
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

テキストファイルは非常に汎用的で、テキストを読み込んだ後にプログラムで処理をしてから新しいファイルに保存したい場面が多くあります。ここではPythonによるテキストファイルの読み書き処理の基本をメモしておきます。
こんにちは。wat(@watlablog)です。Pythonによるテキストファイルの読み書きを学んでいきます!
本記事の目標
汎用的にテキストファイル処理をする
WATLABブログではこれまで「Python/Pandasなら文字数値混在csvも簡単読み込み!」や「ただPythonでcsvから離散フーリエ変換をするだけのコード」でカンマ区切りファイル(.csv)を処理するコードを紹介してきました。実験により得られた時間、周波数データ、項目毎に列が分割されたデータベースといった形式の場合はカンマ区切りやタブ区切りファイルが便利です。
しかしながら、テキストファイル処理の分野は幅広く、逆にcsvでは扱いにくいファイルも多くあります。
ここではより汎用的に、テキストファイルを丸ごと読み込んでから色々いじれるようになる事を目標とします。
例題のテキストファイル
この記事では以下のテキストファイルを例題とします。
某解析ソフトの入力ファイルを真似しています。業務データを持ち帰る事はコンプラ違反になるので、今回は仮想データを手入力して作成しました。
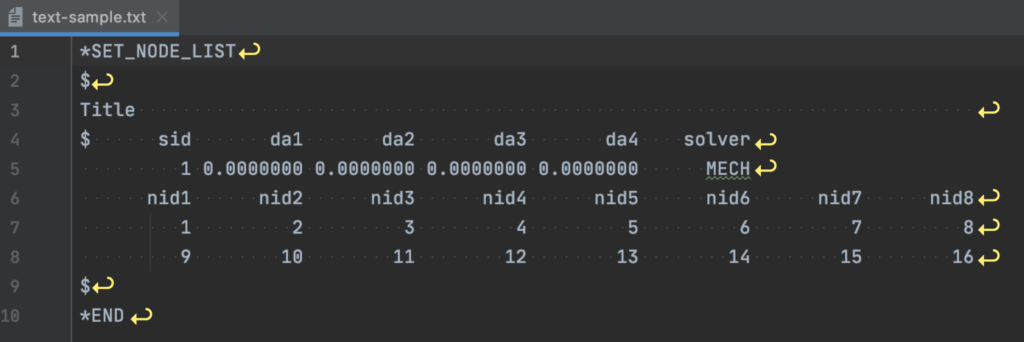
このファイルは色々な設定が「*」で始まり、ファイル最終行が「*END」で終了しています。
さらに、コメント行には「$」マークが入り、実際に使われる設定値は一定のカラム数(この設定は10文字分)ずつ格納されています。
例えば、sid1の直下にはセットID番号「1」が、nid1の直下にはNODE番号「1」がそれぞれ10文字でフォーマットされ「_________1」と入っています。
ここでは詳しい設定の意味解説までは必要ないと思いますので、ファイルの解説はこんな所で。
Pythonでテキスト読み書きをする時のメモ
動作環境
今回はPython3.9.6でやっています。
| Python | Python 3.9.6 |
|---|---|
| PyCharm (IDE) | PyCharm CE 2020.1 |
| Numpy | 1.21.1 |
ファイル読み込みコード
丸ごと読んで文字列型にする
まずは最もシンプルなテキストファイルの内容を丸ごと読む方法です。関数に引数としてファイルパスを渡し、読み込んだテキストを返す形式で書いてみました。
with構文で書く事でファイルのclose処理を自動的にしてくれます。
|
1 2 3 4 5 6 7 8 9 10 |
# テキストを丸ごと読む def open_text_all(filename): with open(filename, 'rt') as f: text = f.read() return text # ファイルを指定して実行 filename = 'text-sample.txt' text_all = open_text_all(filename) print('text_all=\n', text_all) |
結果は以下。テキストの内容が全てstr型として格納されました。
|
1 2 3 4 5 6 7 8 9 10 11 |
text_all= *SET_NODE_LIST $ Title $ sid da1 da2 da3 da4 solver 1 0.0000000 0.0000000 0.0000000 0.0000000 MECH nid1 nid2 nid3 nid4 nid5 nid6 nid7 nid8 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ *END |
1行ずつ文字列型としてリストへ格納する
次はテキストファイルを1行ずつ文字列で読み込みます。.readlines()を使えば一発です。
|
1 2 3 4 5 6 7 8 9 10 11 |
# テキストを行単位で読みリストに格納する def open_text_line(filename): with open(filename, 'rt') as f: text = f.readlines() return text # ファイルを指定して実行 filename = 'text-sample.txt' text_line = open_text_line(filename) print('text_line=\n', text_line) print('line length=', len(text_line)) |
以下のような結果になりました。改行を意味する「\n」も確認できます。
|
1 2 |
['*SET_NODE_LIST\n', '$\n', 'Title ........] line length= 10 |
先ほどの丸ごと読み込み版でも改行はされていましたが、print文として文字列で出力させたために見えなくなった(実際に改行された)と言えます。
指定行/指定文字数の抽出
特定の行を丸ごと抽出したり、文字数を指定して取り出す方法はPythonならお馴染みの以下コードで可能。
|
1 2 3 4 5 |
# 指定の行を取り出す print(text_line[0]) # 指定の文字列を取り出す print(text_line[0][:4]) |
|
1 2 3 4 5 |
# 0行目を取り出した結果 *SET_NODE_LIST # 0行目の開始4文字を取り出した結果 *SET |
ファイル書き込みコード
文字列型を丸ごと書き込む
テキストを丸ごと書き込む場合は.open()の引数に'wt'を選択し、.write()を使います。
|
1 2 3 4 5 6 7 8 9 10 11 |
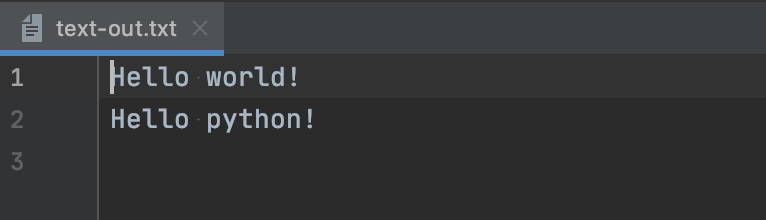
# テキストを丸ごと書き込む def write_text_all(text, filename): with open(filename, 'wt') as f: f.write(text) return # テキストを用意して書き込み text = 'Hello world!\n' \ 'Hello python!\n' filename_write = 'text-out.txt' write_text_all(text, filename_write) |
このコードでは以下のファイルが新規作成(既にあれば上書き)されます。
文字列型のリストを書き込む
リストを書き込む場合は.writelines()を使います。
|
1 2 3 4 5 6 7 8 9 10 |
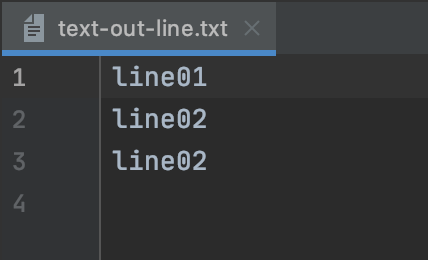
# リストで作成したテキストを書き込む def write_text_line(text, filename): with open(filename, 'wt') as f: f.writelines(text) return # テキストを用意して書き込み text = ['line01\n', 'line02\n', 'line02\n'] filename_write = 'text-out-line.txt' write_text_line(text, filename_write) |
書き込んだ結果が以下です。
まとめ
本記事ではPythonプログラミングの基本中の基本と言うべきテキストファイル処理をまとめました。
ここに記載した方法以外にもたくさんのやり方がありますが(withを使わない方法等)、使い勝手を考え個人的にわかりやすいコードを関数の形で書きました。
テキスト処理に慣れる事で簡単な業務の自動化はできるようになると思いますので、是非ご参考までに。
これまで後回しにしていたテキストの読み書きができるようになりました!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!