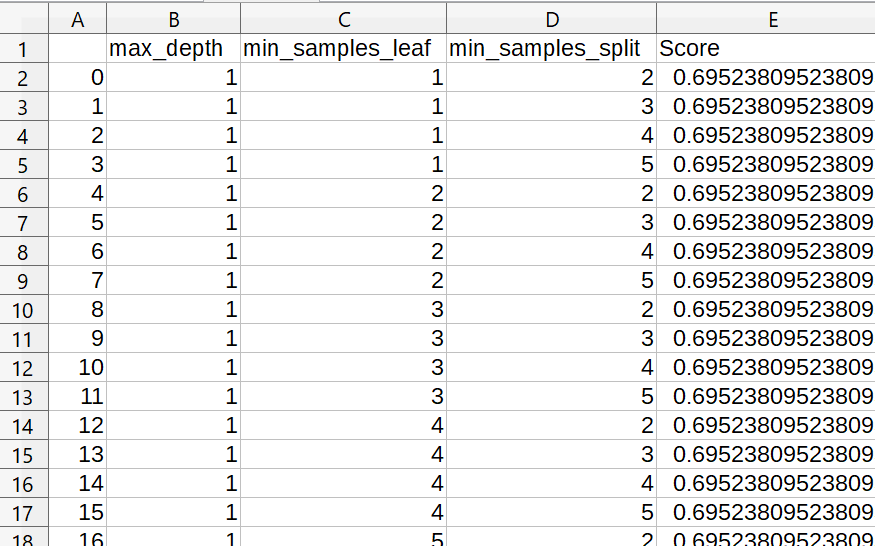
まとめ
今回はグリッドサーチにscikit-learnのGridSearchCVを使った簡単な方法を紹介しました。
自力でやろうとするとかなり面倒な作業もライブラリの力を借りると一発でグリッドサーチや交差検証まで出来てしまいました。
決定木、ランダムフォレスト、SVM…古典的な機械学習手法でもパラメータの組み合わせ次第で実データに役立つ機会はまだまだあると思いますので、是非このグリッドサーチは色々なモデルで出来るようにしておきたい所です。
しかし、このグリッドサーチ。最良の結果を出してくれるのは良いんだけど何とか可視化出来ないものか。2変数であればヒートマップで一目瞭然だけど、3、4変数以上の多変量になるとそうもいきません。
結果をうまく可視化できると、より汎化性能の良いパラメータも見つかるかも知れないので、今度ちょっとトライしてみよう!
機械学習手法を覚えてきたので、モデル検証の方法もどんどん習得して行きましょう!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント