
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

csvファイルは様々なソフトで互換性が高く、データフォーマットとしての汎用性が非常に高いファイルです。ここでは文字列と数値が混合されたcsvファイルをPandasで簡単に読み込みする方法を習得します。
Pandasは異なるデータ型を同時に扱える
Pandasとは?
Pandasとは、Pythonのデータ解析用ライブラリパッケージです。
Pandasには様々な統計解析用の関数があるため、機械学習用のデータ分析や金融系の計算によく活用されています。
Pandasの大きな特徴は、データをExcelのテーブルのようにデータフレームで扱うことができることにありますが、1つのデータフレームに文字列や数値等、様々なデータ型を同時に扱えることがPandasのメリットとなります。
まるで本当にExcelみたいですね!
今回使用するcsvファイル
今回は以下の画像に示す、当WATLABブログの8月までの運営記録をcsvファイル(エンコード:SHIFT-JIS)化してプログラムの例を説明します。名前は「Report.csv」です。

このデータは1行目が日本語のヘッダーとなっており、A列は2019という年を意味する数値が2行目のみに入っています。他のデータは整数があったり小数があったりといった所ですね。
ちなみに、記事数以外の数値はGoogle AnalyticsやGoogle Search ConsoleといったGoogleのプラットフォームを使って計測をしています。そのためGoogleのみに依存した計測結果ということになりますね。
csv処理のサンプルコードは、Pandasの他に同じくcsvファイルを扱うことのできるNumPyと比較をしてみます。
NumPyとPandasを比較!csv処理のコード
NumPyの場合のcsv読み込み:np.loadtxt
NumPyは当ブログのほとんどのプログラムに使われているので、僕にとってみればお馴染みのライブラリですが、画像処理や機械学習でも使われるので世間的にもPythonのメジャーライブラリです。
NumPyのcsv読み込みコードは以下に示すように「np.loadtxt」を使います。
まずはprintでデータを表示させてみましょう。data[1, 0]はcsvファイルの「2019」という数値を取得する部分です。
|
1 2 3 4 5 |
import numpy as np data = np.loadtxt('Report.csv', delimiter=",", dtype='unicode') print(data) print(data[1,0])<br>print(type(data[1,0])) |
このコードを実行すると、以下の結果がコンソールに表示されます。
|
1 2 3 4 5 6 7 8 9 |
[['年' '月' '総記事数' '記事数' 'PV数[PV]' 'ユーザー[人]' '合計クリック数' '合計表示回数' '平均CTR[%]' '平均掲載順位'] ['2019' '4' '20' '20' '909' '92' '7' '199' '3.5' '43.9'] ['' '5' '39' '19' '1416' '278' '97' '1185' '8.2' '37.7'] ['' '6' '53' '14' '1716' '510' '236' '2193' '10.8' '23.4'] ['' '7' '67' '14' '2486' '1104' '690' '7745' '8.9' '19.9'] ['' '8' '85' '18' '3980' '1893' '1307' '17400' '7.5' '20.2']] 2019 <class 'numpy.str_'> |
NumPyでもdtype='unicode'を指定することで日本語を読めるようになります。dtypeを指定しないとデフォルトはfloatなので日本語文字列を読んだ時点でコードエラーが出ます(やってみました)。
unicodeで読んでいるので、数値も全てのデータはstr型になっていることもわかりました。
Pandasの場合のcsv読み込み:pd.readcsv
続いてPandasの場合のcsvファイルの読み込みです。Pandasの場合は「pd.read_csv」を使います。
エンコードにencodingを使っています。これでSHIFT-JISを読み込めるようにします。
この設定の場合、ファイル内の2019という数値は(0, 0)になり、data.iloc[0, 0]と指標を指定して抽出します。locを使えばラベル名、ilocを使えば指標番号で抽出することができます。
|
1 2 3 4 5 6 |
import pandas as pd data = pd.read_csv('Report.csv', encoding='SHIFT-JIS') print(data) print(data.iloc[0,0]) print(type(data.iloc[0,0])) |
上記コードを実行すると、以下の結果がコンソールに表示されます。
|
1 2 3 4 5 6 7 8 |
年 月 総記事数 記事数 PV数[PV] ユーザー[人] 合計クリック数 合計表示回数 平均CTR[%] 平均掲載順位 0 2019.0 4 20 20 909 92 7 199 3.5 43.9 1 NaN 5 39 19 1416 278 97 1185 8.2 37.7 2 NaN 6 53 14 1716 510 236 2193 10.8 23.4 3 NaN 7 67 14 2486 1104 690 7745 8.9 19.9 4 NaN 8 85 18 3980 1893 1307 17400 7.5 20.2 2019.0 <class 'numpy.float64'> |
このように、日本語はしっかり読み込めているにも関わらず、数値は数値型として認識されていることがわかりました。
さらに、何も記載がない2019という数値の下には「NaN」が割り当てられています。NaNはNot a Numberの略で、欠損値を意味します。Pandasでは自動的に欠損値の割り当てをしてくれるんですね。
Pandasでcsvを読み込んでmatplotlibでグラフ表示
全コード
それではせっかくなのでPandasで読み込んだデータをグラフ表示させてみましょう!
なんとPandasでは「MONTH = data['月']」と、ラベル名でデータを抽出することもできてしまいます。さらにそのままmatplotlibに渡してグラフ表示もできてしまうという簡単さです。
以下に全コードを示します。少々長く感じますが、ムダにグラフ表示に凝っているだけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
import pandas as pd import numpy as np from matplotlib import pyplot as plt data = pd.read_csv('Report.csv', encoding='SHIFT-JIS') MONTH = data['月'] PV = data['PV数[PV]'] USER = data['ユーザー[人]'] IMP = data['合計表示回数'] ARTICLE = data['総記事数'] # ここからグラフ描画 # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの上下左右に目盛線を付ける。 fig = plt.figure() ax1 = fig.add_subplot(221) ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') ax2 = fig.add_subplot(222) ax2.yaxis.set_ticks_position('both') ax2.xaxis.set_ticks_position('both') ax3 = fig.add_subplot(223) ax3.yaxis.set_ticks_position('both') ax3.xaxis.set_ticks_position('both') ax4 = fig.add_subplot(224) ax4.yaxis.set_ticks_position('both') ax4.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Month') ax1.set_ylabel('PV') ax2.set_xlabel('Month') ax2.set_ylabel('User') ax3.set_xlabel('Month') ax3.set_ylabel('Google Impression') ax4.set_xlabel('Month') ax4.set_ylabel('Total Article') # データの範囲と刻み目盛を明示する。 ax1.set_xticks(np.arange(0, 13, 1)) ax1.set_yticks(np.arange(0, 10000, 1000)) ax1.set_xlim(3, 9) ax1.set_ylim(0, 5000) ax2.set_xticks(np.arange(0, 13, 1)) ax2.set_yticks(np.arange(0, 10000, 1000)) ax2.set_xlim(3, 9) ax2.set_ylim(0, 3000) ax3.set_xticks(np.arange(0, 13, 1)) ax3.set_yticks(np.arange(0, 50000, 5000)) ax3.set_xlim(3, 9) ax3.set_ylim(0, 20000) ax4.set_xticks(np.arange(0, 13, 1)) ax4.set_yticks(np.arange(0, 1000, 20)) ax4.set_xlim(3, 9) ax4.set_ylim(0, 100) # データプロットの準備とともに、ラベルと線の太さ、凡例の設置を行う。 ax1.plot(MONTH, PV, label='PV', lw=1, marker="o") ax2.plot(MONTH, USER, label='User', lw=1, marker="o") ax3.plot(MONTH, IMP, label='Google Impression', lw=1, marker="o") ax4.plot(MONTH, ARTICLE, label='Total Article', lw=1, marker="o") fig.tight_layout() # グラフを表示する。 plt.show() plt.close() |
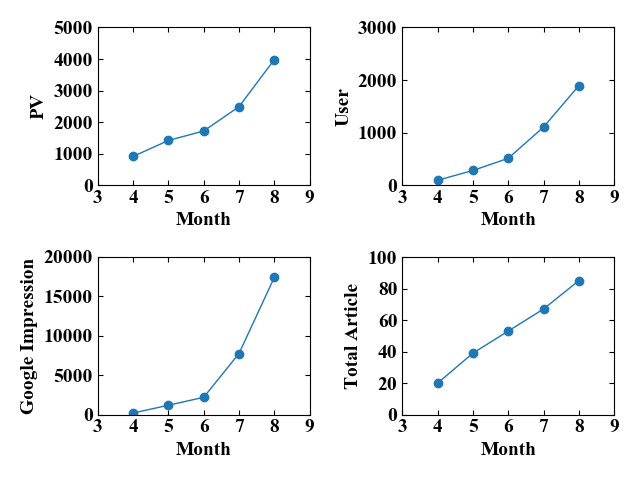
実行結果
以下が実行結果です。
ブログ運営数字が見事に可視化されました。
まとめ
本ページではPythonのデータ解析ライブラリパッケージであるPandasの概要を説明し、当ブログの運営数字を題材にグラフ表示までプログラミングしてみました。
NumPyにも良い所は多々ありますが、Pandasのデータフレームはより統計解析向けに使い勝手がよく設計されているようです。
異なるデータ型を同時に扱い、かつグラフ表示もスムーズにできることを確認しました。
今回初めてPandasを使ってみましたが、今後もお世話になりそうな使い勝手でした!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!
コメント