
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

行列散布図(ペアプロット)は大量の変数間の関係を一望できるため大変有用なデータ可視化手法です。しかし、表計算ソフトやPythonのmatplotlibを使ってペアプロットを作成するには思いのほか膨大な労力を要します。ここではseabornというライブラリを使い、わずか数行でペアプロットを描画する方法を紹介します。
こんにちは。wat(@watlablog)です。
seabornでペアプロットを行う方法、可視化結果の見方を紹介します!
seabornでカッコいいグラフを描画することができる
seabornとは?
seabornとは、Python用のデータ可視化ライブラリのことです。
データ可視化ライブラリというと、当WATLABブログではすっかりおなじみのmatplotlibがありますが、seabornはmatplotlibの機能を利用したライブラリでもあります。
matplotlibではちょっと手こずるカッコいいグラフを描きたい!という方にオススメできるライブラリです。
似たようなデータ可視化ライブラリには「Python/pyqtgraphのインストールとサンプル起動方法」で紹介したpyqtgraphもありましたね。
色々あるけど、使い分けはどうしたら良いの?
これは個人的な意見になってしまいますが、pyqtgraphは高速処理が秀でていてリアルタイムソリューションに適している感覚があります。
一方seabornは単なる可視化に留まらず、統計処理が得意であるため機械学習等をはじめとしたデータサイエンスの分野に適していると感じています。
もちろん得意・不得意はあり、どちらかだけを使えば良いということは無いので、「これから作るプログラムの要件に適しているのは?」という観点で常にライブラリの選択をすることが必要でしょう。
それでは、早速インストールしてみましょう!
pipでインストールする方法
インストールはpipで実施します。pipの詳細は「Pythonのパッケージ管理ツール pipの使い方とコマンド集」という記事をご確認下さい。
僕と同じWindowsであれば以下のコードをコマンドプロンプトに打ち込んで実行することでインストールが完了します。
|
1 |
python -m pip install seaborn |
ちなみに、僕はAnaconda等を使っていません。僕のPC環境や開発環境は「Python入門!初心者がインストールから学習開始するまでの3ステップ」という記事に詳細を書きましたので必要に応じてご参照下さい。
seabornはmatplotlibも必要ですので、上のコマンドでseabornをmatplotlibと置き換えてmatplotlibもインストールしておいて下さい。
行列散布図(ペアプロット)の使い所と見方
この記事では行列散布図(ペアプロット)の描き方を説明します。まずはこのペアプロットはなぜ、どういう場面で使われているのかの紹介と図の見方について説明をします。
手っ取り早くコードが見たい方は記事の後半までスクロールしてみて下さい!
ペアプロットを使う理由と事例
ペアプロットとは、大量の変数列があるデータに対し、全ての変数の組み合わせ毎に相関関係を見るためのプロットです。
2つの変数の相関関係は、通常横軸と縦軸に1つずつ変数軸をとり、散布図として値をプロットしていくことで確認できます(相関係数\(R\)とか\(R^{2}\)で評価する時に使う図です)。
今回紹介するペアプロットとは、和名で行列散布図という名称がついていることからわかるように散布図を行列として縦と横に並べた図を意味します。
こうすることで、変数が何個もある場合に一目で全変数の相関関係が一望できる図になり、多くの人がペアプロットを使う最大の理由でもあります。
百聞は一見にしかず、ということでまずはペアプロットの例を見てみましょう。以下はこれからサンプルとして扱うscikit-learnに収録されているIrisデータセットのペアプロット結果です。
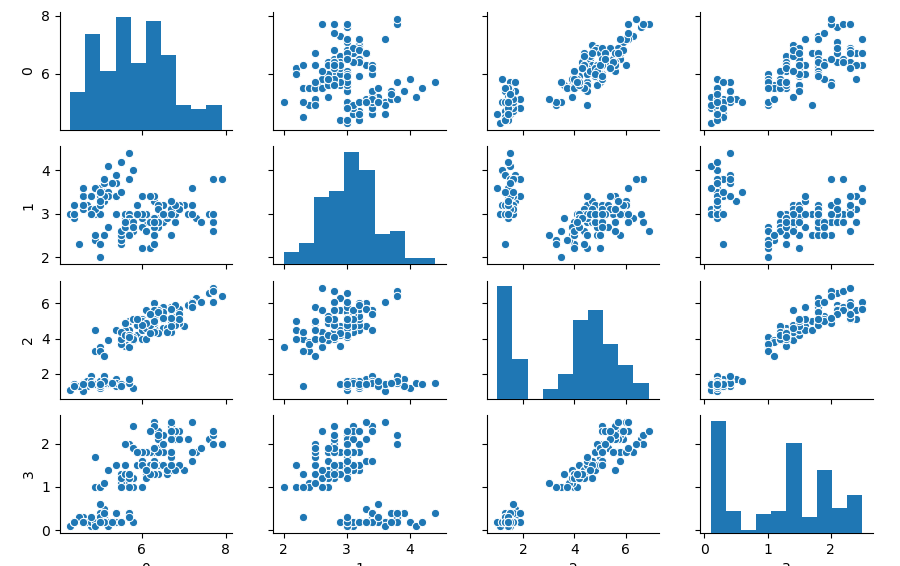
キレイだ!
…それっぽくて(?)プロットしただけで満足してしまいがちですが、芸術作品を作ったわけではないので、グラフの見方を説明していきます。
ペアプロットの見方
以下に、上記のペアプロット上にそれぞれの意味を重ね書きした説明図を作成してみました。
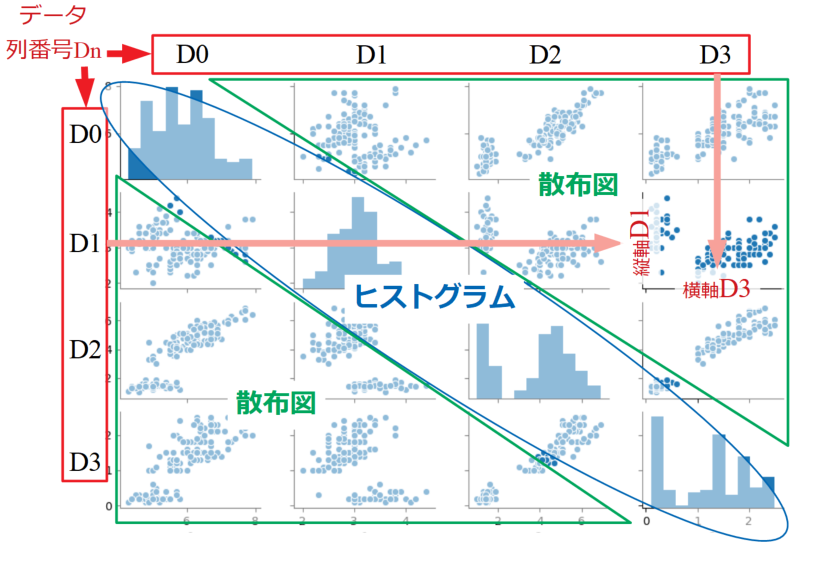
D0~D3というのは、データ変数の数です。後程詳しくデータセットの中身を見てみますが、1列目のデータがD0、2列目がD1…という意味です。
行列の縦と横はそれぞれのデータ変数が順番に並んでおり、ペアプロットとしては対角線上にヒストグラム、その他の位置に散布図が配置されています。
散布図の見方ですが、例えば行列の横D3、縦D1がクロスする位置にある散布図は、横軸にD3データ配列をとり縦軸にD1のデータ配列をとった図になっています。
このようにペアプロットは各変数の横軸と縦軸を全ての組み合わせで散布図をとっていることが特徴です。
横D0と縦D0等、同じ変数がクロスする所は散布図をプロットさせる意味がないのでデータのばらつき具合を一望できるヒストグラムになっているというわけです。
それでは、早速Pythonとseabornを使ってペアプロットを描画してみましょう!
Python/seabornでペアプロットするコード
用意するデータ形式
今回使用するのは、「Irisデータセット」というアヤメの品種に関する実測データです。このデータはscikit-learnという機械学習ライブラリをインストールすると同時に手に入るので、自分でリストデータを作成する必要はありません。
scikit-learnというライブラリのインストール方法は「Python機械学習!scikit-learnインストールと例題」に記載しましたので、是非ご確認下さい。
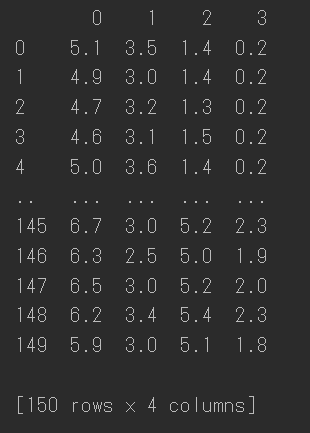
Irisデータセットの中身を以下の図に示します。ここではデータの意味はあまり説明しませんが、横の0, 1, 2, 3が変数(アヤメの花びらの各寸法要素)、縦に0~149と150個並んでいるのが寸法値を意味しています。
このようなデータを用意することでペアプロットを描画することが出来ます。
全コード
以下がseabornで複数変数を持つデータのペアプロットを描画する全Pythonコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import seaborn as sns from sklearn import datasets import pandas as pd from matplotlib import pyplot as plt # データを用意する iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む df = pd.DataFrame(iris.data) # pandasのデータフレーム構造に変換する print(df) # seabornで行列散布図(ペアプロット)を描く g = sns.pairplot(df) # ペアプロットをするデータを定義 plt.show() # グラフ表示 plt.close() # グラフを閉じる |
scikit-learnのデータセットを読み込む
scikit-learnのデータセットは「datasets.load_〇〇()」で呼び出すことが出来ます。今回は〇〇にIrisを入れてアヤメのデータセットを呼び出しています。
Pandasのデータフレーム構造が必要
import文でPandasをインポートしていますが、seabornで扱うデータはPandasというライブラリのデータフレーム構造にしておく必要があります。
Pandasも忘れずにインストールとインポートをしておきましょう。
Pandasについて、当WATLABブログでは「Python/Pandasなら文字数値混在csvも簡単読み込み!」で使った程度ですが、その他ライブラリと同様に「python -m pip install pandas」でインストール可能です。
Pandasデータフレーム構造へは、「pd.DataFrame()」という文で実行しています。
実行結果
再掲しますが、プログラムを実行すると以下の図が画面に表示されます。
最低限知っておきたいseaborn見た目の設定
ここまでの内容で、seabornを使ったペアプロットの方法は理解できたのではないかと思います。
しかし、そのままの可視化結果ではまだデータの解釈をするにあたり不十分な場合があります。
ここではseabornを使ったデータ分析でよく使う最低限の見た目に関する設定を紹介します。
データ種類別に色を分ける
以下のコードは、データを種類毎に色分けするコードです。
実はscikit-learnのIrisデータセットにはtargetという部分にアヤメの種類に関する情報が入っています。
「df['species']=iris.target」でその情報を「species(種類)」という列として5列目に追加しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import seaborn as sns from sklearn import datasets import pandas as pd from matplotlib import pyplot as plt iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む df = pd.DataFrame(iris.data) # pandasのデータフレーム形式に変換する # targetから種類データを取得しデータフレーム列へ追加 df['species'] = iris.target df.loc[df['species'] == 0, 'species'] = "setosa" df.loc[df['species'] == 1, 'species'] = "versicolor" df.loc[df['species'] == 2, 'species'] = "virginica" print(df) # seabornで行列散布図(ペアプロット)を描く g = sns.pairplot(df, hue='species') # ペアプロットをするデータを定義 plt.show() # グラフ表示 plt.close() # グラフを閉じる |
種類に関するデータといっても、実際には0, 1, 2という値が入っているだけなので、その次の行はPythonの内包表記を使って0をsatosa、1をversicolor、2をvirginicaというようにstring型として名称を与えています。setosa, versicolor, virginicaはそれぞれアヤメの品種です。
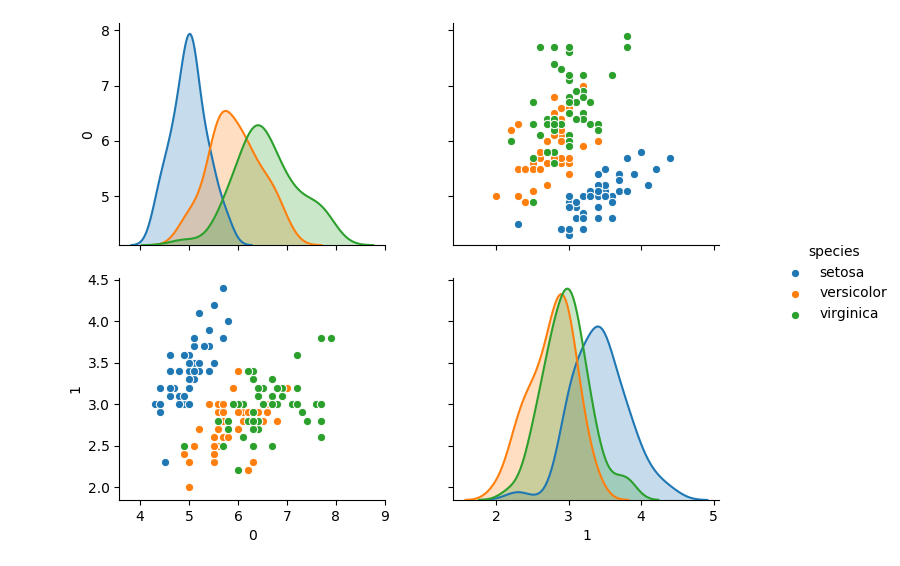
この種類分けを色に反映させるために「g=sns.pairplot(df, hue='species')」とペアプロットの引数を1つ増やしています。
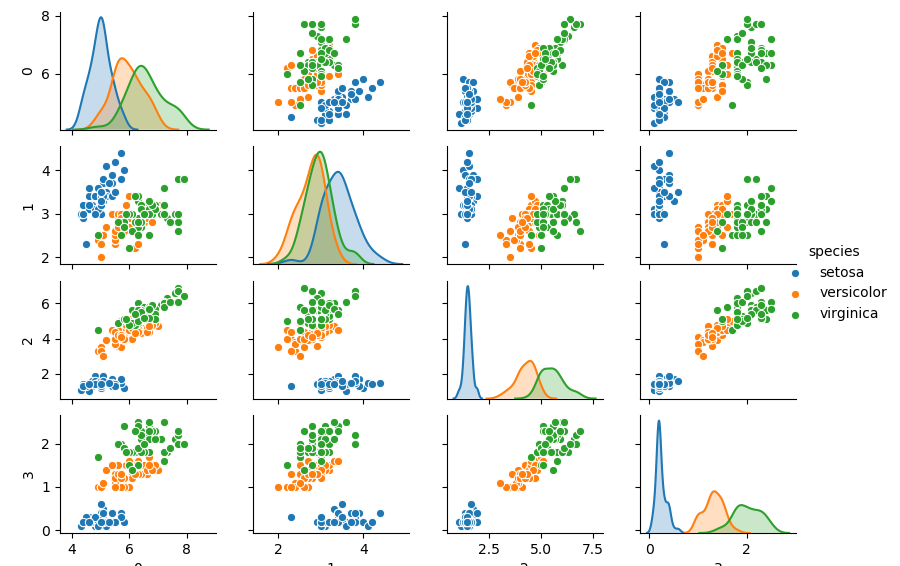
以下が実行で得られるペアプロット図です。
予めデータの種類がわかっている場合は色分けすることでかなり見やすくなりますね。
グラフサイズを変更する
次にグラフ全体のサイズ調整方法を紹介します。
ペアプロット図というのは大量の変数を扱うとグラフサイズが非常に大きくなります。 seabornのデフォルト設定でペアプロットを作成すると、変数の数が多ければ多いほどグラフも大きくなります。
手持ちのディスプレイに収まらない!というケースは往々にしてありますので、サイズ調整は最低限知っておきたい設定です。
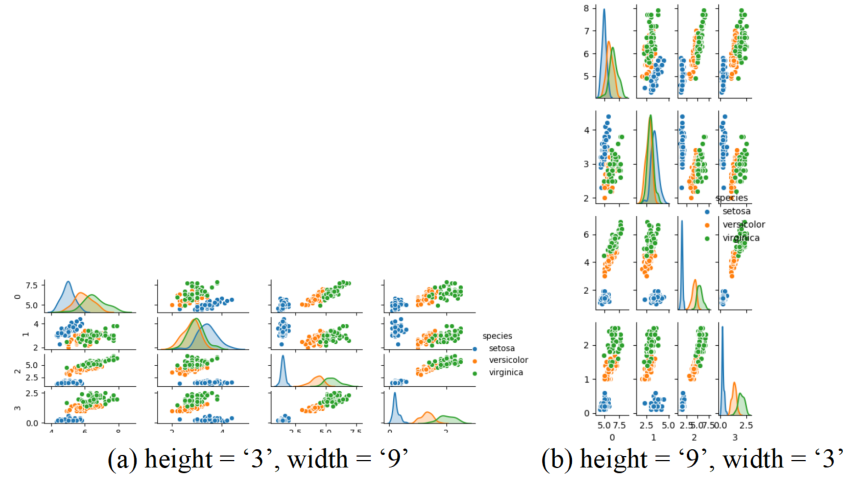
以下は上記コードのグラフ描画部分に「fig.set」として「figheight」と「figwidth」でそれぞれ高さと幅サイズを追加したコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import seaborn as sns from sklearn import datasets import pandas as pd from matplotlib import pyplot as plt iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む df = pd.DataFrame(iris.data) # pandasのデータフレーム形式に変換する # targetから種類データを取得しデータフレーム列へ追加 df['species'] = iris.target df.loc[df['species'] == 0, 'species'] = "setosa" df.loc[df['species'] == 1, 'species'] = "versicolor" df.loc[df['species'] == 2, 'species'] = "virginica" print(df) # seabornで行列散布図(ペアプロット)を描く g = sns.pairplot(df, hue='species') # ペアプロットをするデータを定義 g.fig.set_figheight(6) # グラフの高さを設定 g.fig.set_figwidth(9) # グラフの幅を設定 plt.show() # グラフ表示 plt.close() # グラフを閉じる |
このコードのfigheightとfigwidthの値を変更して実行することで、以下のようにグラフ全体のサイズを変えることが出来ます。
「軸名等が重なっていても良いからざっくり全体を見たい!」って時はまずこの設定でコンパクトにして眺めてみるのも良いですね。
表示するデータ変数を任意に指定する
最後はプロットするデータ変数を指定する方法を紹介します。
膨大なデータのうち「ある変数とある変数のみの相関関係が知りたい!全部は見たくない!」という場合はデータ表示の種類を絞ることで解決します。
以下のコードはpairplotの引数に「vers」という引数を設定し、表示させる変数を指定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import seaborn as sns from sklearn import datasets import pandas as pd from matplotlib import pyplot as plt iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む df = pd.DataFrame(iris.data) # pandasのデータフレーム形式に変換する # targetから種類データを取得しデータフレーム列へ追加 df['species'] = iris.target df.loc[df['species'] == 0, 'species'] = "setosa" df.loc[df['species'] == 1, 'species'] = "versicolor" df.loc[df['species'] == 2, 'species'] = "virginica" print(df) # seabornで行列散布図(ペアプロット)を描く g = sns.pairplot(df, hue='species', vars=[0, 1]) # ペアプロットをするデータを定義 g.fig.set_figheight(6) # グラフの高さを設定 g.fig.set_figwidth(9) # グラフの幅を設定 plt.show() # グラフ表示 plt.close() # グラフを閉じる |
以下の図が実行結果です。今回のコードは「vers=[0, 1]」と指定していますが、「vers=[1,3]」のようにも指定することが可能で、値は連続している必要がありません。
データフレーム自体を加工しなくても、着目変数だけを分析できるので覚えておいて損はない設定と思います。
まとめ
本記事では、seabornと行列散布図(ペアプロット)の概要を説明し、プロットの見方を図解によって説明しました。
ペアプロットは大量の変数データの関係性を一望する手法として非常に有用であり、近年のビッグデータ活用の強力な可視化ツールであると言えます。
表計算ソフト等の手作業でペアプロットを作成するのはかなりの手間ですが、seabornを使えばわずか数行で作成することができることがわかりました。
また、デフォルトの設定だけだと使い勝手が悪い部分として色分け、サイズ変更、表示数変更を紹介しました。これらの設定を適切な場面で使い分ければデータサイエンスの分野で迅速な問題解決ができると思います。
強力なデータ可視化手段を獲得した気がします!高いソフトを買わなくてもPythonがあれば色々できますね!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント