
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Pandasは機械学習を行う場合に多用することになるPython用の強力なデータ分析ツールです。様々な機能を全てマスターするのは時間がかかりますが、ここではよく使う基本操作として、内容を絞って実例とともに紹介します。
こんにちは。wat(@watlablog)です。
機械学習の勉強として統計を学んでいると、Pandasの習得が必須と感じました!ここではPandasでよく使う行列操作をまとめます!
Pandasでできることのおさらい
Pandasはデータ分析の「前処理」で活躍する
Pandasについての簡単な説明は過去に「Python/Pandasなら文字数値混在csvも簡単読み込み!」で紹介しましたが、実に多彩なデータ処理関数を持っているライブラリです。
Pythonユーザであればお馴染みのNumPyというライブラリも似たようなデータ処理ライブラリを多数持っていますが、Pandasの場合はデータフレームという構造を持ち、まるでExcelのような表計算ソフトを扱っているかのような使い勝手を実現していることが特徴です。
Pythonは機械学習の分野で特に人気のプログラミング言語ですが、機械学習では学習に使うためのデータをきちんと扱えるように前処理を行ったり、データがどういう傾向を持っているかを調べる基礎集計を行ったりします。
Pandasは実際に機械学習にかける前に、前処理としてデータを加工、集計したりする場合に特に活躍するライブラリです。
前置きはこれくらいにして、早速Pandasを使ってみましょう!
Pandasのインストール
Pandasをまだインストールしていない方でも、pipを使えば簡単にインストール可能です。筆者と同じWindowsでAnacondaを使っていない場合は以下のpipコマンドでインストールが可能です。
「python -m pip install pandas」
このページで説明する内容は以下のバージョンで動作を確認しています。
|
1 2 3 4 |
Python 3.7.3 pandas==0.25.1 numpy==1.16.2 matplotlib==3.0.3 |
Pandasの基本的な行列操作
Pandasの取扱いの全ては公式ドキュメントに記載されています。ここでは公式ドキュメントを参考にしてはいますが、膨大な機能から行列の操作に絞って内容をまとめていきます。
公式ドキュメント:pandas.pydata.org
データフレーム新規作成
データフレームを作る:.DataFrame
ファイルからデータを読み込む方法は「Python/Pandasなら文字数値混在csvも簡単読み込み!」で説明した通りですが、自力でデータフレームを作る場合は以下の用量で簡単に生成できます。
|
1 2 3 4 5 6 7 8 |
import pandas as pd df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) |
pd.DataFrameを使ってExcelのテーブルデータのように行列を指定しています。文字列も同時に考慮することが可能です。さらに「columns」でヘッダを作成することができます。
上記コードを実行すると以下の結果を得ます。縦に並んだ「0 1 2 3」は自動的に割り当てられています。
|
1 2 3 4 5 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 |
自力でデータを作る方法を知っておけば、プログラムで動的に作ることも容易になります!
列操作
データ計算した結果を列に追加する
表計算ソフトのように使う、と聞いてまず「列毎に一気に計算する」操作を思い浮かべます。
以下のコードは先ほどのデータフレームの「disp」列の値を「velo」列の値で割り、「time」列を一番右の列に挿入する方法です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # 'disp'列と'velo'列を計算した'time'列を追加する df['time'] = df['disp'] / df['velo'] print(df) |
実行結果はこちら。time列が計算され、列として新しく追加されています。
|
1 2 3 4 5 6 7 8 9 10 11 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName disp velo acc time 0 Data A 1.0 1.0 1.0 1.000000 1 Data B 1.5 1.1 0.8 1.363636 2 Data C 0.8 1.2 1.3 0.666667 3 Data D 1.1 0.9 1.1 1.222222 |
シリーズとして列を抽出:.Series
列を抽出したい時はSeries(シリーズ)という機能を使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # Series(シリーズ)として列を抽出 df_disp = pd.Series(df['disp']) print(df_disp) |
上記コードはシリーズとしてdisp列を抽出した例で、実行結果は以下になります。シリーズとは、ここでいう「0 1 2 3」という行ラベルとセットになった1Dデータのことです。
|
1 2 3 4 5 6 7 8 9 10 11 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 0 1.0 1 1.5 2 0.8 3 1.1 Name: disp, dtype: float64 |
2列以上を抽出
先ほどは1列だけでしたが、データフレームとして2列以上を抽出するには以下のような方法があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # 2列を抽出 df_Name_velo = df[['DataName','velo']] print(df_Name_velo) |
以下が実行結果です。名前で指定できるのは便利ですね。
|
1 2 3 4 5 6 7 8 9 10 11 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName velo 0 Data A 1.0 1 Data B 1.1 2 Data C 1.2 3 Data D 0.9 |
列名を変更する:.columns
列名を一気に変更する場合は.columnsで指定するのが便利。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['A', 'B', 'C', 'D']) print(df) df.columns = ['DataName', 'disp', 'velo', 'acc'] print(df) |
以下が結果。列名が変更されました。
|
1 2 3 4 5 6 7 8 9 10 |
A B C D 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 |
行操作
シリーズとして行を抽出:.iloc
行は.ilocを使って抽出することが可能です。.ilocで1行抽出すると、そのデータはこれまでの列ラベルが行ラベルになったシリーズデータになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # Series(シリーズ)として1行抽出 df_C = df.iloc[2] print(df_C) |
以下はData C(行番号2)で抽出した結果です。ここでお気づきだと思いますが、行ラベルは列ラベルと同じく「0 1 2 3」以外の名前を付けることができます。
|
1 2 3 4 5 6 7 8 9 10 11 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName Data C disp 0.8 velo 1.2 acc 1.3 Name: 2, dtype: object |
.ilocで行を抽出する場合はラベル名に関係なく、順番から抽出位置を指定することができます。逆に、行ラベル名で抽出する場合は.locを使うことになります。
2行以上を抽出:.iloc
複数行を抽出する場合も、複数列を抽出した時と同じように書きます(以下コード)。行の場合は.ilocを使う点だけが異なります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # 2行を抽出 df_CD = df.iloc[[2, 3]] print(df_CD) |
Data C(行指標2)とData D(行指標3)を抽出してみました。
|
1 2 3 4 5 6 7 8 9 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName disp velo acc 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 |
行列操作
行列を指定して要素を取得:.iloc
行と列を共に指定する方法も.ilocを使えば以下のように簡単に要素を抽出することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # 行列を指定して要素取得 df_element = df.iloc[2, 1] print(df_element) |
以下が実行結果です。Data C(行番号2)とdisp(列番号1)が交差する要素を抽出してみました。
|
1 2 3 4 5 6 7 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 0.8 |
行結合:.concat
行方向の結合には.concatを使います。axis=0とする部分は省略可能ですが、後ほど学ぶ列方向の結合と合わせて覚えるには書いといた方が良いかも。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd df1 = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) df2 = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) # 行方向に結合 df = pd.concat([df1, df2], axis=0) print(df) |
以下が結果です。
|
1 2 3 4 5 6 7 8 9 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 |
列結合:.concat
.concatでaxis=1とする事で列方向に結合する事が可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd df1 = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) df2 = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) # 列方向に結合 df = pd.concat([df1, df2], axis=1) print(df) |
以下が結果です。列方向に二つのデータフレームが結合されました。
|
1 2 3 4 5 |
DataName disp velo acc DataName disp velo acc 0 Data A 1.0 1.0 1.0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 Data D 1.1 0.9 1.1 |
データ検索
条件式で絞込み
ある条件を満たしたデータだけを抽出したい時は、以下のコードのように抽出を行います。条件式にはif文やwhile文で使用する演算子を使うことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd # データを用意する df = pd.DataFrame([['Data A', 1.0, 1.0, 1.0], ['Data B', 1.5, 1.1, 0.8], ['Data C', 0.8, 1.2, 1.3], ['Data D', 1.1, 0.9, 1.1]], columns=['DataName', 'disp', 'velo', 'acc']) print(df) # dispが1を超えるデータのみ抽出 disp_low = df[df['disp'] > 1] print(disp_low) |
上記サンプルの実行結果を下に示します。今回はdfのdisp列の中で、1を超えるデータセットだけを抽出してみました。
|
1 2 3 4 5 6 7 8 9 |
DataName disp velo acc 0 Data A 1.0 1.0 1.0 1 Data B 1.5 1.1 0.8 2 Data C 0.8 1.2 1.3 3 Data D 1.1 0.9 1.1 DataName disp velo acc 1 Data B 1.5 1.1 0.8 3 Data D 1.1 0.9 1.1 |
インデックス操作
read_csvでインデックスを指定する
先ほど紹介した記事でcsvファイルの読み方は説明していましたが、便利な機能に「インデックスをデータから指定してファイルを開く」という方法もあります。
例えば以下の内容のcsvデータがあるとします。このファイルを普通にpd.read_csvで読むと行ラベル(インデックス)は0, 1, 2…となってしまいますが、
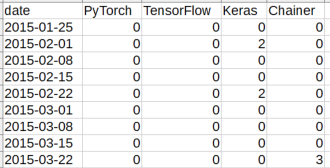
以下のコードのようにファイル読み込み時、index_colでインデックス列を指定することで初期的にインデックスの値を変えることが可能です。
特に今回の例のような時系列データ(年や月等のタイムスタンプが付いたデータ)はparse_dates=TrueとすることでPandasで日付データをそのまま扱うことができるようになります。
|
1 2 3 4 5 |
import pandas as pd df = pd.read_csv('sample.csv', index_col='date', parse_dates=True) print(df) |
以下が実行結果です。インデックスが日付のデータになりました。
|
1 2 3 4 5 6 7 8 |
PyTorch TensorFlow Keras Chainer date 2015-01-25 0 0 0 0 2015-02-01 0 0 2 0 2015-02-08 0 0 0 0 2015-02-15 0 0 0 0 2015-02-22 0 0 2 0 ... ... ... ... ... |
マルチインデックス
インデックスは1つだけではなく、以下のコードでマルチインデックスとして複数持たすことが可能です。
|
1 2 3 4 5 6 7 |
import pandas as pd df = pd.read_csv('sample.csv', index_col='date', parse_dates=True) df = df.set_index([df.index.year, df.index.month, df.index]) df.index.names = ['year', 'month', 'date'] print(df) |
上記コードでは年と月のインデックスを.index.yearと.index.monthで作っており、以下の変換結果を得ます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PyTorch TensorFlow Keras Chainer year month date 2015 1 2015-01-25 0 0 0 0 2 2015-02-01 0 0 2 0 2015-02-08 0 0 0 0 2015-02-15 0 0 0 0 2015-02-22 0 0 2 0 ... ... ... ... ... 2019 12 2019-12-01 96 71 92 43 2019-12-08 100 68 79 29 2019-12-15 88 63 79 23 2019-12-22 71 53 65 15 2019-12-29 37 30 36 11 |
インデックスのリセット:.reset_index
一度作成したインデックスは.reset_index()でリセット可能です。
|
1 2 3 4 5 6 |
import pandas as pd df = pd.read_csv('sample.csv', index_col='date', parse_dates=True) df = df.reset_index() print(df) |
リセットすると行インデックスは0,1,2…になり、これまでインデックスになっていた値はデータフレームに移動します。
|
1 2 3 4 5 6 |
date PyTorch TensorFlow Keras Chainer 0 2015-01-25 0 0 0 0 1 2015-02-01 0 0 2 0 2 2015-02-08 0 0 0 0 3 2015-02-15 0 0 0 0 4 2015-02-22 0 0 2 0 |
データ操作
データ型変換:.astype
データの型は.astypeで変換可能です。以下のコードは数値型numpy.int64(64bit整数型)を文字列型strに変換しています。
|
1 2 3 4 5 |
import pandas as pd df = pd.read_csv('sample.csv') print(type(df.iloc[0, 1])) df['PyTorch'] = df['PyTorch'].astype(str) #データ型変換 print(type(df.iloc[0, 1])) |
typeで型を見てみると、しっかり変換されていることが確認できました。
|
1 2 |
<class 'numpy.int64'> <class 'str'> |
要素操作
文字列結合:.str.cat
データが文字列であれば以下のように.str.catで結合することができます。引数にsepを指定すれば結合させる文字列間に別の定型文字を入れることが可能です。
|
1 2 3 4 5 6 |
import pandas as pd df = pd.read_csv('sample.csv') df['PyTorch'] = df['PyTorch'].astype(str) df['TensorFlow'] = df['TensorFlow'].astype(str) df['PyTorch-TensorFlow'] = df['PyTorch'].str.cat(df['TensorFlow'], sep='-') #文字列結合 print(df) |
以下が実行結果です。文字列を連結した列を最後に追加しました(計算結果に意味はありません)。
|
1 2 3 4 5 6 |
date PyTorch TensorFlow Keras Chainer PyTorch-TensorFlow 0 2015-01-25 0 0 0 0 0-0 1 2015-02-01 0 0 2 0 0-0 2 2015-02-08 0 0 0 0 0-0 3 2015-02-15 0 0 0 0 0-0 4 2015-02-22 0 0 2 0 0-0 |
その他
Warning回避:To register the converters:
Pandasのデータフレーム形式のデータをmatplotlibで可視化する際、以下のような警告メッセージ(Warning)がでる場合があります。
|
1 2 3 4 |
To register the converters: >>> from pandas.plotting import register_matplotlib_converters >>> register_matplotlib_converters() warnings.warn(msg, FutureWarning) |
このままでも特に動作に問題の無い場合が多いのですが、このメッセージは以下のコードを明示的に書いておくことで出ないようにすることが出来ます。
|
1 2 |
from pandas.plotting import register_matplotlib_converters register_matplotlib_converters() |
まとめ
ここではPandasによるデータ処理をする前に、最低限覚えておきたい行列の操作に絞ってコードを紹介しました。
他にも欠損値の取扱い方や集計等もPandasの得意分野になりますが、そちらは別記事で紹介していこうと思います。
これでPandasを使って表計算ソフトのような操作ができるようになりそうです!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント