
 ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
ついにWATLABブログから書籍「いきなりプログラミングPython」が発売しました!
機械学習アルゴリズムの1つ、ランダムフォレストは決定木分析とアンサンブル学習を用いた汎化性能の高い分析手法です。ここではランダムフォレストを理解するための概要説明と、Python/scikit-learnによるコード習得を目標とします。
こんにちは。wat(@watlablog)です。機械学習シリーズ!今回はランダムフォレストの概要説明を行い、scikit-learnで計算できるようになることを目指します!
ランダムフォレストの概要
ランダムフォレストとは?
ランダムフォレスト(Random Forest)とは、決定木を複数作成し、分類問題であれば多数決、回帰問題であれば平均をとって予測を行う手法です。
ランダムフォレストを理解するためには、決定木分析の理解が必要不可欠です。まだ決定木分析について曖昧な点がある方は「Python/sklearnで決定木分析!分類木の考え方とコード」に概要を書きましたので、是非読んでみて下さい。
決定木というのは以下の図のように、ある特徴量について条件分岐を繰り返して分類等の分析を行う手法でした。
この決定木は複雑な分析を行うことが可能でかつ人間が理解しやすい手法ですが、過学習(オーバーフィッティング)を起こしやすいという欠点があります。
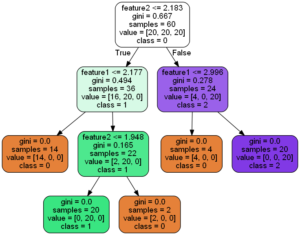
決定木の過学習しやすさを軽減し、より汎化能力を高めようと考案されたものの1つが決定木を複数作成するランダムフォレストという分析手法です。
「決定木を複数作成する」とは、以下の図のイメージです。多様性を持った多数の木から答えを1つに決定する様子はまるで民主主義のようですね。
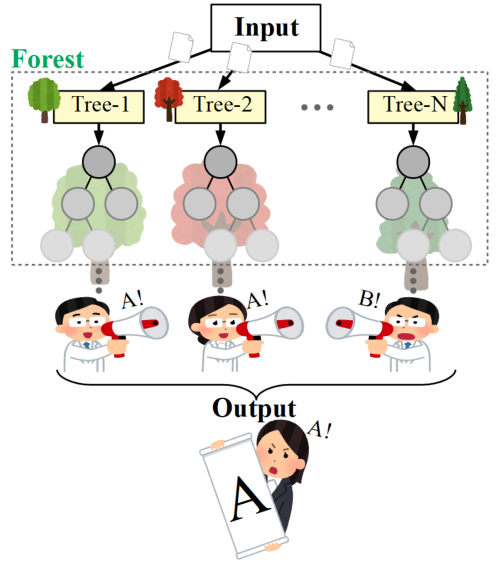
ランダムフォレスト分析は決定木をいかに複数作るかという所がキーポイントになります。
ランダムフォレストのアンサンブル学習
アンサンブル学習とは?
アンサンブル学習とは、複数のモデルを使用して結果を予測する機械学習のテクニックです。
単一の決定木モデルと異なりランダムフォレストは複数の決定木を作るため、アンサンブル学習をしていると言えます。
バギングとは?
アンサンブル学習の代表的な方法にバギングという手法があります。
バギングはデータセットからサブデータセットを抽出し、抽出したサブデータセットを再度本体に戻してから再度抽出…というブートストラップ法と呼ばれる復元抽出を繰り返して複数の学習をさせる手法です(バギング(BAGGING)は、Bootstrap AGGregatINGの略)。
データの抽出規則については様々な手法があるみたいですが、ランダムフォレストは元のトレーニング用データセットからランダムに複数の特徴量を選び、決定木の分岐ノードの条件式に使用するとのこと。
ランダムに抽出することで、多様性を高めることができ、結果として汎化性能が高くなるという狙いがあるそうです。
「ディープラーニングG検定ジェネラリスト問題集」のP66の解説に書いてあるように、「ランダムフォレストとは決定木とバギングを組み合わせた手法」と言ってしまっても良いのかな?(→本も疑うタイプなので…)
ちょっと言葉の用法が正しいか自信が無いので、実践データ分析に慣れたらこの辺を再確認します!

ランダムフォレストのハイパーパラメータ
各機械学習アルゴリズムはエンジニアが事前に値を調整しないと精度が高くならないハイパーパラメータを持ち、ランダムフォレストの場合の例外はありません。
以下にscikit-learnで調整可能なランダムフォレストの主なハイパーパラメータを示します。本当はさらに細かく沢山ありますが、個人的な主観で絞っているため、全て見たいという方は以下のscikit-learnの公式ページをご確認下さい。
公式)sklearn.ensemble.RandomForest:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
|
1 2 3 4 5 |
clf = RandomForestClassifier(n_estimators=100, # 決定木の数 criterion='gini', # 不純度評価指標の種類(ジニ係数) max_depth=3, # 木の深さ min_samples_leaf=1, # 1ノード(葉)の最小クラス数 max_features='auto') # 最大特徴量数 |
ランダムフォレストならではの設定でn_estimatorsがありますが、これは何本の決定木を作るかという設定です。デフォルトが100なので通常はそのくらい作るのでしょうか。
その他criterionは不純度評価指標のことで、デフォルトがジニ係数です。その他エントロピーもありますがこの辺りの解説は「Python/sklearnで決定木分析!分類木の考え方とコード」に記載しましたので是非ご確認下さい。
Python/scikit-learnのランダムフォレストで分類するコード
全コード
それではここから実際に手を動かしてランダムフォレストを使ってみましょう!
scikit-learnを使えば驚くほど簡単にランダムフォレストによる分析が可能です。以下にサンプルの全コードを示します。
importで「from sklearn.ensemble import RandomForestClassifier」とあるように、ランダムフォレストはアンサンブル学習の分野に入っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier from matplotlib import pyplot as plt # データを用意する------------------------------------------ df = pd.DataFrame() # データフレーム初期化 n = 20 # 1クラス毎のデータ数 for i in range(3): # データ作成ループ if i == 0: x = pd.Series(np.random.uniform(0.5, 2.8, n)) y = pd.Series(x * np.random.uniform(0.8, 1.2, n)) elif i == 1: x = pd.Series(np.random.uniform(2.2, 3.8, n)) y = pd.Series(np.random.uniform(0.5, 1.8, n)) else: x = pd.Series(np.random.uniform(3.2, 3.8, n)) y = pd.Series(np.random.uniform(2.2, 3.8, n)) label = pd.Series(np.full(n, i)) # ラベル(クラス)を作成 temp_df = pd.DataFrame(np.c_[x, y, label]) # クラス毎のデータフレームを作成 df = pd.concat([df, temp_df]) # 作成されたクラス毎のデータを逐次結合 df.index = np.arange(0, len(df), 1) # index(行ラベル)を初期化 # クラス毎のデータフレームに分離(プロット用) class_0 = df[df[2] == 0] # ラベル0を抽出 class_1 = df[df[2] == 1] # ラベル1を抽出 class_2 = df[df[2] == 2] # ラベル2を抽出 # ---------------------------------------------------------- # 学習させる値(訓練データ)とクラス(正解ラベル)に分離 data = df[[0, 1]] # 訓練データ data_class = pd.Series(df[2]) # 正解ラベル # 決定木による学習 clf = RandomForestClassifier(n_estimators=100, # 決定木の数 criterion='gini', # 不純度評価指標の種類(ジニ係数) max_depth=3, # 木の深さ min_samples_leaf=1, # 1ノード(葉)の最小クラス数 max_features='auto') # 最大特徴量数 clf.fit(data, data_class) # フィッティング r2 = clf.score(data, data_class) # 決定係数を算出 # 決定境界可視化用 grid_line = np.arange(-10, 10, 0.05) # グリッドデータのための配列を生成 X, Y = np.meshgrid(grid_line, grid_line) # グリッドを作成 Z = clf.predict(np.array([X.ravel(), Y.ravel()]).T) # .predictが使えるデータshapeに変換して予測 Z = Z.reshape(X.shape) # 3Dプロットするためにshapeを再変換 # ここからグラフ描画---------------------------------------- # フォントの種類とサイズを設定する。 plt.rcParams['font.size'] = 14 plt.rcParams['font.family'] = 'Times New Roman' # 目盛を内側にする。 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' fig = plt.figure() ax1 = plt.subplot(111) # グラフの上下左右に目盛線を付ける。 ax1.yaxis.set_ticks_position('both') ax1.xaxis.set_ticks_position('both') # 軸のラベルを設定する。 ax1.set_xlabel('x') ax1.set_ylabel('y') # スケールの設定をする。 ax1.set_xlim(0, 4) ax1.set_ylim(0, 4) # データプロットする。 ax1.contourf(X, Y, Z, cmap='coolwarm') ax1.scatter(class_0[0], class_0[1], label='class=0', edgecolors='black') ax1.scatter(class_1[0], class_1[1], label='class=1', edgecolors='black') ax1.scatter(class_2[0], class_2[1], label='class=2', edgecolors='black') plt.text(0.5, 2.2, '$\ R^{2}=$' + str(round(r2, 2)), fontsize=20) plt.legend() # グラフを表示する。 plt.show() plt.close() # ---------------------------------------------------------- |
当ブログの恒例として、サンプルのトレーニングデータ生成(わざわざPandas形式で作ってみたり)している部分やグラフ表示部分が長いですが、ランダムフォレストによる分類部分はほんのちょっとです。
使い方も他のscikit-learn機械学習アルゴリズムと全く同じなので、各アルゴリズムでデータフォーマットを区別する必要もなく簡単に使えてしまえます。
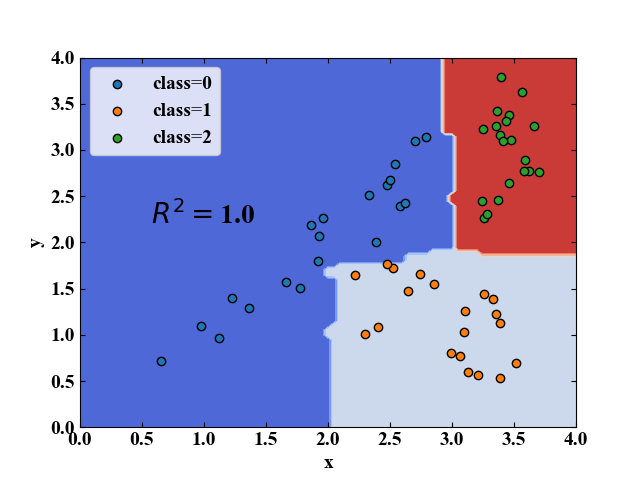
実行結果
上記コードを実行すると以下の結果を得ます。決定境界を見ると、決定木の特徴としてかなり非線形な線が得られました。このような分類が可能な分類器でさらに汎化性能が高くなる条件が出せれば、強力な道具として使えそうですね。
まとめ
本記事では機械学習アルゴリズムの1つであるランダムフォレストについて概要を記載しました。
基本的な分類アルゴリズムは決定木なので大部分は前回の決定木の記事を参照頂ければと思います。
特にランダムフォレストのキーワードはアンサンブル学習で、バギングの際にサブデータセットをランダムに選ぶ所に特徴があります。
ハイパーパラメータもイメージしやすく、今後様々なデータに対してどう効いてくるのかを試せたらと思います。
ついにアンサンブル学習を学び始めました!詳細は専門書を購入して読んだ方がよさそうですが、なんとなくのイメージは掴めたと思います!
コメント