
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

SeleniumでWebスクレイピングをする時に、これまでxpathやid名を使ってきましたが、今回はHTMLのclass属性名で情報を取得してくる方法を紹介します。
こんにちは。wat(@watlablog)です。
Seleniumのfind関数には様々な機能があります。ここでは、HTMLのclass属性名で要素を取得する方法を紹介します!
ここで紹介している内容はWebスクレイピングの一例に過ぎません。僕はPython特化型学習サービス「PyQ(パイキュー)」で基礎を覚えました。体系的にPythonプログラミングやWebスクレイピングを覚えたい方は是非「PyQでPython学習!実際に登録してみた感想と気になる料金」の記事をご覧下さい。
HTMLのclass属性名を調べる
class属性名とは?
HTMLコードの中におけるclassとは、cssというスタイルシートで色やフォントといったデザインを決める時にグループ化しておく時に使います。
以下の画像はGoogleで「WATLAB」を検索したページのHTMLソースコードです。class属性名とは、この「class=" 〇〇 "」の〇〇の部分です。
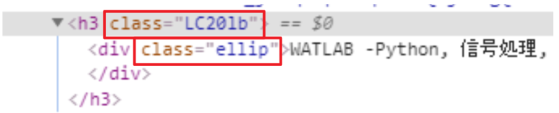
まずはこのclass属性名の調べ方を説明します。
Chrome拡張機能のXPath Helperを使って調べる
XPath Helperのおさらい
前回xpathを調べるためにGoogle Chromeの拡張機能である「XPath Helper」を使いましたが、今回もこのXPath Helperを使います。
XPath Helperのインストール方法と簡単な使い方、得られた情報を使ってPythonプログラムでスクレイピングする方法は「Chrome拡張!XPath Helperのインストールと使い方」に記事にしましたので、是非読んでみて下さい。
本来、このXPath Helperは、ツリー構造のHTMLファイルのルートパスを特定するxpathを調べるために使います。
しかしHTMLを選択すると要素がハイライトすることや、要素を右クリックして「検証」を行うとHTMLの該当箇所まで飛んでくれるので、xpathを調べる以外にも大変重宝します。
XPath Helperでclass属性名を調べる方法
それでは具体的な手順を説明します。
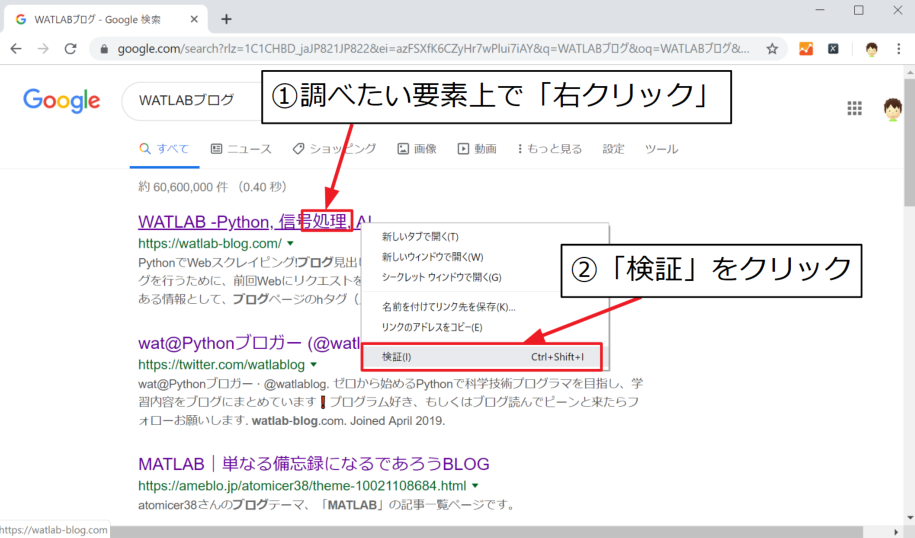
まず、XPath HelperがインストールされたGoogle Chromeで適当なページを開きます。ここでは、Google検索で「WATLABブログ」を調べた結果で説明します。
今回は検索トップに表示された当ブログの「タイトル」のclass属性名を取得します。
取得したい要素上で「右クリック」すると、メニューが出てきますので、「検証」をクリックします。
するとHTMLコードが右画面に表示され、さらに指定した要素の部分でハイライトされています。class属性名はこの付近にあるので、単純にこれをコピペして使ったり、その他の要素に同じclass名があるかどうかを検索したりして活用することができます。
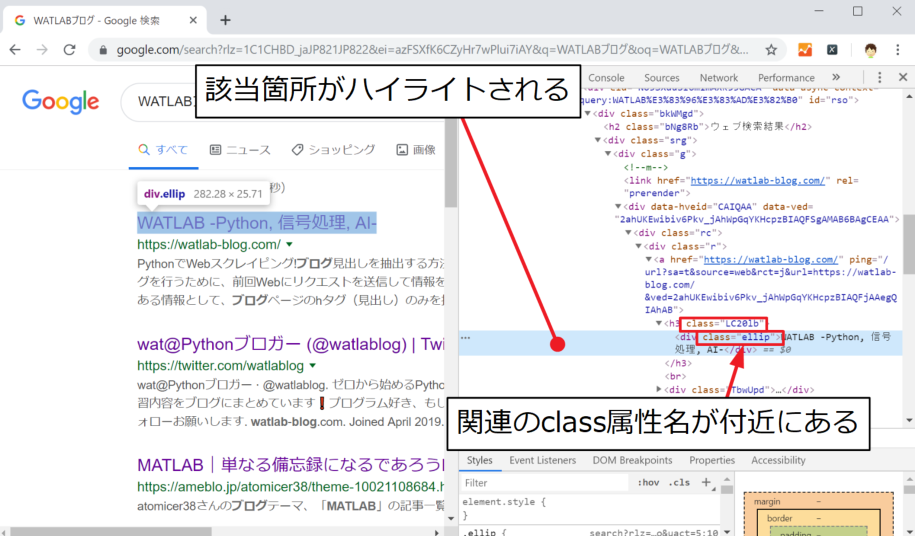
例えば、今回は検索結果のWebサイトタイトルのclass属性名を調査しましたが、今の所Google検索結果の各タイトルは同じclass属性名になっています。
このWebサイトのタイトルを前回紹介したxpathで取得すると、多層のdev要素が抽出されてしまい、さらに1ページ目と2ページ目、検索ワード毎にパスの内容が若干異なっていました。
おそらく検索ワードによっては間に画像サジェストや広告が入ることによってdevの層が変化しているのでしょう。
xpathはルートをしっかり把握する目的で使用する分には大変便利な方法ですが、classで名称が分けられている場合はこちらの方が良い場合もあります。
スクレイピングするWebサイトの種類によって手法を変える必要があるということですね。
class属性名で検索するPythonコード
全コード
今回もそれほど新しい内容は無いので、全コードを一度に載せてみました。
「Chrome拡張!XPath Helperのインストールと使い方」で.find_elements_by_xpathを使っていた部分を.find_elements_by_class_nameに変更しました。これでclass属性名による検索が可能になります。
elementではなく、elementsとしているので、HTMLの上から順番に全てのclass="LC20lb"を抽出することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import time # スリープを使うために必要 from selenium import webdriver # Webブラウザを自動操作する(python -m pip install selenium) import chromedriver_binary # パスを通すためのコード driver = webdriver.Chrome() # Chromeを準備 # サンプルのHTMLを開く driver.get('https://www.google.com/') # Googleを開く search = driver.find_element_by_name('q') # HTML内で検索ボックス(name='q')を指定する search.send_keys('WATLABブログ') # 検索ワードを送信する search.submit() # 検索を実行 time.sleep(3) # 3秒間待機 def ranking(driver): class_name = 'LC20lb' # class属性名 class_elems = driver.find_elements_by_class_name(class_name) # classでの指定 # 取得した要素を1つずつ表示 for elem in class_elems: print(elem.text) ranking(driver) driver.quit() # ブラウザを閉じる |
実行結果
実行すると、Google Chromeが自動的に立ち上がり、検索を開始します。
以下がprint文によってコンソールに表示される結果です。見事に検索結果ページに記載のタイトルが上から順番に抽出されています!(※2019年8月の結果)
|
1 2 3 4 5 6 7 8 9 |
WATLAB -Python, 信号処理, AI- wat@Pythonブロガー (@watlablog) | Twitter MATLAB|単なる備忘録になるであろうBLOG 【MATLABとは?】ディープラーニングで人気の言語を初心者向けに解説 ... スムーズワークス日想 » Blog Archive » MATLAB & Python スムーズワークス日想 » Blog Archive » MATLABプログラミング Simulink ... Matlab カテゴリーの記事一覧 - 六本木で働くデータサイエンティストのブログ Raspberry PiとMATLABを接続してプログラムを書く - はてなブログ MATLAB芸人なら知っておきたい小ネタ関数ベスト5 [rogy Advent ... |
まとめ
今回は備忘録的な要素が強い記事ですが、SeleniumでWebスクレイピングをする時の手法は多いに越したことはありません。
このページではHTMLのclass属性名とは何かを簡単に説明し、Google Chromeの拡張機能であるXPath Helperを使ったclass属性名の調べ方、調べたclass属性名を使ったPythonスクレイピングコードまでをセットで紹介しました。
やりたいことをやるためには、Python以外にもHTMLの知識が必要になってきましたが、当ブログでは引き続き順当に周辺知識を吸収してスキルアップをしたいと思います。
難解なHTMLもChromeのXPath Helperがあればなんとか内容を追うことはできそうだ!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント