
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

機械学習ではホールドアウト法として1つのデータセットから訓練データとテストデータを分けることをよく行います。ここでは、Pythonのscikit-learnに含まれるtrain_test_splitを使った簡単なデータ分割方法を紹介します。
こんにちは。wat(@watlablog)です。ここではscikit-learnの便利メソッドであるtrain_test_splitを使ったデータ分割方法を紹介します!
ホールドアウト法でバリデーションする
ホールドアウト法とは?
ホールドアウト法とは、機械学習においてデータを全て教師データとするのではなく、全体のデータから一部をテストデータ、残りを訓練データとして学習に用いる方法のことです。下図がイメージ図です。
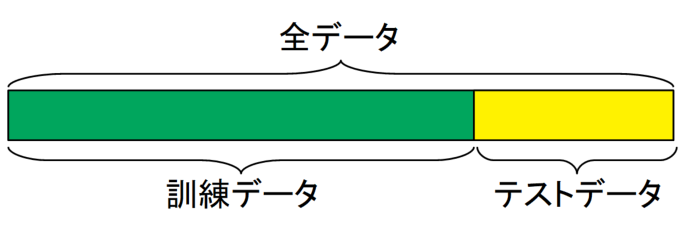
上記はシンプルに訓練データとテストデータに分けただけですが、さらに下図のように訓練データ、検証データ、テストデータと3分割する方法もあります。
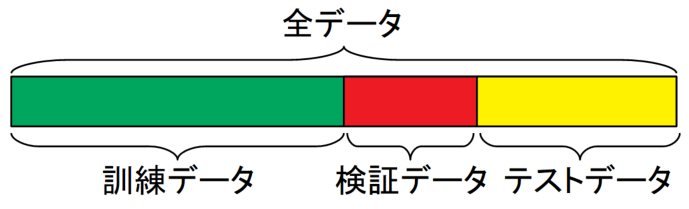
この方法は訓練データでモデルを学習させ、検証データで学習結果の評価を行い、学習を繰り返します。そして最後に完成したモデルの最終評価をテストデータで行うといった流れをとります。
このように検証を行うことをバリデーション(Validation)と呼びます。
データを分ける時の注意点
データの偏りに注意
当然といえば当然ですが、訓練データと評価に使うデータが偏っていては何を学習しているのかわからないので注意が必要です。
例えばAという花のデータだけを使って複数の花の分類モデルを作ろうとしたりしては精度が出ることはありません。
そのため、このような場合はデータの並び自体がランダムであるか、データ分割時にランダムに分離する必要があります。
時系列データの場合の注意
時系列データの場合は先ほどと逆で、データの並び自体に意味や繋がりがあります。そのような系列データをランダムに分割してしまうと、これもモデルの予測精度を著しく落とす要因となります。
ホールドアウト法はデータ検証の有効な手法の1つですが、データの種類や意味合い、サンプリング時の素性等を良く把握した上で行いましょう。
scikit-learnで簡単にデータ分割しよう!
データの分割方法には色々あります。割と簡単に作れるかも知れませんが、その都度自作のデータ分割関数を作っていたりするのは、若干面倒な所がありあまりやりたくありません。
ランダムにするしないによって数行のコードを入れ替えるのも使い勝手が悪そうです。そんな時、sklearn.model_selectionにあるtrain_test_splitが重宝されます。
まだscikit-learnを使った事が無い方は是非「Python機械学習!scikit-learnインストールと例題」の記事を確認してみて下さい。scikit-learnには機械学習プログラムの便利な関数が豊富にある様子がわかると思います。
それでは早速プログラムを作りながらその効果を見ていきましょう!
ホールドアウト法のためのデータ分割Pythonコード
サンプルコード
ここではscikit-learnことsklearnからirisデータセット(アヤメの分類に関するサンプルデータセット)を読み込み、pandasデータフレーム形式にしてからtrain_test_splitを使っています。
全コードを以下に示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from sklearn import datasets from sklearn.model_selection import train_test_split import pandas as pd # データを用意する iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む df = pd.DataFrame(iris.data) # pandasのデータフレーム構造に変換する train, test = train_test_split(df, # 訓練データとテストデータに分割する test_size=0.3, # テストデータの割合 shuffle=True, # シャッフルする random_state=0) # 乱数シードを固定する # 結果をコンソールに表示 print('Training data=', len(train)) print(train) print('Test data=', len(test)) print(test) print('Ratio=', len(test)/len(df)) |
train_test_splitの引数としてデータそのものの他に、まずtest_sizeを指定していますが、これはテストデータの割合を意味しています。ここではテストデータを30%にするように分割します。
次にshuffleをTrueにすると、行をランダムに分割してくれます。先ほどの注意点を思い出しTrueかFalseを選びましょう。
最後にrandam_stateですが、これは乱数シードの番号を意味しています。
コンピュータで作る乱数は真の乱数ではなく、疑似乱数というもので、この乱数シードが同じであればランダムに見えて毎回同じ並びでデータが分割されます。
モデルを検証する時に毎回同じデータ分割にしたい時はこの引数を適当な番号で指定しておくと良いでしょう。
実行結果
上記コードを実行すると以下の結果を得ます。訓練データが105個、テストデータが45個、テストデータの割合は0.3と指定した通りの分割が出来ていますね。
また、データのインデックスがばらばらになっていることから、shuffleの効果も出ています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
Training data= 105 0 1 2 3 60 5.0 2.0 3.5 1.0 116 6.5 3.0 5.5 1.8 144 6.7 3.3 5.7 2.5 119 6.0 2.2 5.0 1.5 108 6.7 2.5 5.8 1.8 .. ... ... ... ... 9 4.9 3.1 1.5 0.1 103 6.3 2.9 5.6 1.8 67 5.8 2.7 4.1 1.0 117 7.7 3.8 6.7 2.2 47 4.6 3.2 1.4 0.2 [105 rows x 4 columns] Test data= 45 0 1 2 3 114 5.8 2.8 5.1 2.4 62 6.0 2.2 4.0 1.0 33 5.5 4.2 1.4 0.2 107 7.3 2.9 6.3 1.8 7 5.0 3.4 1.5 0.2 100 6.3 3.3 6.0 2.5 40 5.0 3.5 1.3 0.3 86 6.7 3.1 4.7 1.5 76 6.8 2.8 4.8 1.4 71 6.1 2.8 4.0 1.3 134 6.1 2.6 5.6 1.4 51 6.4 3.2 4.5 1.5 73 6.1 2.8 4.7 1.2 54 6.5 2.8 4.6 1.5 63 6.1 2.9 4.7 1.4 37 4.9 3.6 1.4 0.1 78 6.0 2.9 4.5 1.5 90 5.5 2.6 4.4 1.2 45 4.8 3.0 1.4 0.3 16 5.4 3.9 1.3 0.4 121 5.6 2.8 4.9 2.0 66 5.6 3.0 4.5 1.5 24 4.8 3.4 1.9 0.2 8 4.4 2.9 1.4 0.2 126 6.2 2.8 4.8 1.8 22 4.6 3.6 1.0 0.2 44 5.1 3.8 1.9 0.4 97 6.2 2.9 4.3 1.3 93 5.0 2.3 3.3 1.0 26 5.0 3.4 1.6 0.4 137 6.4 3.1 5.5 1.8 84 5.4 3.0 4.5 1.5 27 5.2 3.5 1.5 0.2 127 6.1 3.0 4.9 1.8 132 6.4 2.8 5.6 2.2 59 5.2 2.7 3.9 1.4 18 5.7 3.8 1.7 0.3 83 6.0 2.7 5.1 1.6 61 5.9 3.0 4.2 1.5 92 5.8 2.6 4.0 1.2 112 6.8 3.0 5.5 2.1 2 4.7 3.2 1.3 0.2 141 6.9 3.1 5.1 2.3 43 5.0 3.5 1.6 0.6 10 5.4 3.7 1.5 0.2 Ratio= 0.3 |
まとめ
今回はワンポイントTipsのような短い記事ですが、データ分割1つとってもPythonには非常に便利な方法があることがわかりました。
しかしホールドアウト法のデータセット分割には注意点がいくつかあり、実践データを扱う時には気を付けなければなりません。
train_test_splitは今後のデータ分析で大変重宝しそうな手法だと感じました。
この記事は次にやりたいことの布石です!だんだんと実際のデータ処理を覚えていきます!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント