
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
PyTorchはPythonでディープラーニングのコードが簡単に書けるようになるフレームワークです。ここではディープラーニング初心者である筆者が数あるフレームワークからPyTorchを選んだ理由とインストール方法を紹介します。
こんにちは。wat(@watlablog)です。
ここではディープラーニングをこれから学ぶ僕がPyTorchを選んだ理由の説明とインストール方法までを紹介します!
ディープラーニングのフレームワークとは?
フレームワーク(Framework)とは、直訳すると「枠組み」とか「骨組み」を意味する単語ですが、コンピュータ用語では「アプリケーションプログラムに必要な一般的な機能が予め実装されたもの」という意味で使われます。
当WATLABブログではAIカテゴリで頻繁に使っているscikit-learnも機械学習のフレームワークと呼ばれます。
scikit-learnはディープラーニング以外の古典的な機械学習が得意なフレームワークです。
古典的な機械学習については「【G検定の学習】機械学習の具体的な手法や概要のまとめ」を読んで頂ければ、概要を把握することができると思いますので、是非参考にして頂ければと思います。
一方、第3次AIブームの現代で最も勢いのある深層学習(ディープラーニング)は様々なフレームワークが存在します。
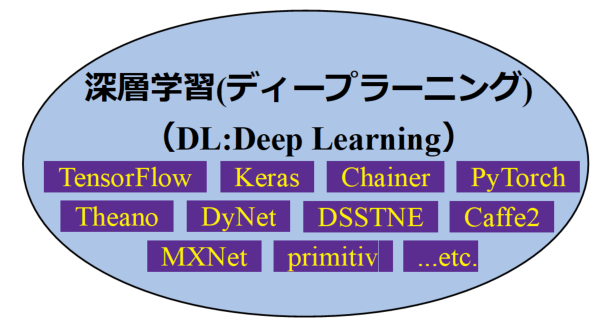
上図は現在世の中で使われているディープラーニング用のフレームワークリストですが、ここに記載されていないものあり非常に多くのフレームワークがあります。
こんなに沢山あるとどれを選んで良いかわからない!
scikit-learnやscipy, numpyを組み合わせれば、おそらくディープラーニングのアルゴリズムも自力で実装することができると思いますが、博士課程や研究者でないディープラーニングを使って結果を出したいだけの人はフレームワークを利用するのが賢い選択と考えられます。
しかし、僕のような初心者は沢山選択肢があると何から手を付けて良いかわかりません。
学び始めても他の人が離れて行ったり、理解が難しいものであったりした場合は学習コストがかかりすぎてしまうので選択が必要です。
ちょっとインターネットで調べると、どうやらPythonプログラマにとってのディープラーニングフレームワークはTensorFlow、Keras、Chainer、PyTorchという4つが特に競合しているそうです。
これらから今回はPyTorchを選んだ方が良いという結論に至ったので、その理由を説明していきます。
PyTorchを選んだ3つの理由
①PyTorchはdefine by runである
ディープラーニングとは、以下の図のようにニューロンを多層に繋げて各層の重みを更新し誤差を最小化していくアルゴリズムをとります。
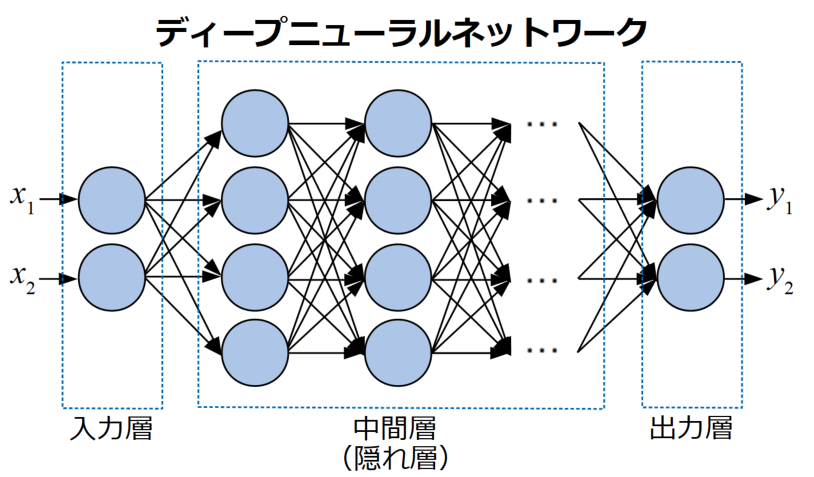
ここで、動作に関連した特徴で各フレームワークを調べていくと「define and run」と「define by run」という2つの方式があることがわかってきました。
define and runとは?
define and runとは、ニューラルネットワーク(線で繋がっていることから計算グラフとも呼ばれる)を構築してからデータを流すアルゴリズムです。
ディープラーニングフレームワークで最も有名なTensorFlow やKerasはこのdefine and run方式を採用しています。
define and run方式はネットワークを固定してからデータを流すため、最適化が容易であるメリットがありますが、データによってネットワーク自体を動的に変化させるような構造をとることができません。
コンパイルしてから流す、ということですね。
define by runとは?
一方、define by runとは、データを流しながら計算グラフを構築する方式をとるアルゴリズムです。
ディープラーニングが考案された初期は、主に画像処理を畳み込みニューラルネットワーク(CNN)で行っていましたが、じきに自然言語処理や時系列データ処理といった再帰型ニューラルネットワーク(RNN)が利用されるようなアルゴリズムが増えてきました。
ループ毎に計算グラフ構造が変化することも考慮したアルゴリズムが多いRNNではdefine by run方式の方が直感的な記述が可能になります。
そして動的な計算グラフ生成は値を見ながら動作させることが可能なので、デバッグがしやすいという大きなメリットを持ちます。
define and runがコンパイル的であるのに対し、define by runはインタプリタ的でPythonのコーディングスタイルと合っていそうですね!
define by run方式はChainerを作ったPFN(Preferred Networks社)がまず採用したとのこと。そしてFacebookがそのChainerをフォークしてPyTorchを作ったということで、ChainerとPyTorchは共にdefine by run方式です。
僕がPyTorchを選んだ理由の1つが、このdefine by run方式で最初から作られているから、です。
Chainerを選ばなかった理由は以下に続きます。
TensorFlowも2.0からeager executionというdefine by run方式を取り入れたということですが、まだ出始めたばかりで動向が読めない状態であるため保留します。
define by runは、
・動的フレームワークでRNNが直感的にかける(Python的!)
・デバッグが容易
…と、僕のような初心者にピッタリと考えられます!
②PyTorchは他よりも人気が増加傾向
以下の図はGoogleトレンドで各ディープラーニングのフレームワーク毎に検索インタレストを調べた結果です。僕は日本人であり、基本的には日本語の検索結果が沢山あったら良いなと思っているのでこの検索インタレストは日本のみの結果です(さらに縦軸は月の合計をとっています:計算方法はこちらの記事で)。
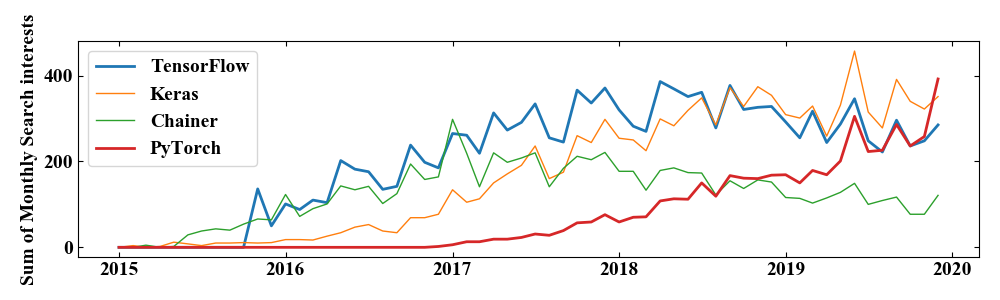
検索インタレストが必ずしも人気度や使用率を表しているわけではないと思いますが、1つの目安にはなると考えられます。
この結果は、初期はやはり開発元がGoogleであるTensorFlowが優勢であるのに対し、PyTorchがじわじわと昇ってきてついに2019年の年末には追い抜いたと読むことができます。
define by run方式を採用しているChainerが2018年から減少傾向ですが、
これには以下の影響が反映されたと考えられます。
以下の記事によると、Chainerはメジャーアップデートが終了し、PyTorchへ研究開発基盤を移すとのこと。発表が2019/12/5なので、今後ますますPyTorchは使われるフレームワークになることが予想されます。
Preferred Networks(PFN)は2019年12月5日、同社が開発する深層学習フレームワーク「Chainer」のメジャーアップデートを終了すると発表した。バグフィックスおよびメンテナンスは継続する。同社の研究開発基盤は、Chainerから米Facebookが主導する深層学習フレームワーク「PyTorch」へ順次移行する。
MONOist:https://monoist.atmarkit.co.jp/mn/articles/1912/06/news052.html
TensorFlowもdefine by runを採用しだして、さらにTensorFlow内にKerasを標準装備したとのことなので、もしかしたら今後のトレンドはさらにひと暴れありそうですが、現時点でPyTorchが最も勢いのあるフレームワークと踏んで僕はPyTorchを選択しました。
初心者は挫折しがちなので、みんなが使っているフレームワークを使って集合知で切り抜けよう!
③最先端の研究でPyTorchが使われている
上の理由とかなり近いと思われますが、世界の研究者がPyTorchを使うようになってきたという傾向もPyTorchを選ぶ理由になりました。
下の記事はThe State of Machine Learning Frameworks in 2019という英語のページですが、TensorFlowとPyTorchの比較をグラフ付きで行っています。
If you need more evidence of how fast PyTorch has gained traction in the research community, here's a graph of the raw counts of PyTorch vs. TensorFlow.
The State of Machine Learning Frameworks in 2019:https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/
この結果から、PyTorchは最新の研究でよく利用されているので、最新アルゴリズムを一般ユーザが利用できるような形で入手しやすいという事ができそうです
①define by runである
②人気上昇中である
③最新研究でも利用されている
僕はこれらの理由でPyTorchに決めました!
PyTorchをインストールする方法
公式ページがインストールコマンドを生成してくれる
PyTorchはpipインストール可能です。いつもはここにコマンドを記載するのですが、PyTorchの公式ページにローカルマシンにPyTorchをpipインストールするためのコマンドを自動生成してくれる機能があるので、以下に公式ページまでのリンクを示します。
公式ページ:PyTorch Get Start : Start Locally
環境選択の画面に、自分のPCの環境に当てはまるボタンを押すと「Run this Command:」欄にインストールコマンドが表示されます。
僕の場合はWindows環境なので、このコマンドをコマンドプロンプトで実行するだけでした。

動作チェック
それではPyTorchが正常にインストールされているか確かめてみましょう。
先ほどの公式ページに記載されている「VERIFICATION」欄のコードを以下に示します。このコードを正常に実行できれば、PyTorchは正常にインストールされています。
|
1 2 3 4 5 |
# ランダムに初期化されたテンソルを表示するコード from __future__ import print_function import torch x = torch.rand(5, 3) print(x) |
実行結果は以下のようになります。このコードはランダムに初期化したテンソルを表示させるだけのコードです。
|
1 2 3 4 5 |
tensor([[0.4307, 0.4761, 0.5571], [0.1888, 0.7246, 0.5394], [0.6189, 0.6161, 0.5275], [0.6755, 0.1699, 0.7535], [0.2198, 0.0417, 0.9071]]) |
スカラーは0階のテンソル、ベクトルは2階のテンソル…以外と既にテンソルには触れてきているんですよね。
まとめ
本ページではこれからディープラーニングをやってみようと思っている筆者が、数あるディープラーニングのフレームワークの中からPyTorchを選んだ理由をメモし、実際にインストールと動作チェックを行ってみました。
もちろん人によってはPyTorch以外のフレームワークの方が合っていたり、既に会社で使っているものがあったり、学生であれば自分で実装した方が良かったりと様々な状況があると思います。
今回の結果はあくまで初心者・初学者の文章なので参考程度にとどめておき、ご自身で使う場合の判断の1つに使って頂ければと思います。
また今回はローカルマシン(自宅のPC)にPyTorchをインストールしましたが、ディープラーニングは大量のメモリを使うらしいので、もしかしたらGoogle Colaboratory等のクラウド環境を使った方が良い場合もあるかも知れません。
その時は別途記事で紹介したいと思います。
ついにディープな世界へ足を踏み入れてしまいました!Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント