
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!

Kaggleを始めました!これまで古典的な機械学習手法は少し使えるようにしてきたつもりですが、KaggleではLightGBMでハイスコアを出している人が多いそうです。ここではLightGBMのインストールと使い方を学んでみます。
こんにちは。wat(@watlablog)です。ここではKaggleで人気のLightGBMの使い方を習得することを目標とします!
目標
この記事ではLightGBMという機械学習手法を実際のデータセットに対して使うことが出来る状態を目指します。
そのために、まずはLightGBMの概要を前半で把握し、後半でPython/LightGBMライブラリの使い方を習得(訓練誤差と汎化誤差を比較できるレベル)する流れとなります。
LightGBMは背景に難解な理論があるため、理論の詳細解説は別途論文を示す程度ですのでご注意下さい。
LightGBMの概要
LightGBMとは?
LightGBMとは、機械学習の決定木モデルにブースティングというアンサンブル学習を組み合わせた学習アルゴリズムです。
ちなみに、決定木モデルにバギングというアンサンブル学習を組み合わせたものはランダムフォレストと呼び、過去に「Python機械学習!ランダムフォレストの概要とsklearnコード」でも扱いましたね。
LightGBMは勾配ブースティング決定木(GDBT:Gradient Boosting Decision Tree)という手法の1つで、他にもXGBoostといったアルゴリズムもありますが、ここではMicrosoftが開発したLightGBMを紹介します。
ブースティングとは?バギングとの違い
LightGBMで使われているブースティング(Boosting)を説明する前に、まずはバギングについておさらいしましょう。
ランダムフォレストで用いられているバギングとは、複数の予測器(ここでは決定木)を並列で使い、全ての予測器の結果を総合判断して結果を出す手法でした。バギング(ここでは決定木が予測器)を図にすると、以下のようになります。
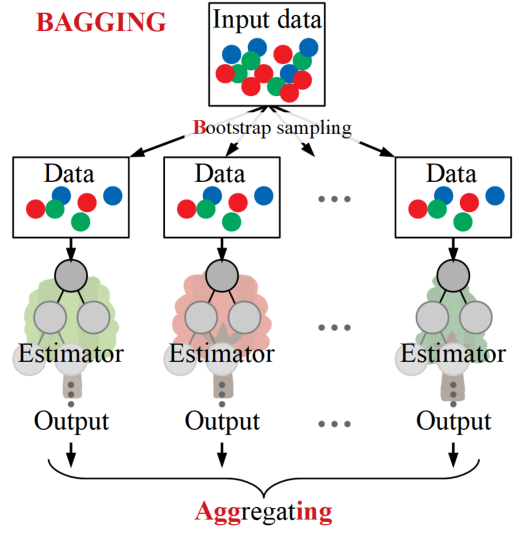
バギングは入力データからブートストラップサンプリングにより複数の予測器へデータが渡され、並列に構成されています。
一方ブースティングは以下のように直列の構造をとります。
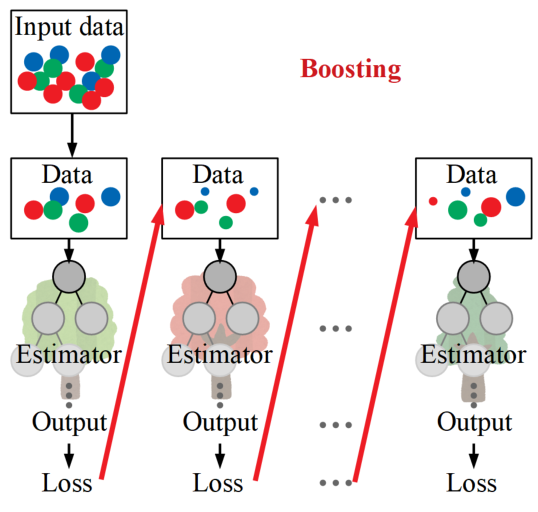
ブースティングは1つの予測器で得られたアウトプットから損失(Loss)を算出し、次の予測器の構築に利用するアルゴリズムをとります。
こうする事でより強力な予測器を得る可能性が高くなり、バギングよりも性能が上がることがあります。
しかし、直列に繋げた予測器が多ければ多いほど、後半の予測器はデータに対して過学習(オーバーフィッティング)しやすくなるため注意が必要です。
LightGBMの特徴
LightGBMの論文によると、この手法は従来のGBDTとほぼ同等の精度でありながら、最大で20倍以上の高速化が可能、さらにメモリ消費量低減というメリットがあるとのこと。
一般的にGBDTは古くから精度の良い機械学習アルゴリズムであることが知られていましたが、すべてのデータをスキャンする仕組みであるため、データサイズが大きい場合に非効率的で非常に時間がかかる問題がありました。
これを解決するために、GOSS(Gradient-based One-Side Sampling)とEFB(Exclusive Feature Bundling)を用いた新しいGBDTをMicrosoftが開発したということです。
また、計算コストは主に決定木の最適な分割点を求める学習部分にありますが、ヒストグラムを用いたデータ計量によって計算量を大幅に削減しているという特徴も持ちます。
※論文の内容が今の僕レベルでは理解が追い付かないので、以下に論文のリンクを示すのみに留めます(いずれ読めたら良いですが…)。ご興味のある方は是非論文の内容を紐解いてみて下さい。
Guolin Ke et al., LightGBM:AHighlyEfficientGradientBoosting DecisionTree,31st Conference on Neural Information Processing Systems (NIPS 2017)
LightGBMでirisデータセットの分類をするPythonコード
LightGBMのインストール
LightGBMをPythonで使うために、まずは以下のコードでpipインストールを行いましょう。
|
1 |
python -m pip install lightgbm |
importするライブラリ
それではPythonコードを書いていきます。まずはimport文を書きます。
今回インストールしたlightgbmの他に、サンプルとして使うirisデータセット(アヤメの分類に関するサンプルデータ)を使うためのscikit-learn/datasetsを、ホールドアウト法を使うためのscikit-learn/train_test_splitをimportします。
他にはデータ集計として有能なpandas、グラフプロットのためのmatplotlibを追加でimportします。
|
1 2 3 4 5 |
import lightgbm as lgb from sklearn import datasets from sklearn.model_selection import train_test_split import pandas as pd from matplotlib import pyplot as plt |
データを準備する
以下のコードはデータを用意する部分です。datasetsからirisを読み込み、訓練データ(特徴量)と教師データ(正解ラベル)を用意します。
|
1 2 3 4 |
# データを用意する iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む X = pd.DataFrame(iris.data[:, [0, 1, 2, 3]]) # 訓練データ Y = pd.Series(iris.target) # 教師データ |
ホールドアウト法でデータを分割する
データを予測する時は全データに対する誤差が小さければ良いというわけでは無く、未知のデータに対する汎化性能を高めなければ予測器として使えません。
今回はデータセット数に限りがありますので、irisのデータセットをホールドアウト法で一部を訓練データ、もう一部をテストデータとして分割します。
ホールドアウト法の使い方については「Pythonで簡単にホールドアウト法用のデータ分割をする方法」に詳細を書きましたので、是非ご覧下さい。
|
1 2 3 4 5 |
# データをホールドアウト法で分割 train_X, test_X, train_Y, test_Y = train_test_split(X, Y, # 訓練データとテストデータに分割する test_size=0.3, # テストデータの割合 shuffle=True, # シャッフルする random_state=0) # 乱数シードを固定する |
LightGBMにデータセットを登録する
lgb.Datasetを使ってLightGBMに投入するデータセットを登録します。
データは訓練用とテスト用の2種類を登録します。テストデータにはreferenceとして訓練データを設定します。
|
1 2 3 |
# データセットを登録 lgb_train = lgb.Dataset(train_X, train_Y) lgb_test = lgb.Dataset(test_X, test_Y, reference=lgb_train) |
LightGBMのハイパーパラメータを設定する
どんな機械学習手法にもハイパーパラメータ(エンジニアが事前に設定しておくべきパラメータ)があるように、LightGBMにもハイパーパラメータがあります。
全パラメータはこちらの公式ページに書いてあります。
公式リファレンス:LightGBM:https://lightgbm.readthedocs.io/en/latest/Parameters.html
…が、ありすぎですね。今回は以下の設定を行いました。
|
1 2 3 4 5 6 7 8 9 10 |
# LightGBMのハイパーパラメータを設定 params = {'task': 'train', # タスクを訓練に設定 'boosting_type': 'gbdt', # GBDTを指定 'objective': 'multiclass', # 多クラス分類を指定 'metric': {'multi_logloss'}, # 多クラス分類の損失(誤差) 'num_class': 3, # クラスの数(irisデータセットが3個のクラスなので) 'learning_rate': 0.1, # 学習率 'num_leaves': 21, # ノードの数 'min_data_in_leaf': 3, # 決定木ノードの最小データ数 'num_iteration': 100} # 予測器(決定木)の数:イタレーション |
LightGBMで学習(訓練)する
ようやく学習の開始です。学習は訓練とも呼びますが、LightGBMの訓練はlgb.trainで行います。
以下に学習部分のコードを示します。
|
1 2 3 4 5 6 7 8 |
lgb_results = {} # 学習の履歴を入れる入物 model = lgb.train(params=params, # ハイパーパラメータをセット train_set=lgb_train, # 訓練データを訓練用にセット valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定 num_boost_round=100, # 計算回数 early_stopping_rounds=10, # アーリーストッピング設定 evals_result=lgb_results) # 履歴を保存する |
ここでは後で学習中の訓練誤差と汎化誤差がどう変化していたかを確認するため、履歴をlgb_resultsに格納します。これは辞書型が必要なようです。
early_stopping_roundとは、設定した計算回数(ここでは100回)の中で、訓練誤差が低下しているのにも関わらず汎化誤差が増加していく過学習が発生した時に早期計算終了を行う設定です。
この設定が適切に機能すれば、無駄な計算をすることが無くなるため大変便利ですが、誤差が振動している場合はまだ改善の余地があるのに計算を打ち切ってしまうという間違いをしてしまう可能性が高いので、設定は慎重に行う必要があります。
結果を抽出する
最後は先に設定したlgb_resultsから訓練誤差(訓練データに対する誤差・損失関数の値)、汎化誤差(訓練に使用していないテストデータに対する誤差・損失関数の値)を抽出します。
|
1 2 3 4 |
loss_train = lgb_results['Train']['multi_logloss'] # 訓練誤差 loss_test = lgb_results['Test']['multi_logloss'] # 汎化誤差 best_iteration = model.best_iteration # 最良の予測器が得られたイタレーション数 print(best_iteration) |
ついでに、何回目の計算の時に最も汎化誤差が小さかったかを確認するために.best_iterationを確認します。
グラフ化まで含んだ全コード
以下にコピペ用の全コードを載せます。このコードは最後に訓練誤差と汎化誤差をグラフ化する部分を追加しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
import lightgbm as lgb from sklearn import datasets from sklearn.model_selection import train_test_split import pandas as pd from matplotlib import pyplot as plt # データを用意する iris = datasets.load_iris() # scikit-learnのdatasetsを読み込む X = pd.DataFrame(iris.data[:, [0, 1, 2, 3]]) # 訓練データ Y = pd.Series(iris.target) # 教師データ # データをホールドアウト法で分割 train_X, test_X, train_Y, test_Y = train_test_split(X, Y, # 訓練データとテストデータに分割する test_size=0.3, # テストデータの割合 shuffle=True, # シャッフルする random_state=0) # 乱数シードを固定する # データセットを登録 lgb_train = lgb.Dataset(train_X, train_Y) lgb_test = lgb.Dataset(test_X, test_Y, reference=lgb_train) # LightGBMのハイパーパラメータを設定 params = {'task': 'train', # タスクを訓練に設定 'boosting_type': 'gbdt', # GBDTを指定 'objective': 'multiclass', # 多クラス分類を指定 'metric': {'multi_logloss'}, # 多クラス分類の損失(誤差) 'num_class': 3, # クラスの数(irisデータセットが3個のクラスなので) 'learning_rate': 0.1, # 学習率 'num_leaves': 21, # ノードの数 'min_data_in_leaf': 3, # 決定木ノードの最小データ数 'num_iteration': 100} # 予測器(決定木)の数:イタレーション lgb_results = {} # 学習の履歴を入れる入物 model = lgb.train(params=params, # ハイパーパラメータをセット train_set=lgb_train, # 訓練データを訓練用にセット valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定 num_boost_round=100, # 計算回数 early_stopping_rounds=10, # アーリーストッピング設定 evals_result=lgb_results) # 履歴を保存する loss_train = lgb_results['Train']['multi_logloss'] # 訓練誤差 loss_test = lgb_results['Test']['multi_logloss'] # 汎化誤差 best_iteration = model.best_iteration # 最良の予測器が得られたイタレーション数 print(best_iteration) # ここからグラフ描画---------------------------------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' # グラフの入れ物を用意する。 fig = plt.figure() ax1 = fig.add_subplot(111) # グラフの上下左右に目盛線を付ける。 ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('Iteration') ax1.set_ylabel('logloss') # データプロットする。 ax1.plot(loss_train, label='train loss') ax1.plot(loss_test, label='test loss') # グラフを表示する。 plt.legend() plt.show() plt.close() |
実行結果
以下に実行結果を示します。上記コードを実行すると訓練誤差と汎化誤差が1つのグラフにプロットされます。
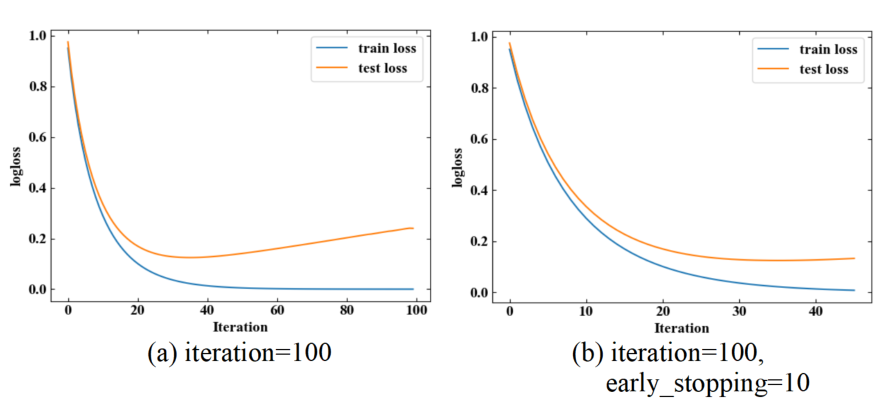
今回はearly_stopping_roundの設定有無で比較しています。early_stopping_roundが無いとiteration=40の辺りから徐々に汎化誤差が増加していく過学習が発生しています(a)が、early_stopping_round=10の場合はiteration=40ちょいの時点(b)で計算が打ち切られています。
.best_iterationとして最良モデルを確認すると、37回目のモデルがベストスコアでした。
|
1 2 3 |
Early stopping, best iteration is: [37] Train's multi_logloss: 0.0305332 Test's multi_logloss: 0.167401 37 |
まとめ
本記事では決定木に対して勾配ブースティングを使ったGBDT法を改良したLightGBMの概要を学びました。
理論的な背景の理解には難しい論文を読む必要がありますが、使う上ではなんとかなりそうです。
記事の後半ではLightGBMを使ってirisデータセットの予測器を構築し、汎化誤差が小さくなるモデルを用意することが出来ました。
まずはこのモデルをKaggleで使ってみようと思いますので、今後のKaggle記事をご期待下さい(まだ自信は無いですが…)。
Kaggleが何か、アカウントをどう作れば良いかは「Kaggleアカウントの新規作成方法!始め方までを説明」に詳細を書きましたので、是非こちらもご覧下さい。
流行りの手法であるLightGBM…完全理解にはまだまだ修行が必要ですが、まずは道具を手に入れた感じです!
Twitterでも関連情報をつぶやいているので、wat(@watlablog)のフォローお待ちしています!