
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Pandasは機械学習の入力データ前処理で重宝されるPythonのライブラリです。ここではPandasデータフレームで読み込んだタイムスタンプ付きの時系列データを月毎に集計(合計・平均・最大値・最小値)する方法を紹介します。
こんにちは。wat(@watlablog)です。今回は時系列データ処理として、Pandasの月毎の集計方法を学びます!
時系列データの概要とサンプルデータ説明
時系列データとは?
時系列データ(Time-series data)とは、直訳すると時間によって変化するデータの総称です。
例えば毎日の気温といった気象情報、株価や外国為替といった金融情報等あらゆるデータ種があてはまります。
振動実験に代表されるような時間刻みのオーダーがmsやμsのデータも時系列データと呼びますが、このページでは日(day)、月(month)、年(year)といったタイムスタンプで記録されたデータを扱います。
タイムスタンプ(Timestamp)とは、ある出来事が発生した日付や時刻を示す文字列のことです。
古くは郵便屋さんが郵便物に押印することで発送の証明に使っていたのでスタンプという名称が付いているそうですが、現在ではコンピュータ用語としても広く知られています。
タイムスタンプで記録された時系列データのメリットは、なんといっても年、月といったある程度の期間で集計可能であることにあります。
このような「期間」でデータを分析する例としては毎月の予算管理や各種月度報告が挙げられます。時系列データを分析することで、何かしらの施策を打った時の効果が変化として現れたかどうかを調べたり、分析結果から今後どうすべきかといった未来の行動の決定判断をしたりすることが可能です。
Excel等の表計算ソフトの場合、あらかじめマクロや計算式を用意しておけばグラフ化まで容易に処理することもできますが、Python等のプログラミング言語でできるようにしておくと各種ライブラリを併用したり、機械学習に利用したりと活用の幅が拡がります。
このページではタイムスタンプを利用した集計コードの例を紹介します。
タイムスタンプの例
年月日のタイムスタンプ例を以下に示します。年の順番は日本と欧米で異なったり、月を英単語の略で表現したりと様々なフォーマットがあります。
|
1 2 3 4 5 |
date1 date2 date3 date4 0 2019/12/20 2019-12-20 12-20-19 2019-Dec-20 1 2019/12/25 2019-12-25 12-25-19 2019-Dec-25 2 2020/01/01 2020-01-01 01-01-20 2020-Jan-01 3 2020/01/05 2020-01-05 01-05-20 2020-Jan-05 |
ちなみに、これらのタイムスタンプは以下のコードのようにpd.to_datetimeで簡単に文字列からPandasで扱えるTimestamp型に変換することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import pandas as pd df = pd.DataFrame([['2019/12/20', '2019-12-20', '12-20-19', '2019-Dec-20'], ['2019/12/25', '2019-12-25', '12-25-19', '2019-Dec-25'], ['2020/01/01', '2020-01-01', '01-01-20', '2020-Jan-01'], ['2020/01/05', '2020-01-05', '01-05-20', '2020-Jan-05']], columns=['date1', 'date2', 'date3', 'date4']) print(df) print(type(df.iloc[0,0])) df['date1'] = pd.to_datetime(df['date1']) df['date2'] = pd.to_datetime(df['date2']) df['date3'] = pd.to_datetime(df['date3']) df['date4'] = pd.to_datetime(df['date4']) print(df) print(type(df.iloc[0,0])) |
このコードを実行すると、コンソールに以下の結果が表示されます。全てのデータが「year-month-day」に変換されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
date1 date2 date3 date4 0 2019/12/20 2019-12-20 12-20-19 2019-Dec-20 1 2019/12/25 2019-12-25 12-25-19 2019-Dec-25 2 2020/01/01 2020-01-01 01-01-20 2020-Jan-01 3 2020/01/05 2020-01-05 01-05-20 2020-Jan-05 <class 'str'> date1 date2 date3 date4 0 2019-12-20 2019-12-20 2019-12-20 2019-12-20 1 2019-12-25 2019-12-25 2019-12-25 2019-12-25 2 2020-01-01 2020-01-01 2020-01-01 2020-01-01 3 2020-01-05 2020-01-05 2020-01-05 2020-01-05 <class 'pandas._libs.tslibs.timestamps.Timestamp'> |
今回のサンプルデータ:Googleトレンド
今回サンプルとして使用するデータは、Googleトレンドで得た主な機械学習フレームワークの検索インタレストデータです。
検索インタレストとは、値が高ければGoogle検索回数が多かったことを示す、一種の傾向分析用のデータです。
今回はGoogleトレンドからダウンロードしたcsvを以下のように少し加工したファイルを使います。
GoogleトレンドのデータはPandas標準のタイムスタンプフォーマットの文字列が使われています。
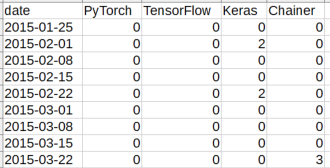
これをそのままmatplotlibでプロットすると…
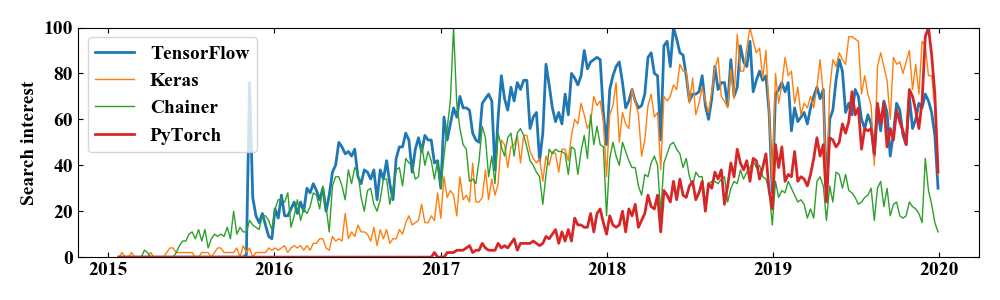
特にこれでも問題ないかも知れませんが、毎日の細かい変動成分が多く、ごちゃごちゃして見難いですね。
今回はこのデータを月毎に集計します。
Pandasの基本操作
Pandasの基本操作は「Python/Pandasの基本操作!データフレーム行列の取扱い」にまとめています。まだPandasに不慣れな方は、是非こちらの記事も参考にしてみて下さい。
Pandasで月毎に集計するコード
全コード
詳細説明の前に、全コードを以下に示します。
基本的には先ほど紹介したPandas基本操作の記事に記載の内容ばかりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import pandas as pd from matplotlib import pyplot as plt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters() # ファイルを読み込む df = pd.read_csv('GoogleTrend.csv', index_col='date', parse_dates=True) # マルチインデックスで「タイムスタンプ」以外に「年」と「月」をセットする df = df.set_index([df.index.year, df.index.month, df.index]) df.index.names = ['year', 'month', 'date'] # インデックスの名前を付ける # 月毎に集計 summary = df.sum(level=('year', 'month')) # 年月単位で合計を集計する summary = summary.reset_index() # マルチインデックスを解除する summary['year'] = summary['year'].astype(str) # 「year」列を文字列にする summary['month'] = summary['month'].astype(str) # 「month」列を文字列にする # 「year」と「month」列を「-」で繋ぎ、タイムスタンプに変換する date = pd.to_datetime(summary['year'].str.cat(summary['month'], sep='-')) # プロット用のデータをSeriesで抽出する pytorch = summary['PyTorch'] tensorflow = summary['TensorFlow'] keras = summary['Keras'] chainer = summary['Chainer'] # ここからグラフ描画 # フォントの種類とサイズを設定する plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける fig = plt.figure(figsize=(10, 3)) ax1 = fig.add_subplot(111) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する ax1.set_ylabel('Sum of Monthly Search interests') # データプロット ax1.plot(date, tensorflow, label='TensorFlow', lw=2) ax1.plot(date, keras, label='Keras', lw=1) ax1.plot(date, chainer, label='Chainer', lw=1) ax1.plot(date, pytorch, label='PyTorch', lw=2) # グラフを表示する plt.legend() fig.tight_layout() plt.show() plt.close() |
実行結果
上記コードを実行すると以下のグラフがプロットされます。
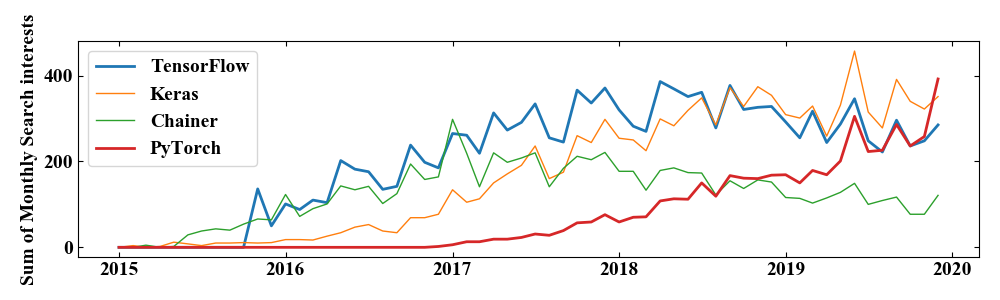
月毎の総和を集計することでPyTorchの躍進という要点を表現した非常に見易い結果となりました(…なりましたよね?)。
コード説明
集計に使う要素をインデックスに登録する
ここはやり方が色々あると思いますが、僕の場合は以下のコードで、まず「年」と「月」の要素をパースしてマルチインデックスに登録しました。
|
1 2 3 |
# マルチインデックスで「タイムスタンプ」以外に「年」と「月」をセットする df = df.set_index([df.index.year, df.index.month, df.index]) df.index.names = ['year', 'month', 'date'] # インデックスの名前を付ける |
この時点のdfの中身は以下になります。左のインデックスが3列になっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PyTorch TensorFlow Keras Chainer year month date 2015 1 2015-01-25 0 0 0 0 2 2015-02-01 0 0 2 0 2015-02-08 0 0 0 0 2015-02-15 0 0 0 0 2015-02-22 0 0 2 0 ... ... ... ... ... 2019 12 2019-12-01 96 71 92 43 2019-12-08 100 68 79 29 2019-12-15 88 63 79 23 2019-12-22 71 53 65 15 2019-12-29 37 30 36 11 |
月の集計をする
以下のコードの.sumで総和を集計しています。他にも.max、.min、.meanといった基本的な統計量も集計することが出来ます。ここで、引数にlevel=('year', 'month')と2種類のレベルを同時に指定しています。
月で集計するからといって'month'だけにすると、2015年1月も2016年1月も全て1月として集計されてしまうので、2つ設定することが重要です。
|
1 2 3 4 5 6 7 |
# 月毎に集計 summary = df.sum(level=('year', 'month')) # 年月単位で合計を集計する # その他の集計例 summary = df.max(level=('year', 'month')) # 年月単位で最大値を集計する summary = df.min(level=('year', 'month')) # 年月単位で最小値を集計する summary = df.mean(level=('year', 'month')) # 年月単位で平均を集計する |
集計結果プロットの横軸を作る
レベルを設定して集計すると、date列が無くなります。matplotlibでグラフにプロットするためには横軸が必要なので、以下のコードで横軸を作成しています。
横軸はタイムスタンプにするため、先ほど生成したyearとmonthを一度.astypeで文字列に変換し、文字列として.str.catで結合してから.to_datetimeでタイムスタンプに変換しています。
|
1 2 3 4 5 6 |
summary = summary.reset_index() # マルチインデックスを解除する summary['year'] = summary['year'].astype(str) # 「year」列を文字列にする summary['month'] = summary['month'].astype(str) # 「month」列を文字列にする # 「year」と「month」列を「-」で繋ぎ、タイムスタンプに変換する date = pd.to_datetime(summary['year'].str.cat(summary['month'], sep='-')) |
まとめ
本ページでは時系列データの概要と集計のメリット、タイムスタンプの例を説明し、Pandasで月毎に集計する方法の例を紹介しました。
使いこなせばExcelよりも高速なデータ処理ができると考えられ、これから様々なデータセットに対しても使っていける内容と思います。
こんなに簡単に集計処理ができるとは思ってなかったので、かなり驚いています!Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!